mirror of
https://gitee.com/mymagicpower/AIAS.git
synced 2024-11-29 18:58:16 +08:00
| .. | ||
| ocr_backend | ||
| ocr_ui | ||
| README_EN.md | ||
| README.md | ||
| Ubuntu配置java与nginx_V0.2.pdf | ||
| windows nginx配置参考文档.docx | ||
目录:
下载模型, 更新配置yml文件 ocr_backend\src\main\resources\application-xxx.yml
model:
# 设置为 CPU 核心数 (Core Number)
poolSize: 4
table:
# 表格数据集训练的版面分析模型,支持中英文文档表格区域的检测
layout: D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\picodet_lcnet_x1_0_fgd_layout_table_infer_onnx.zip
# 英文表格识别
rec: D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\en_ppstructure_mobile_v2.0_SLANet_infer.zip
# 中文表格识别
# D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\ch_ppstructure_mobile_v2.0_SLANet_infer.zip
ocrv4:
# server detection model URI
det: D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\ch_PP-OCRv4_det_infer.zip
# server recognition model URI
rec: D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\ch_PP-OCRv4_rec_infer.zip
mlsd:
# mlsd model URI
model: D:\\ai_projects\\AIAS\\6_web_app\\ocr_web_app\\ocr_backend\\models\\mlsd_traced_model_onnx.zip
OCR Web应用
文字识别(OCR)目前在多个行业中得到了广泛应用,比如金融行业的单据识别输入,餐饮行业中的发票识别, 交通领域的车票识别,企业中各种表单识别,以及日常工作生活中常用的身份证,驾驶证,护照识别等等。 OCR(文字识别)是目前常用的一种AI能力。
当前版本包含了下面功能:
- 自由文本识别(支持旋转、倾斜的图片)
- 文本图片转正 (一般情况下不需要,因为ocr 原生支持旋转、倾斜的图片 )
- 表格文本识别(图片需是剪切好的单表格图片)
- 表格自动检测文本识别(支持表格文字混编,自动检测表格识别文字,支持多表格)
1. 前端部署
1.1 直接运行:
npm run dev
1.2 构建dist安装包:
npm run build:prod
1.3 nginx部署运行(mac环境部署管理前端为例):
cd /usr/local/etc/nginx/
vi /usr/local/etc/nginx/nginx.conf
# 编辑nginx.conf
server {
listen 8080;
server_name localhost;
location / {
root /Users/calvin/ocr_ui/dist/;
index index.html index.htm;
}
......
# 重新加载配置:
sudo nginx -s reload
# 部署应用后,重启:
cd /usr/local/Cellar/nginx/1.19.6/bin
# 快速停止
sudo nginx -s stop
# 启动
sudo nginx
2. 后端部署
2.1 环境要求:
- 系统JDK 1.8+,建议11
2.2 下载模型:
### 模型下载地址:
链接:https://pan.baidu.com/s/1-OEOcYHjSeqbfu7XD3ASgw?pwd=f43t
### 假设系统为linux,假设路径如下:
/home/models/ocr/
2.3 更新模型地址:
### 配置文件路径:
ocr\ocr_backend\src\main\resources
### 选择系统配置文件,替换成实际的模型路径,以linux为例:
model:
......
table:
# 表格数据集训练的版面分析模型,支持中英文文档表格区域的检测
layout: /home/models/iocr/picodet_lcnet_x1_0_fgd_layout_table_infer_onnx.zip
# 英文表格识别
rec: /home/models/iocr/en_ppstructure_mobile_v2.0_SLANet_infer.zip
# 中文表格识别
# rec: /home/models/iocr/ch_ppstructure_mobile_v2.0_SLANet_infer.zip
ocrv4:
# server detection model URI
det: /home/models/iocr/ch_PP-OCRv4_det_infer.zip
# server recognition model URI
rec: /home/models/iocr/ch_PP-OCRv4_rec_infer.zip
2.4 其它模型加载方式,参考下面的文档:
- 模型加载方式(在线自动加载,及本地配置):
- https://aias.top/AIAS/guides/load_model.html
3. 运行程序:
运行编译后的jar:
# 运行程序
# -Dfile.encoding=utf-8 参数可以解决操作系统默认编码导致的中文乱码问题
nohup java -Dfile.encoding=utf-8 -jar xxxxx.jar > log.txt 2>&1 &
4. 打开浏览器
- 输入地址: http://localhost:8089
1. 通用文本识别

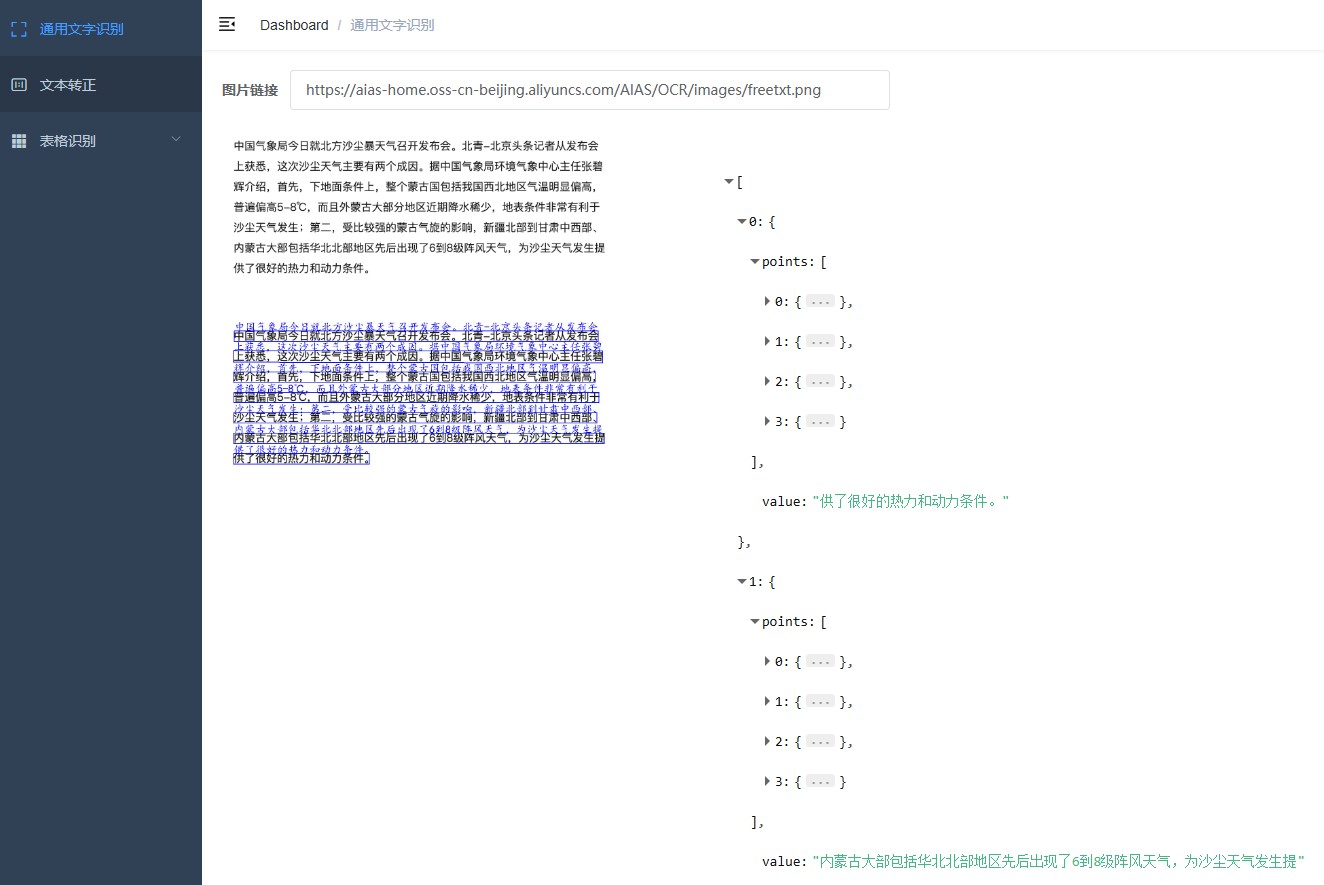
2. 文本转正
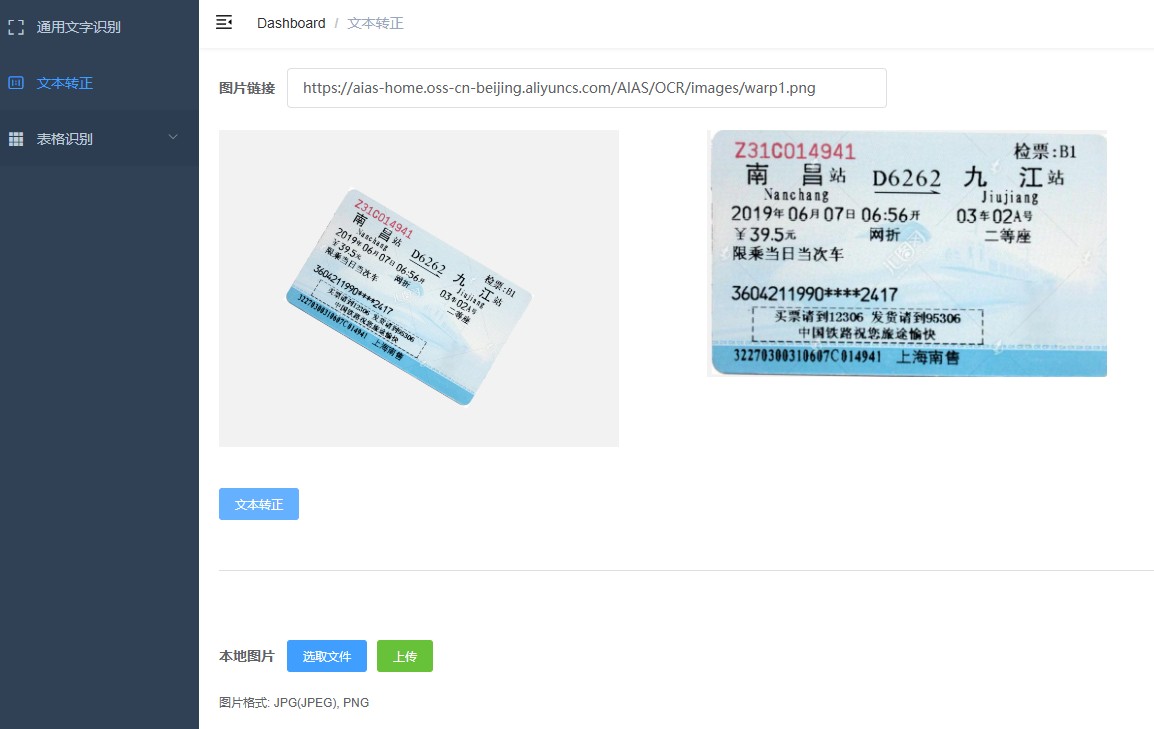
3. 中英文表格文字识别


帮助文档:
- https://aias.top/guides.html
- 1.性能优化常见问题:
- https://aias.top/AIAS/guides/performance.html
- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
- https://aias.top/AIAS/guides/engine_config.html
- 3.模型加载方式(在线自动加载,及本地配置):
- https://aias.top/AIAS/guides/load_model.html
- 4.Windows环境常见问题:
- https://aias.top/AIAS/guides/windows.html