| .. | ||
| lib | ||
| models | ||
| src | ||
| pom.xml | ||
| README_cn.md | ||
| README.md | ||
| tacotron2_sdk.iml | ||
Download the model and place it in the models directory
- Link 1: https://github.com/mymagicpower/AIAS/releases/download/apps/speakerEncoder.zip
- Link 2: https://github.com/mymagicpower/AIAS/releases/download/apps/tacotron2.zip
Model generates text based on the target voice's mel-spectrogram
Voice cloning refers to using a specific voice to synthesize audio based on the pronunciation of text, so that the synthesized audio has the characteristics of the target speaker, thus achieving the purpose of cloning. When training the speech cloning model, the target voice is used as the input of the Speaker Encoder. The model extracts the speaker characteristics (voice) of this speech as the Speaker Embedding. Then, when training the model to resynthesize such a voice, in addition to the input target text, the speaker's characteristics will also be added as an additional condition to the model training. During prediction, a new target voice is selected as the input of the Speaker Encoder, and its speaker characteristics are extracted. Finally, the model generates a speech fragment of the target voice speaking the given text. Google's team proposed a text-to-speech neural system that can learn the speech characteristics of multiple different speakers through a small amount of samples and synthesize their speech audio. In addition, for speakers that the network has not encountered during training, it can also synthesize their speech audio by only using a few seconds of audio from the unknown speaker, i.e., the network has zero-shot learning ability. Traditional natural speech synthesis systems require a large amount of high-quality samples during training. Usually, for each speaker, hundreds or thousands of minutes of training data are required. This makes the model usually not universal and cannot be applied on a large scale in complex environments (with many different speakers). These networks mix the processes of speech modeling and speech synthesis into one. The SV2TTS work first separates these two processes and models the speaker's voice characteristics through the first speech feature encoding network (encoder), and then completes the feature-to-speech conversion using the second high-quality TTS network based on Tacotron 2.
-
SV2TTS paper Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
-
Network structure

It mainly consists of three parts: -Speaker feature encoder Extracts speaker voice feature information. Embeds the speaker's voice into a fixed-dimensional vector, which represents the speaker's potential voice features. -Sequence-to-sequence mapping synthesis network Based on Tacotron 2's mapping network, generates the log mel-spectrogram from the text and the vector obtained from the speaker feature encoder. The mel-spectrogram takes the logarithm of the frequency scale Hz of the spectrogram and converts it to the mel scale, linearly positively correlated with the sensitivity of the human ear to sound. -Autoregressive speech synthesis network based on WaveNet Converts the mel-spectrogram (spectral domain) to a time-series audio waveform graph (temporal domain) to complete speech synthesis. It should be noted that these three networks are trained independently, and the voice encoder network mainly serves as conditional supervision for the sequence mapping network to ensure that the generated speech has the unique voice characteristics of the speaker.
Sequence-to-sequence mapping synthesis network
This network is trained independently of the encoder network. It takes audio signals and corresponding text as input, and the audio signals are first extracted by the pre-trained encoder to obtain features, and then used as input to the attention layer. The network output features are composed of sequences with a window length of 50ms and a step size of 12.5ms. After mel-scale filtering and logarithmic dynamic range compression, the mel-spectrogram is obtained. To reduce the influence of noise data, L1 regularization is added to the loss function of this part.
The comparison of input mel-spectrogram and synthesized mel-spectrogram is shown below:
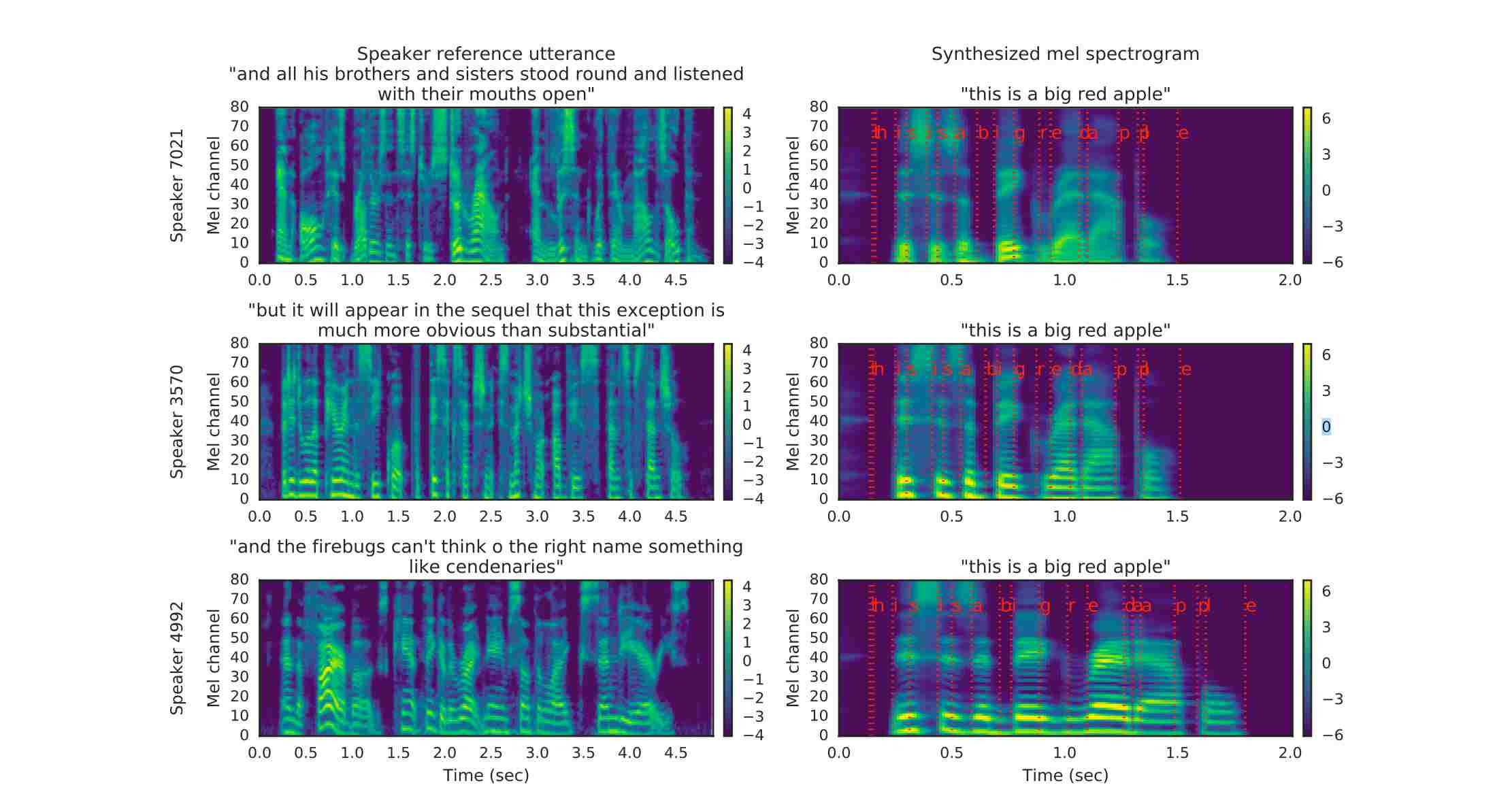 The red line in the right figure represents the correspondence between text and spectrogram. It can be seen that the reference-supervised speech signal used does not need to be consistent with the target speech signal in the text, which is also a major feature of the SV2TTS paper work.
The red line in the right figure represents the correspondence between text and spectrogram. It can be seen that the reference-supervised speech signal used does not need to be consistent with the target speech signal in the text, which is also a major feature of the SV2TTS paper work.
Running Example - Tacotron2EncoderExample
After successful execution, the command line should display the following information:
...
[INFO ] - Text: Convert text to mel-spectrogram based on the given voice
[INFO ] - Given voice: src/test/resources/biaobei-009502.mp3
# Generate feature vector:
[INFO ] - Speaker Embedding Shape: [256]
[INFO ] - Speaker Embedding: [0.06272025, 0.0, 0.24136968, ..., 0.027405139, 0.0, 0.07339379, 0.0]
[INFO ] - Mel-spectrogram data Shape: [80, 331]
[INFO ] - Mel-spectrogram data: [-6.739388, -6.266942, -5.752069, ..., -10.643405, -10.558134, -10.5380535]