| .. | ||
| app | ||
| gradle/wrapper | ||
| build.gradle | ||
| gradle.properties | ||
| gradlew | ||
| gradlew.bat | ||
| local.properties | ||
| README_cn.md | ||
| README.md | ||
| settings.gradle | ||
2D Virtual Human
Recently, the concept of the metaverse has become increasingly popular. Virtual human technology is an important component of it. The principle is to capture the person's face through video and synchronize the facial movements to the character. People only need a camera to create a vivid and lively virtual image.
Virtual Digital Human
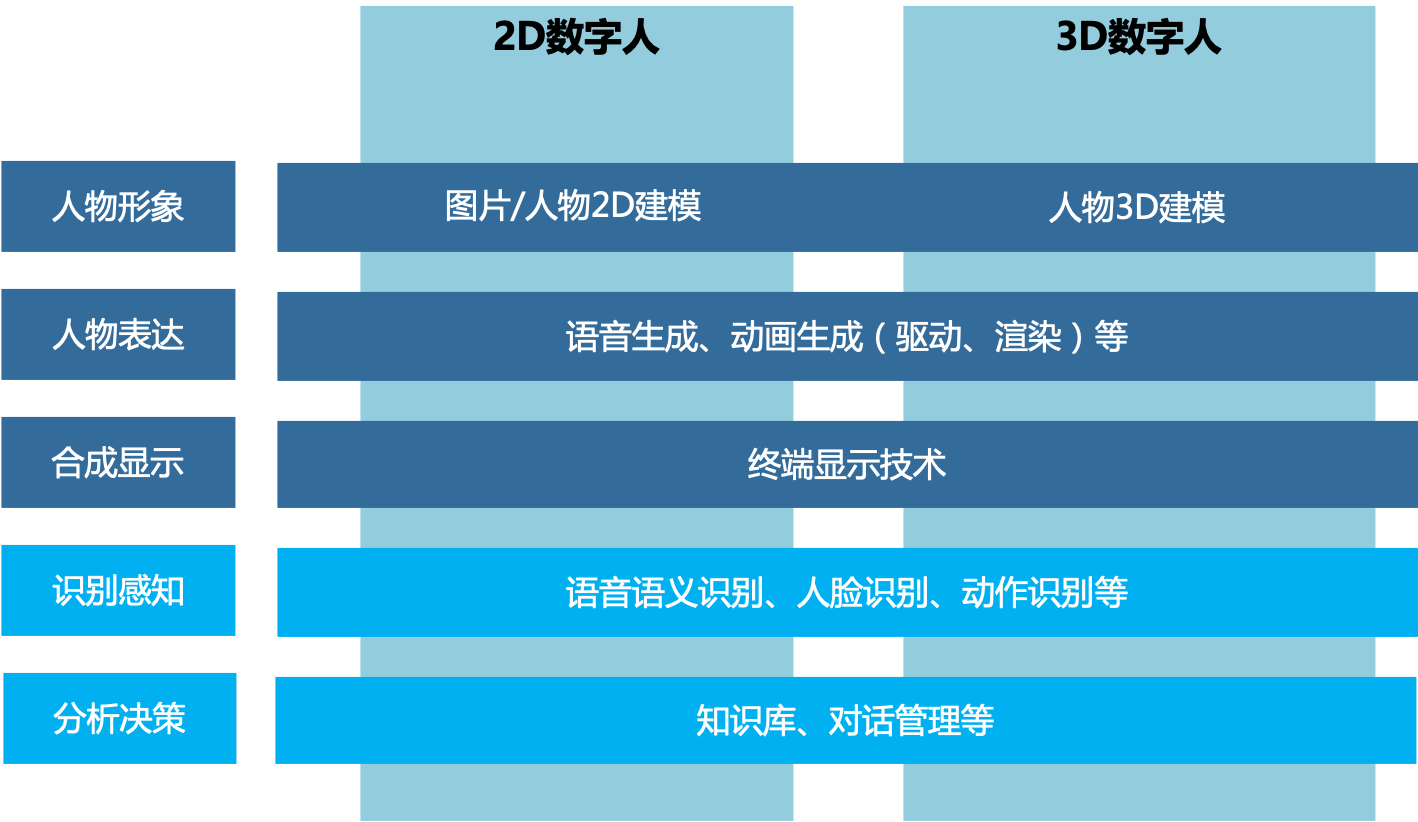
The virtual digital human system generally consists of 5 modules: character image, speech generation, animation generation, audiovisual synthesis and display, and interaction:
- Depending on the dimension of the character graphics resources, the character image can be divided into 2D and 3D, and can be further divided into cartoon, humanoid, realistic, hyper-realistic, and other styles;
- The speech generation module and animation generation module can respectively generate the corresponding character speech and matching character animation based on the generated text;
- The audiovisual synthesis and display module synthesizes the speech and animation into a video, and then displays it to the user;
- The interaction module enables the digital human to have interactive functions, that is, to recognize the user's intentions through intelligent technology such as speech semantic recognition, and determine the digital human's subsequent speech and actions according to the user's current intentions, driving the character to open the next round of interaction.
