| .. | ||
| lib | ||
| src | ||
| pom.xml | ||
| README.md | ||
| sv2tts_speakencoder_sdk.iml | ||
音特征编码器提取特征向量
Google 团队提出了一种文本语音合成(text to speech)神经系统,能通过少量样本学习到多个不同说话者(speaker)的语音特征, 并合成他们的讲话音频。此外,对于训练时网络没有接触过的说话者,也能在不重新训练的情况下, 仅通过未知说话者数秒的音频来合成其讲话音频,即网络具有零样本学习能力。 传统的自然语音合成系统在训练时需要大量的高质量样本,通常对每个说话者,都需要成百上千分钟的训练数据,这使得模型通常不具有普适性, 不能大规模应用到复杂环境(有许多不同的说话者)。而这些网络都是将语音建模和语音合成两个过程混合在一起。 SV2TTS工作首先将这两个过程分开,通过第一个语音特征编码网络(encoder)建模说话者的语音特征,接着通过第二个高质量的TTS网络完成特征到语音的转换。

主要由三部分构成:
- 声音特征编码器(speaker encoder) 提取说话者的声音特征信息。将说话者的语音嵌入编码为固定维度的向量,该向量表示了说话者的声音潜在特征。
- 序列到序列的映射合成网络 基于Tacotron 2的映射网络,通过文本和声音特征编码器得到的向量来生成对数梅尔频谱图(log mel spectrogram)。 (梅尔光谱图将谱图的频率标度Hz取对数,转换为梅尔标度,使得人耳对声音的敏感度与梅尔标度承线性正相关关系)
- 基于WaveNet的自回归语音合成网络 将梅尔频谱图(谱域)转化为时间序列声音波形图(时域),完成语音的合成。 需要注意的是,这三部分网络都是独立训练的,声音编码器网络主要对序列映射网络起到条件监督作用,保证生成的语音具有说话者的独特声音特征。
声音特征编码器
编码器主要将参考语音信号嵌入编码到固定维度的向量空间,并以此为监督,使映射网络能生成具有相同特征的原始声音信号(梅尔频谱图)。
编码器的关键作用在于相似性度量,对于同一说话者的不同语音,其在嵌入向量空间中的向量距离(余弦夹角)应该尽可能小,而对不同说话者应该尽可能大。
此外,编码器还应具有抗噪能力和鲁棒性,能够不受具体语音内容和背景噪声的影响,提取出说话者声音的潜在特征信息。
这些要求和语音识别模型(speaker-discriminative)的要求不谋而合,因此可以进行迁移学习。
编码器主要由三层LSTM构成,输入是40通道数的对数梅尔频谱图,最后一层最后一帧cell对应的输出经过L2正则化处理后,即得到整个序列的嵌入向量表示。
实际推理时,任意长度的输入语音信号都会被800ms的窗口分割为多段,每段得到一个输出,最后将所有输出平均叠加,得到最终的嵌入向量。
这种方法和短时傅里叶变换(STFT)非常相似。
生成的嵌入空间向量可视化如下图:
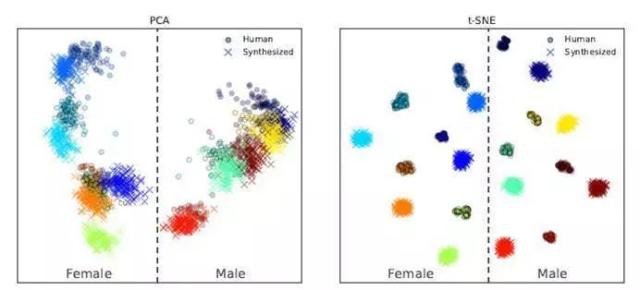
可以看到不同的说话者在嵌入空间中对应不同的聚类范围,可以轻易区分,并且不同性别的说话者分别位于两侧。 (然而合成语音和真实语音也比较容易区分开,合成语音离聚类中心的距离更远。这说明合成语音的真实度还不够。)
运行例子 - SpeakerEncoderExample
运行成功后,命令行应该看到下面的信息:
...
# 测试语音文件:
# src/test/resources/biaobei-009502.mp3
# 生成特征向量:
[INFO ] - embeddings shape: [256]
[INFO ] - embeddings: [0.06272025, 0.0, 0.24136968, ..., 0.035975248, 0.0, 0.106041126, 0.027405139, 0.0, 0.07339379, 0.0]
帮助
引擎定制化配置,可以提升首次运行的引擎下载速度,解决外网无法访问或者带宽过低的问题。
引擎定制化配置