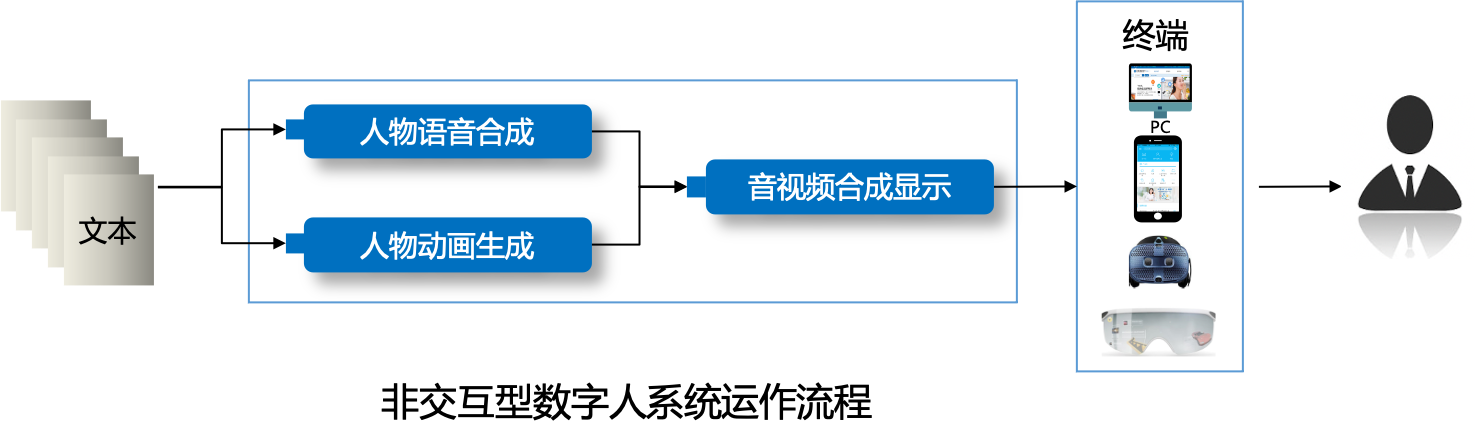
Interaction Module
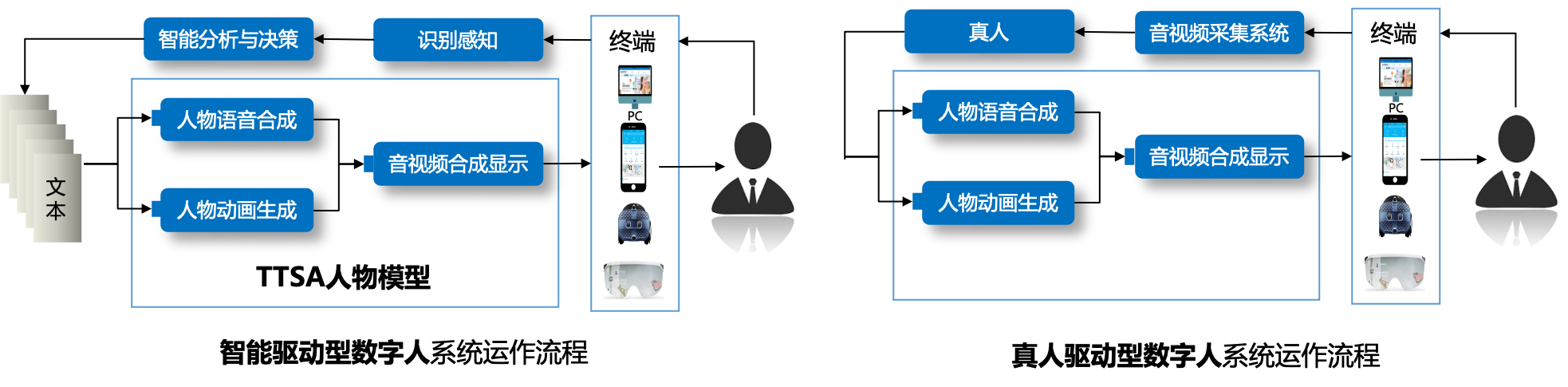
The interaction module is an extension item. Depending on its presence or absence, digital humans can be divided into interactive digital humans and non-interactive digital humans. Interactive digital humans can be divided into intelligent driving type and real person driving type according to the driving method.
- Intelligent driving digital humans can automatically read and parse external input information through the intelligent system, decide the output text of the digital human based on the parsing result, and then drive the character model to generate corresponding speech and action to interact with the user. The model that generates speech and corresponding animation from text is called the TTSA (Text To Speech & Animation) character model in the industry.
- The real person driving digital human is driven by a real person. The main principle is that the real person presents the user's real-time video and voice through the video capture system, and presents the real person's expression and action on the virtual digital human image through the motion capture system, thereby interacting with the user.
Currently, the app can only support 2D effects and only track facial expressions. To have a complete and realistic virtual image, 3D technology support is also needed. (This demo uses an old version of the Live2D SDK, it is recommended to upgrade and adapt to the latest version of the SDK)
Effect Pictures:
