 -
-
-
-
-  -
-
-  -
-
-  -
-
-  -
-
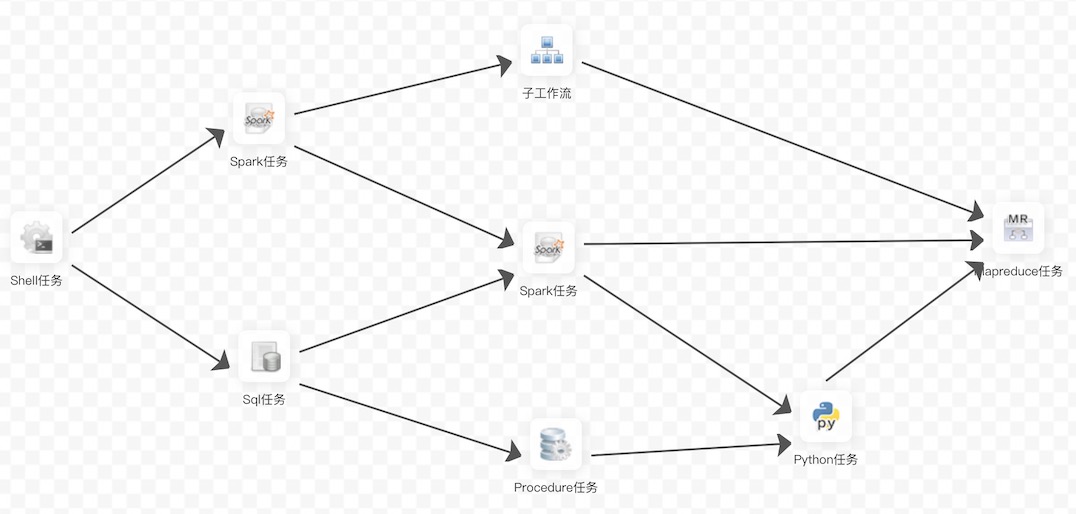
- dag example -
- - -**Process definition**: Visualization **DAG** by dragging task nodes and establishing associations of task nodes - -**Process instance**: A process instance is an instantiation of a process definition, which can be generated by manual startup or scheduling. The process definition runs once, a new process instance is generated - -**Task instance**: A task instance is the instantiation of a specific task node when a process instance runs, which indicates the specific task execution status - -**Task type**: Currently supports SHELL, SQL, SUB_PROCESS (sub-process), PROCEDURE, MR, SPARK, PYTHON, DEPENDENT (dependency), and plans to support dynamic plug-in extension, note: the sub-**SUB_PROCESS** is also A separate process definition that can be launched separately - -**Schedule mode** : The system supports timing schedule and manual schedule based on cron expressions. Command type support: start workflow, start execution from current node, resume fault-tolerant workflow, resume pause process, start execution from failed node, complement, timer, rerun, pause, stop, resume waiting thread. Where **recovers the fault-tolerant workflow** and **restores the waiting thread** The two command types are used by the scheduling internal control and cannot be called externally - -**Timed schedule**: The system uses **quartz** distributed scheduler and supports the generation of cron expression visualization - -**Dependency**: The system does not only support **DAG** Simple dependencies between predecessors and successor nodes, but also provides **task dependencies** nodes, support for custom task dependencies between processes** - -**Priority**: Supports the priority of process instances and task instances. If the process instance and task instance priority are not set, the default is first in, first out. - -**Mail Alert**: Support **SQL Task** Query Result Email Send, Process Instance Run Result Email Alert and Fault Tolerant Alert Notification - -**Failure policy**: For tasks running in parallel, if there are tasks that fail, two failure policy processing methods are provided. **Continue** means that the status of the task is run in parallel until the end of the process failure. **End** means that once a failed task is found, Kill also drops the running parallel task and the process ends. - -**Complement**: Complement historical data, support ** interval parallel and serial ** two complement methods - - - -### 2.System architecture - -#### 2.1 System Architecture Diagram -
-  -
-
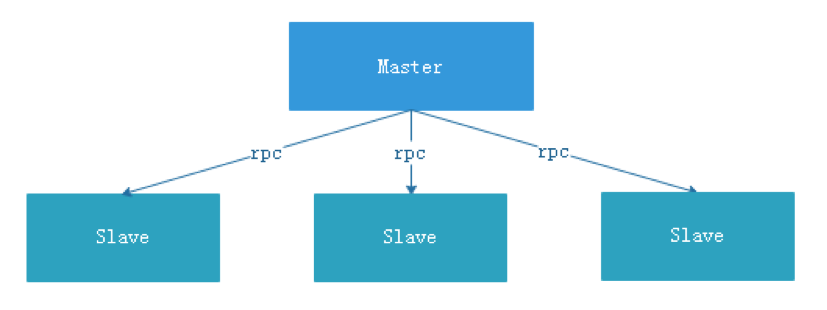
- System Architecture Diagram -
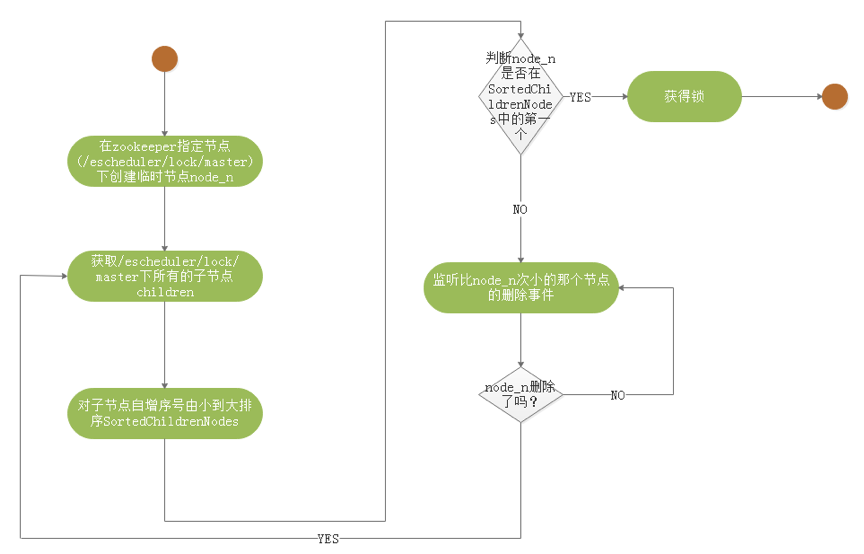
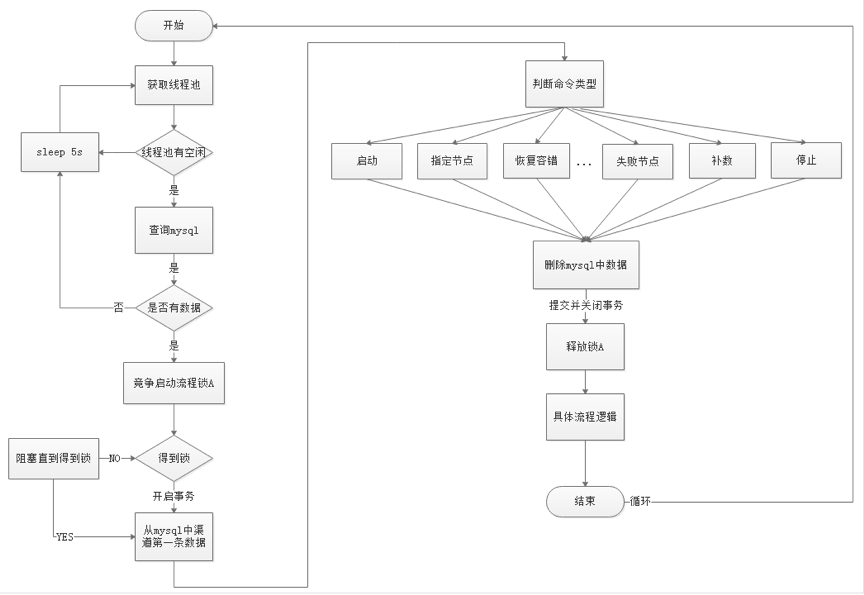
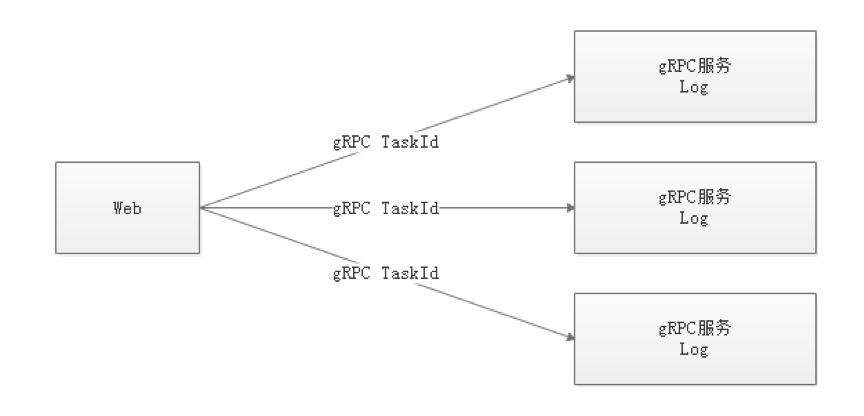
- - - - -#### 2.2 Architectural description - -* **MasterServer** - - MasterServer adopts the distributed non-central design concept. MasterServer is mainly responsible for DAG task split, task submission monitoring, and monitoring the health status of other MasterServer and WorkerServer. - When the MasterServer service starts, it registers a temporary node with Zookeeper, and listens to the Zookeeper temporary node state change for fault tolerance processing. - - - - ##### The service mainly contains: - - - **Distributed Quartz** distributed scheduling component, mainly responsible for the start and stop operation of the scheduled task. When the quartz picks up the task, the master internally has a thread pool to be responsible for the subsequent operations of the task. - - - **MasterSchedulerThread** is a scan thread that periodically scans the **command** table in the database for different business operations based on different ** command types** - - - **MasterExecThread** is mainly responsible for DAG task segmentation, task submission monitoring, logic processing of various command types - - - **MasterTaskExecThread** is mainly responsible for task persistence - - - -* **WorkerServer** - - - WorkerServer also adopts a distributed, non-central design concept. WorkerServer is mainly responsible for task execution and providing log services. When the WorkerServer service starts, it registers the temporary node with Zookeeper and maintains the heartbeat. - - ##### This service contains: - - - **FetchTaskThread** is mainly responsible for continuously receiving tasks from **Task Queue** and calling **TaskScheduleThread** corresponding executors according to different task types. - - **LoggerServer** is an RPC service that provides functions such as log fragment viewing, refresh and download. - - - **ZooKeeper** - - The ZooKeeper service, the MasterServer and the WorkerServer nodes in the system all use the ZooKeeper for cluster management and fault tolerance. In addition, the system also performs event monitoring and distributed locking based on ZooKeeper. - We have also implemented queues based on Redis, but we hope that EasyScheduler relies on as few components as possible, so we finally removed the Redis implementation. - - - **Task Queue** - - The task queue operation is provided. Currently, the queue is also implemented based on Zookeeper. Since there is less information stored in the queue, there is no need to worry about too much data in the queue. In fact, we have over-measured a million-level data storage queue, which has no effect on system stability and performance. - - - **Alert** - - Provides alarm-related interfaces. The interfaces mainly include **Alarms**. The storage, query, and notification functions of the two types of alarm data. The notification function has two types: **mail notification** and **SNMP (not yet implemented)**. - - - **API** - - The API interface layer is mainly responsible for processing requests from the front-end UI layer. The service provides a RESTful api to provide request services externally. - Interfaces include workflow creation, definition, query, modification, release, offline, manual start, stop, pause, resume, start execution from this node, and more. - - - **UI** - - The front-end page of the system provides various visual operation interfaces of the system. For details, see the **[System User Manual] (System User Manual.md)** section. - - - -#### 2.3 Architectural Design Ideas - -##### I. Decentralized vs centralization - -###### Centralization Thought - -The centralized design concept is relatively simple. The nodes in the distributed cluster are divided into two roles according to their roles: - -
-  -
-
-  -
-
-  -
-
- 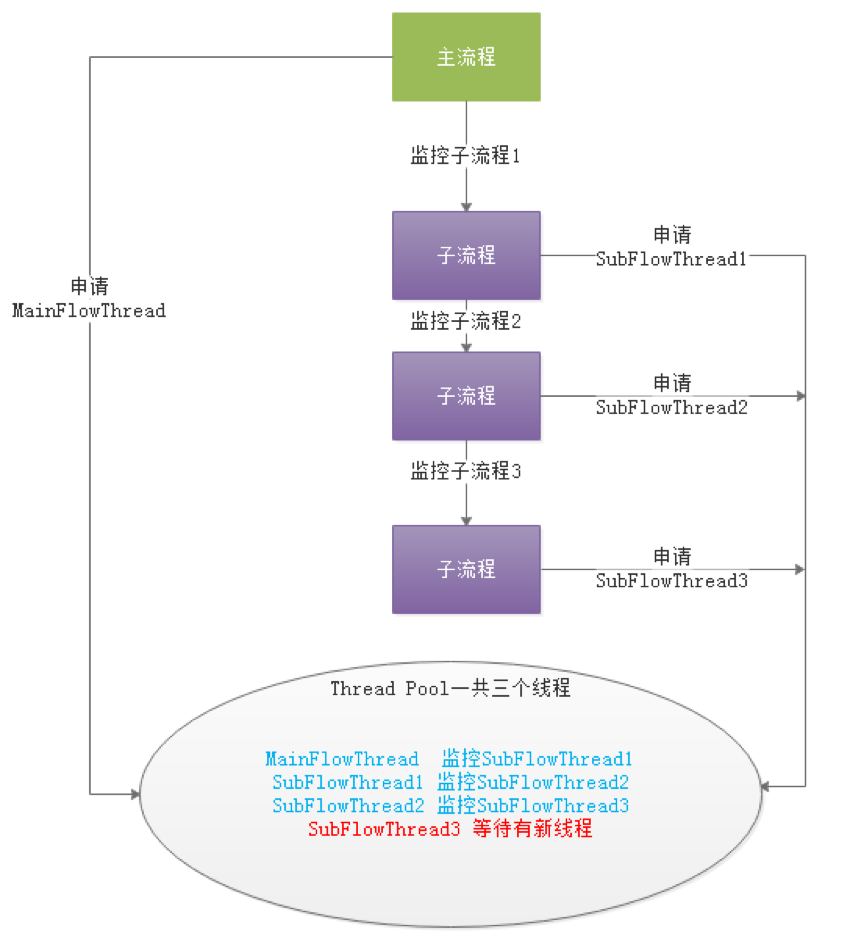 -
-
- 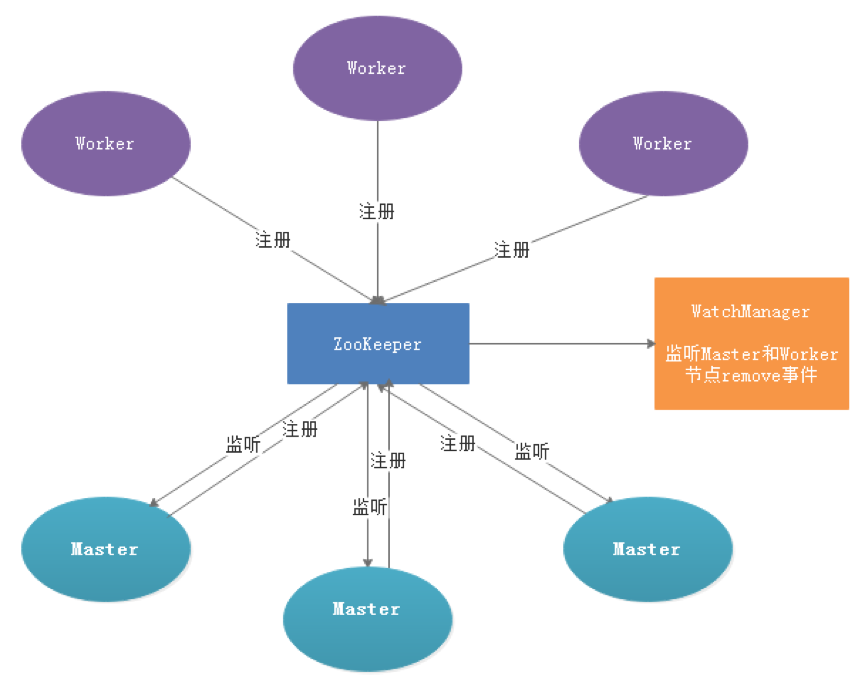 -
-
- 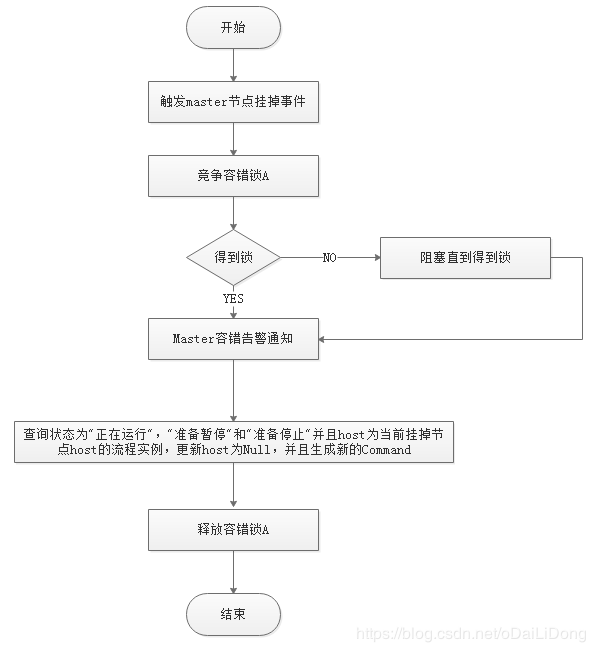 -
-
- 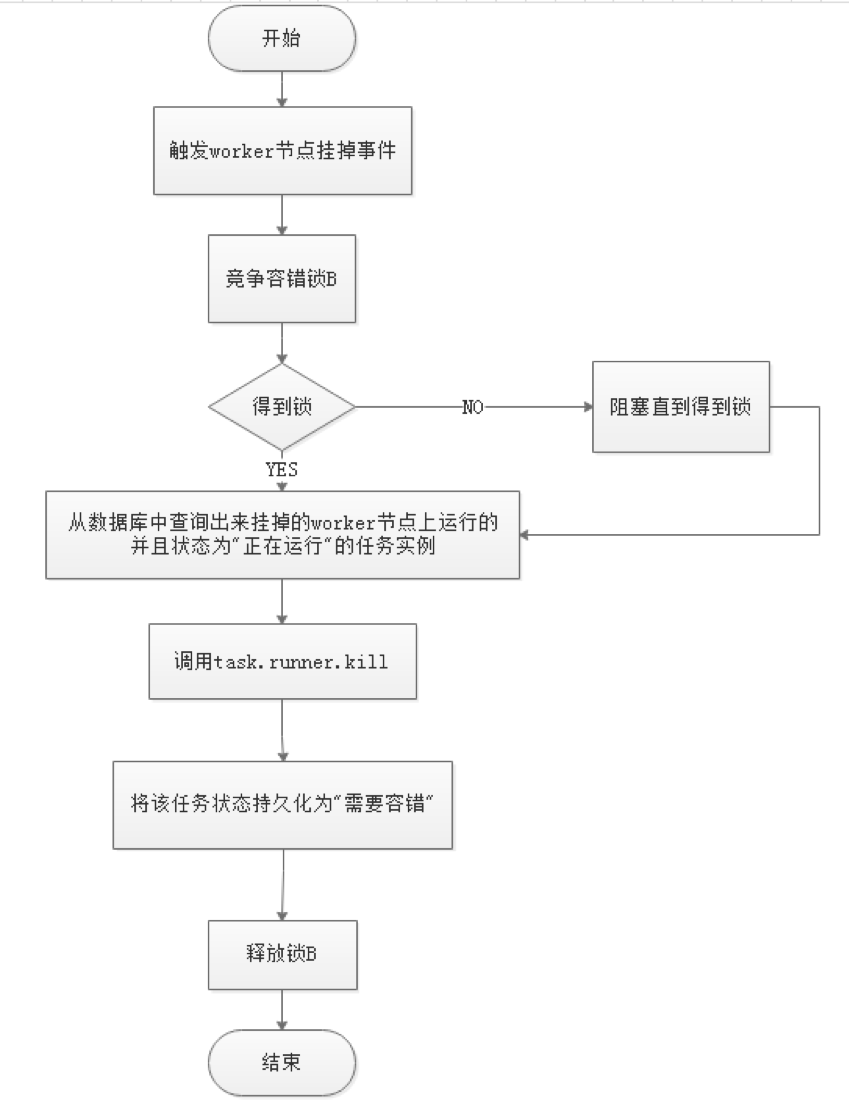 -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
- 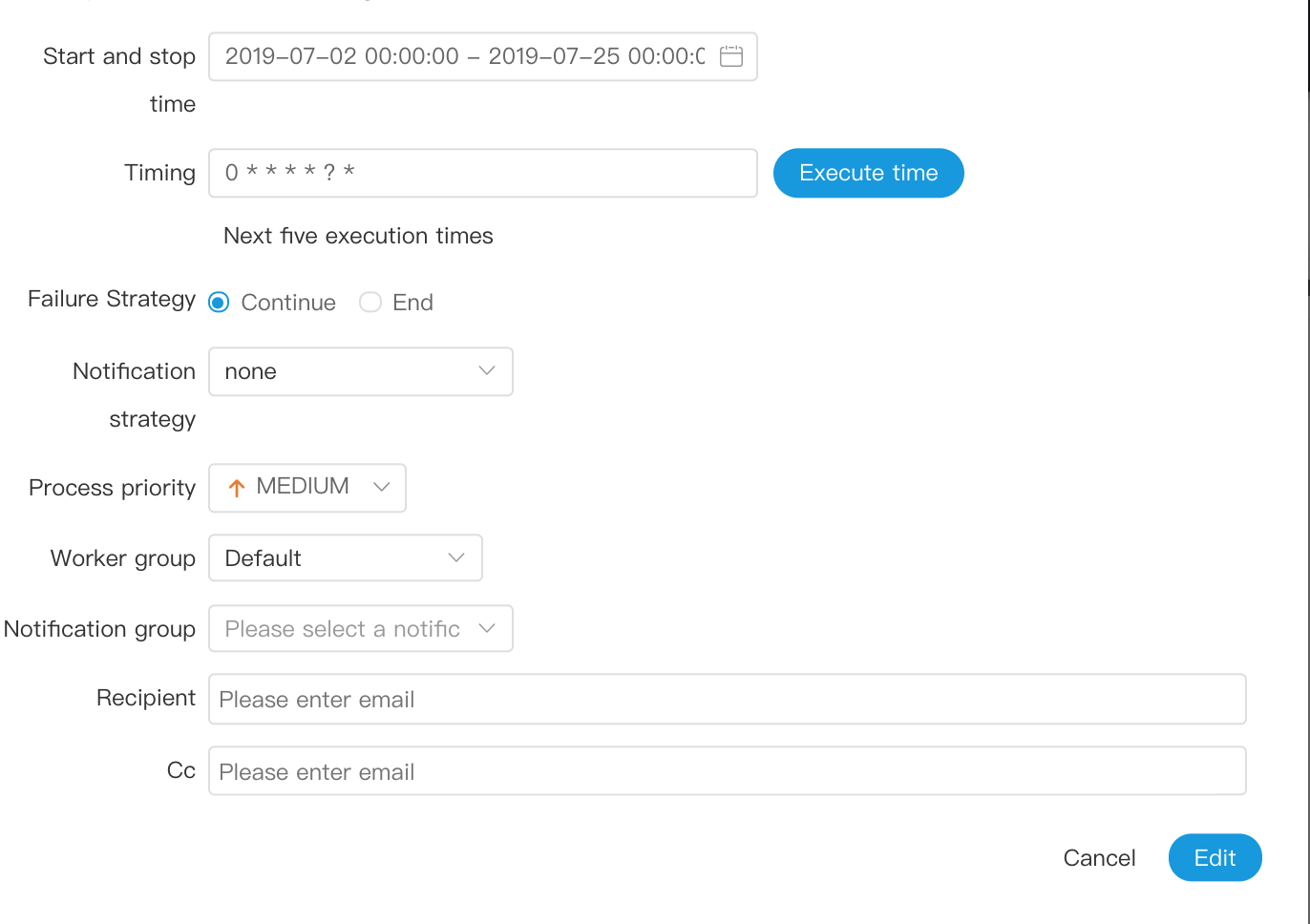 -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
- >  - >
- >
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
- 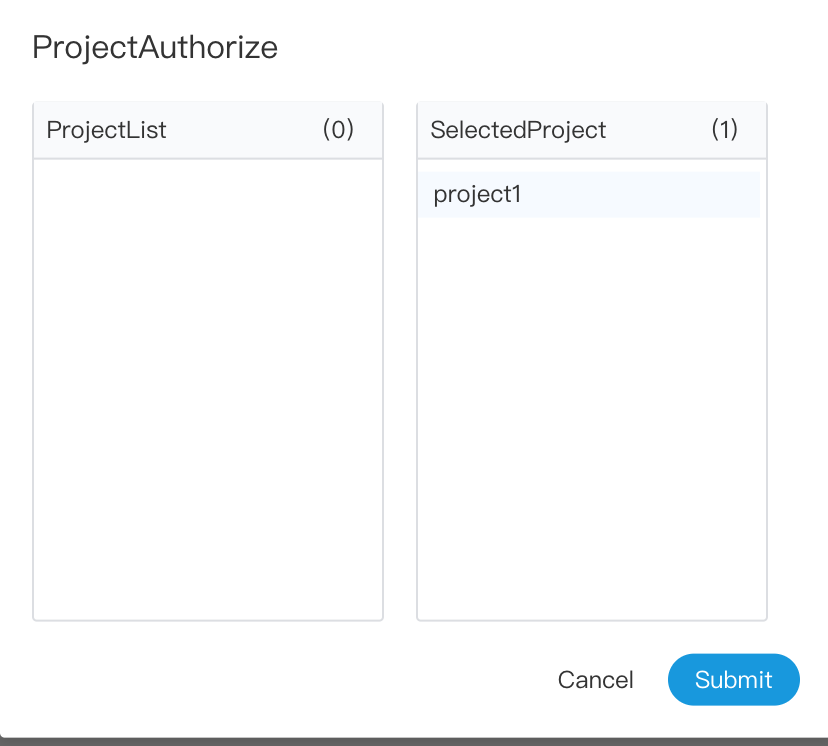 -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
- 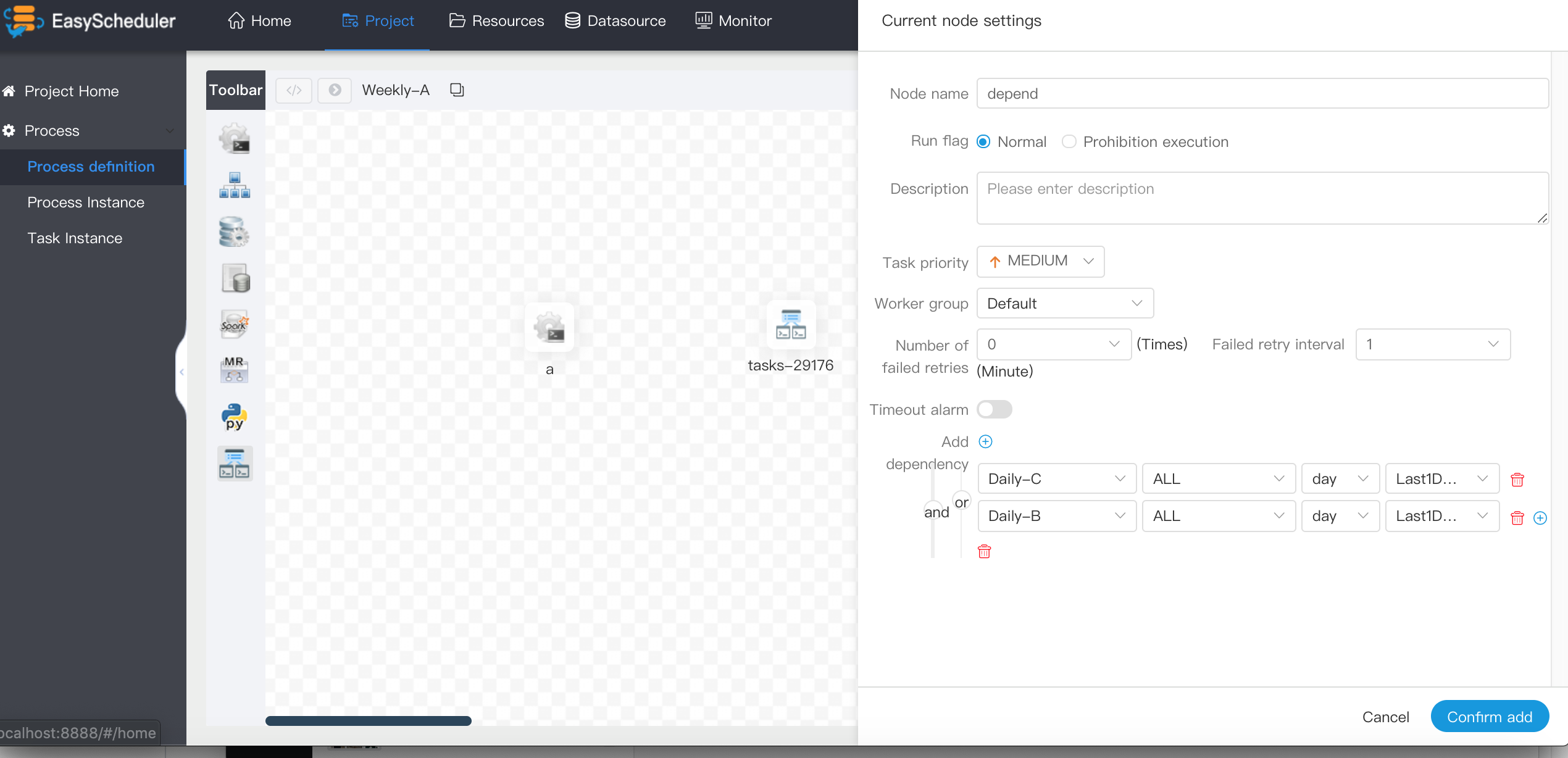 -
-
-  -
-
- 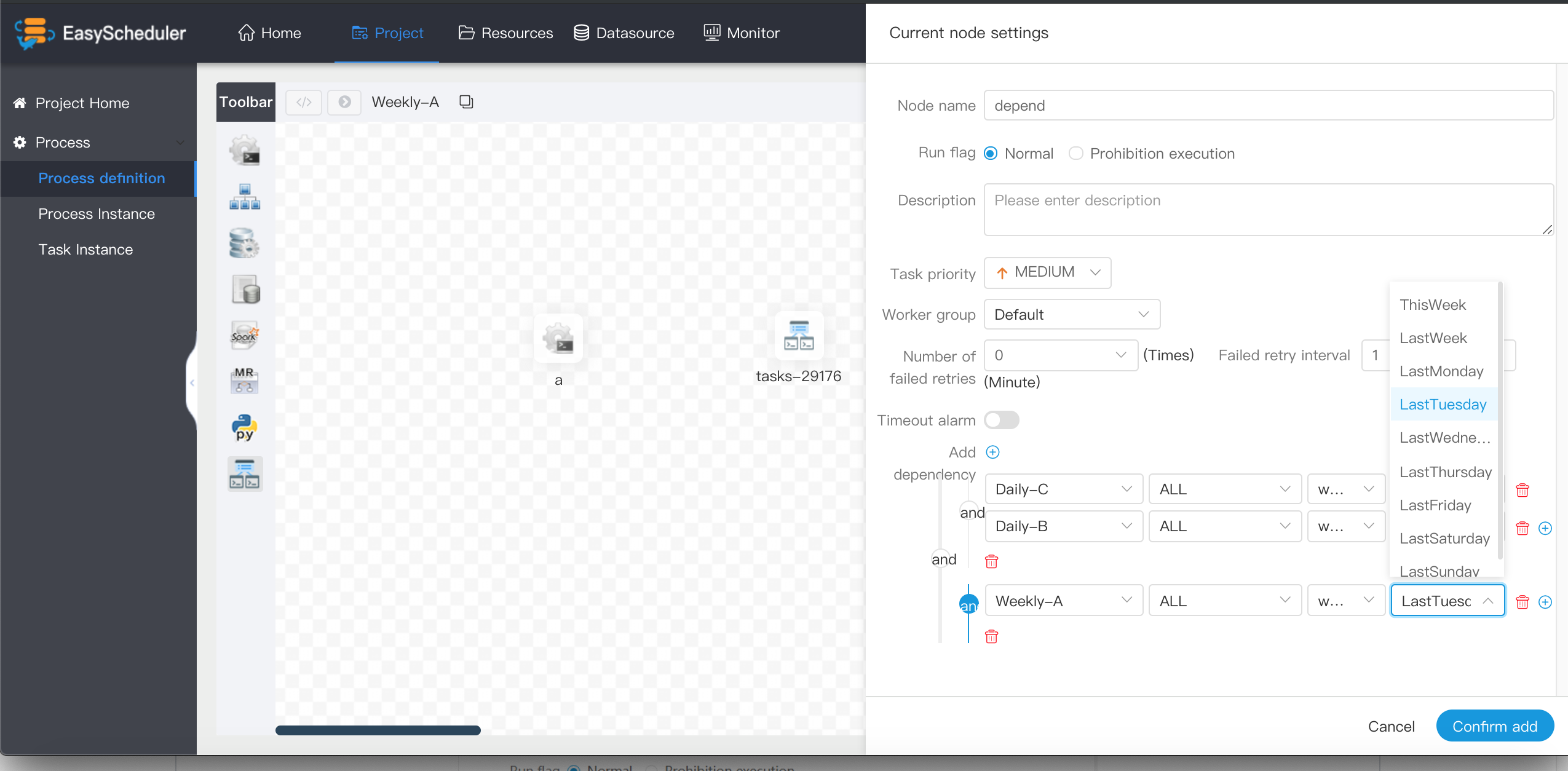 -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
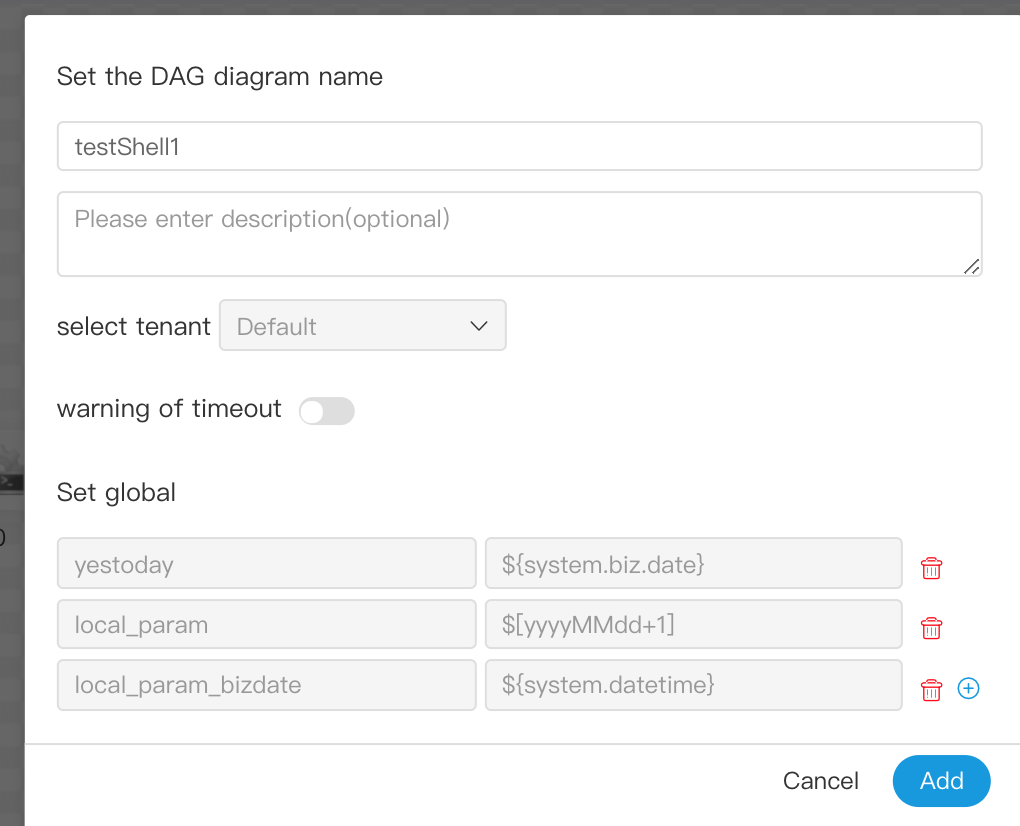
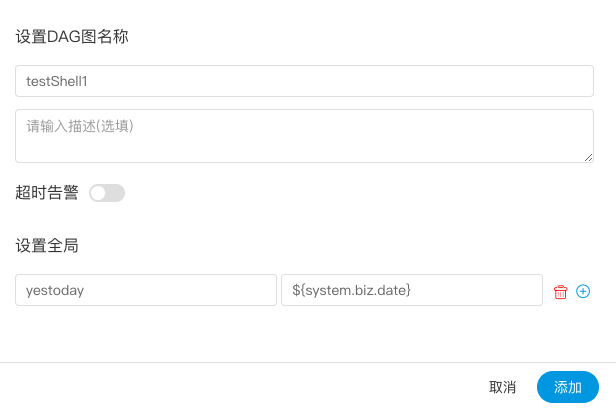
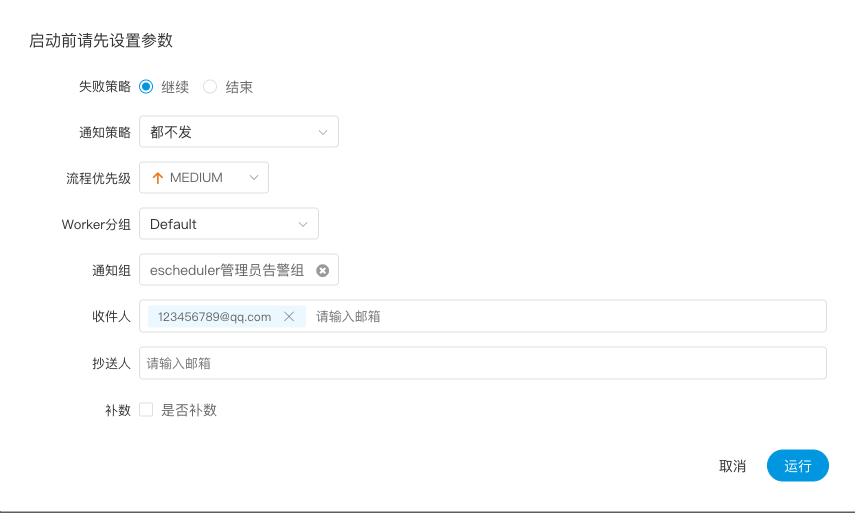
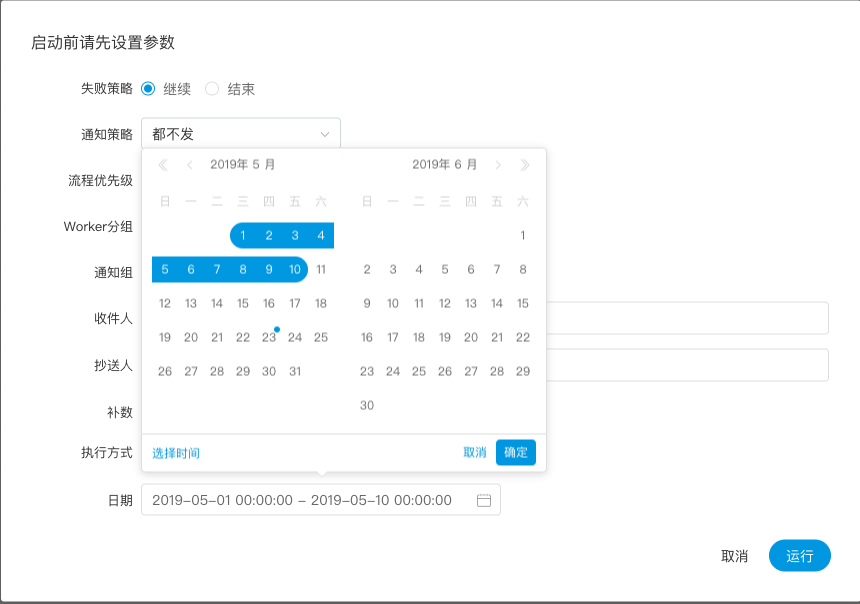
| variable | meaning |
|---|---|
| ${system.biz.date} | -The timing time of routine dispatching instance is one day before, in yyyyyMMdd format. When data is supplemented, the date + 1 | -
| ${system.biz.curdate} | -Daily scheduling example timing time, format is yyyyyMMdd, when supplementing data, the date + 1 | -
| ${system.datetime} | -Daily scheduling example timing time, format is yyyyyMMddHmmss, when supplementing data, the date + 1 | -
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
-  -
-
- 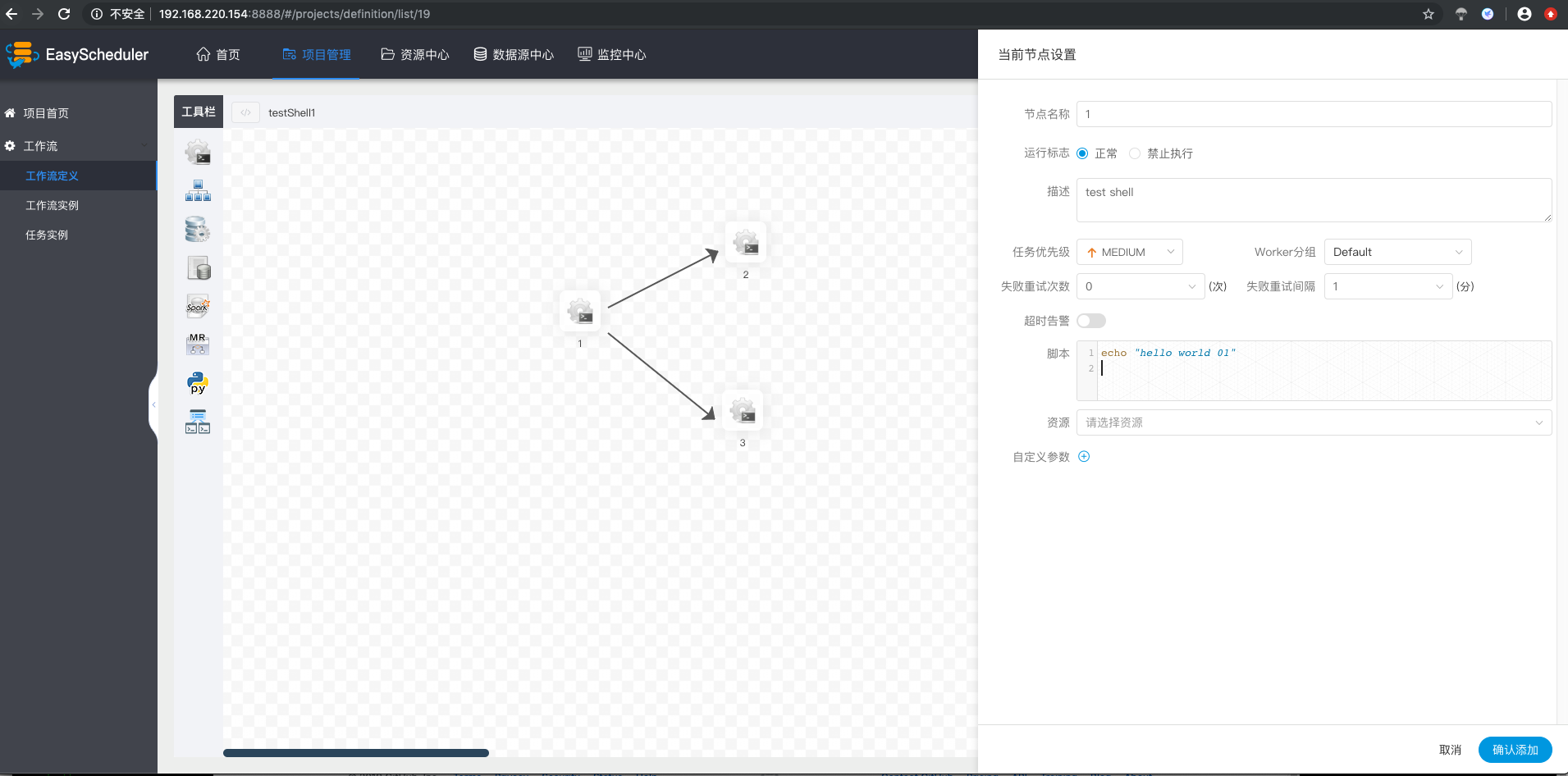 -
-
- 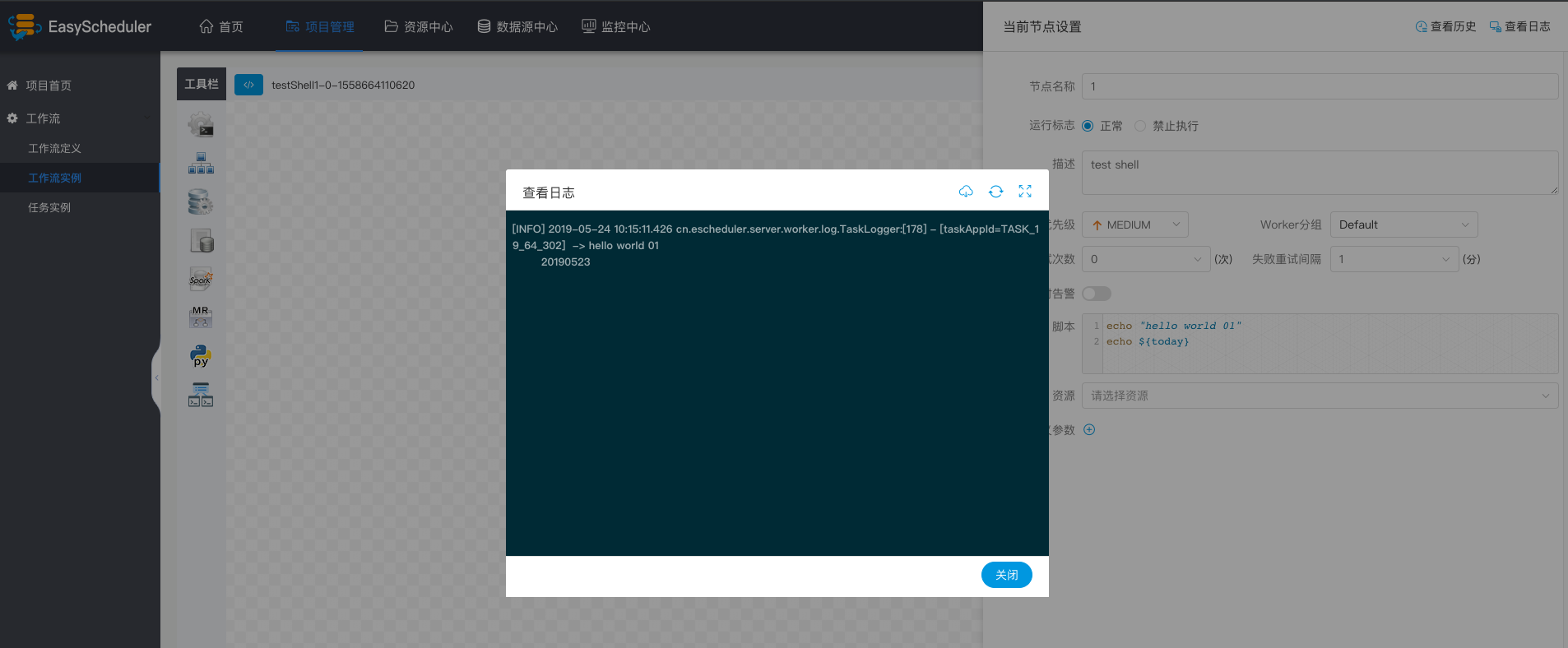 -
-
-
-
-
-
- 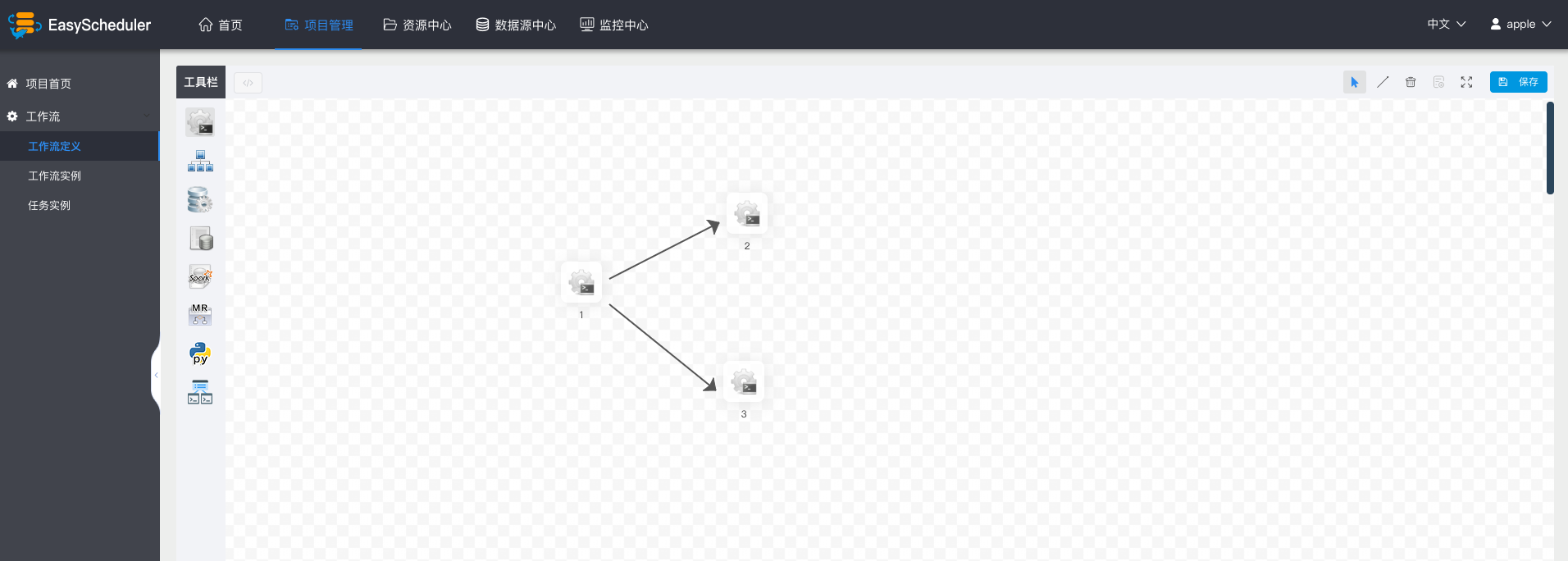 -
-
- 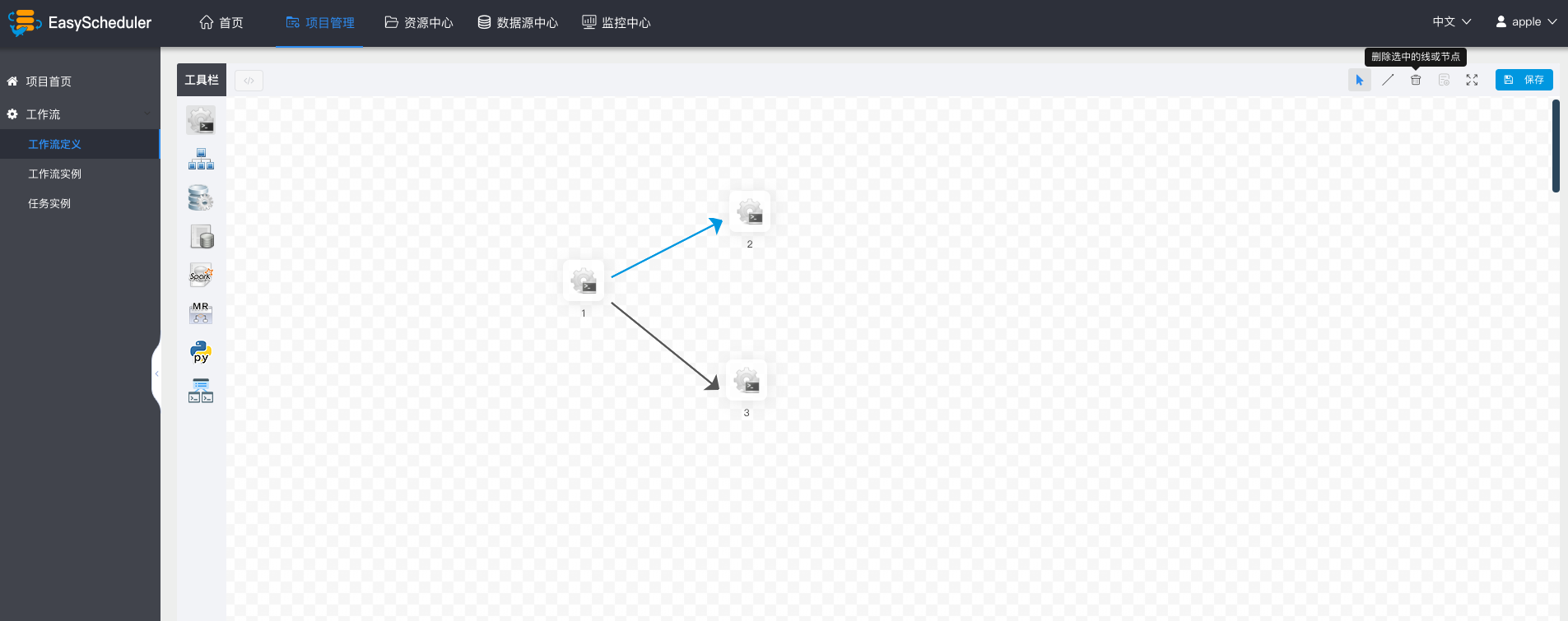 -
-
-  -
-
-  -
-
-  -
-
-  -
-
- 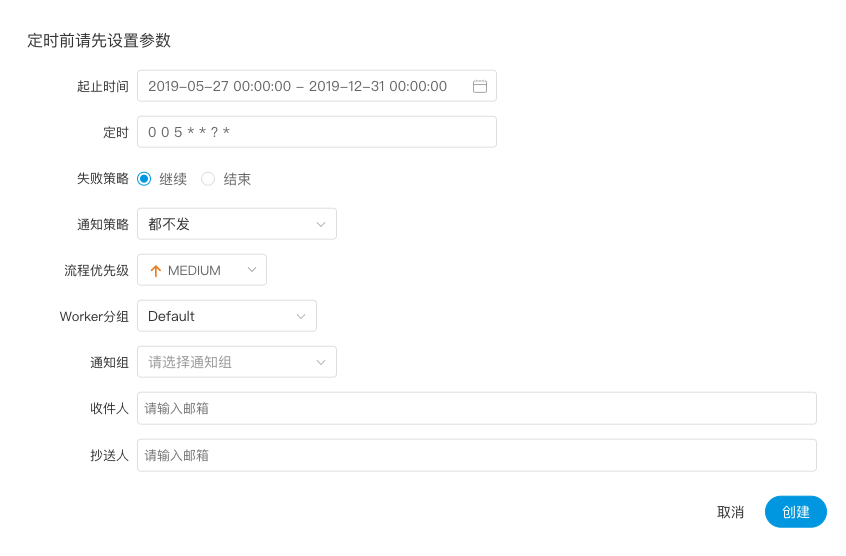 -
-
- 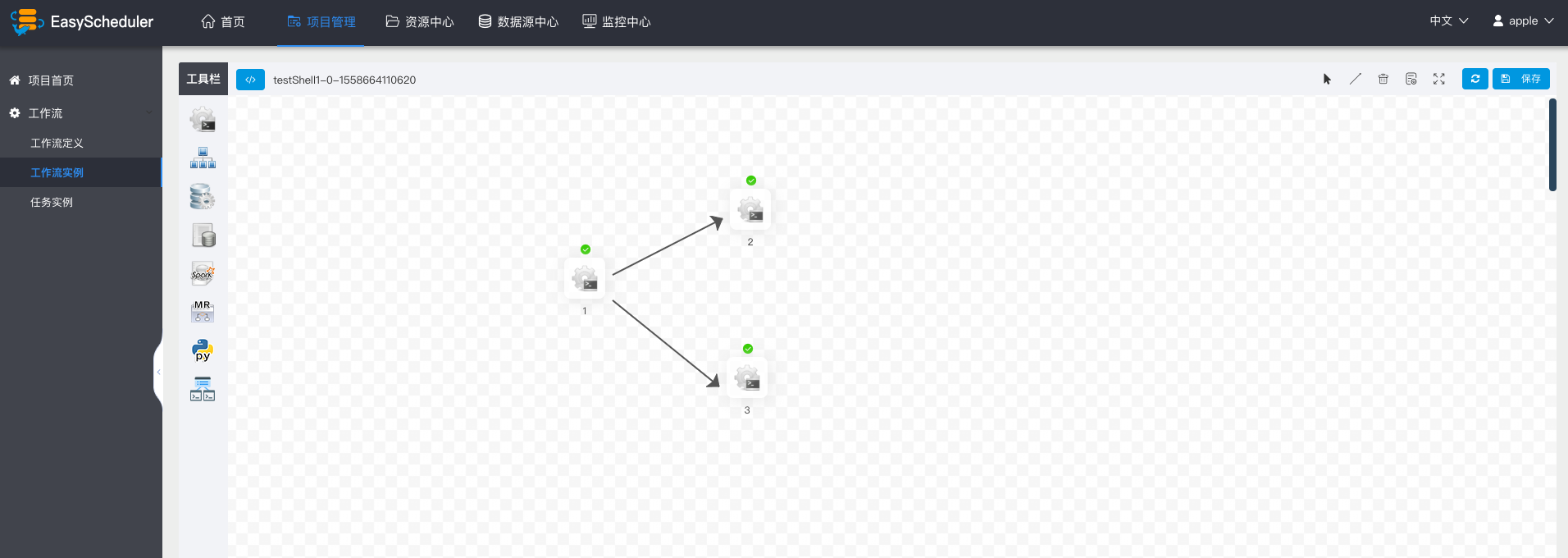 -
-
-
-
- 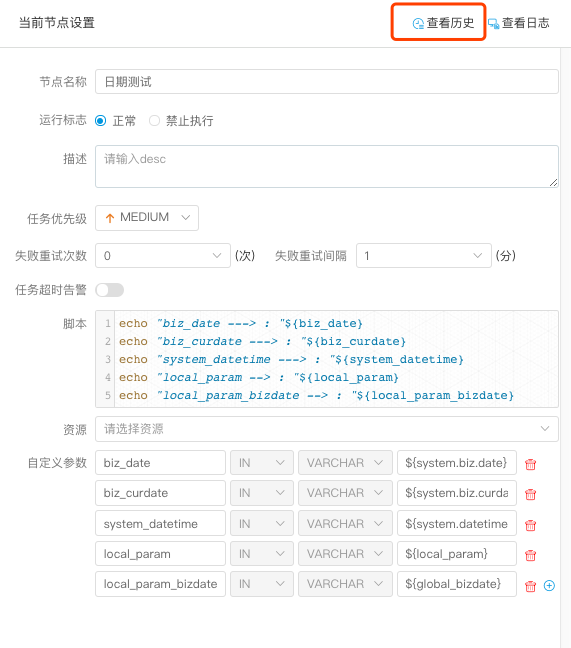 -
-
- 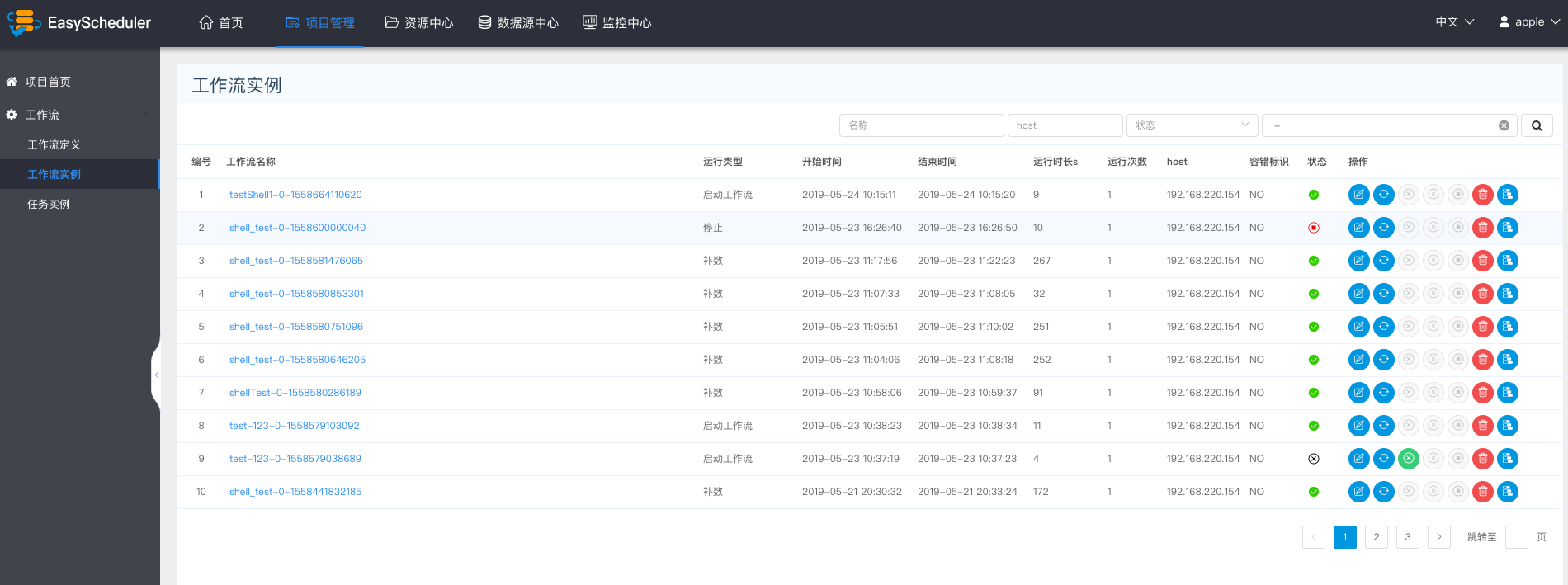 -
-
- 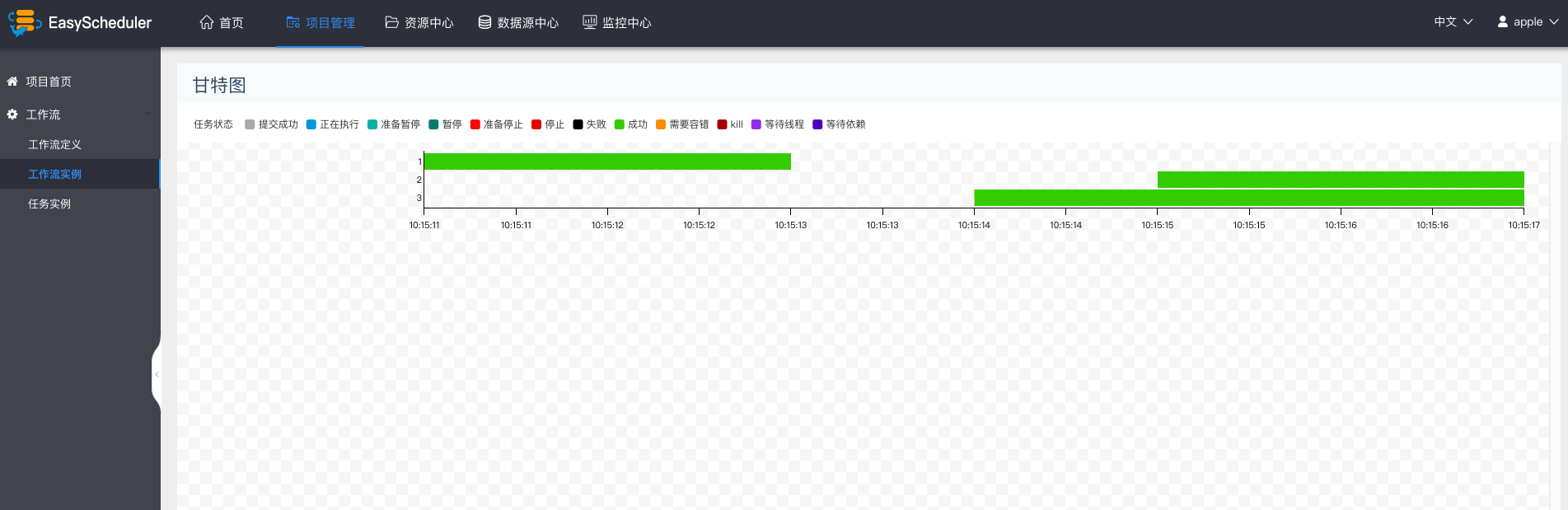 -
-
- 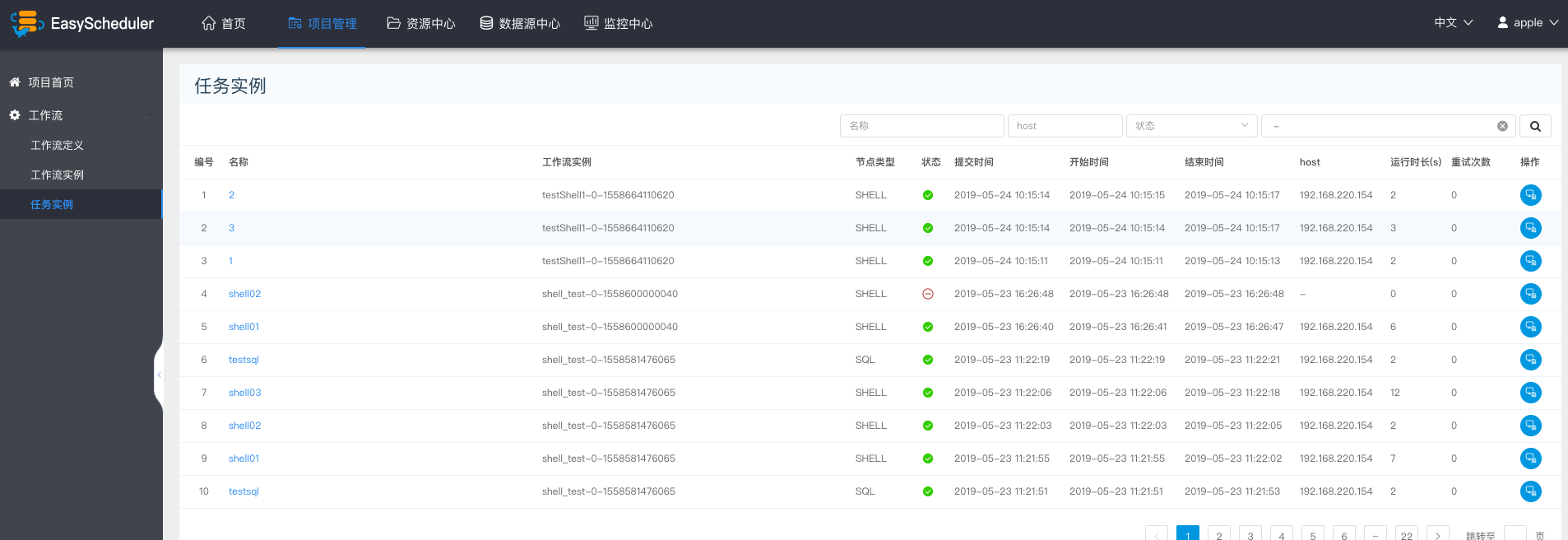 -
-
- 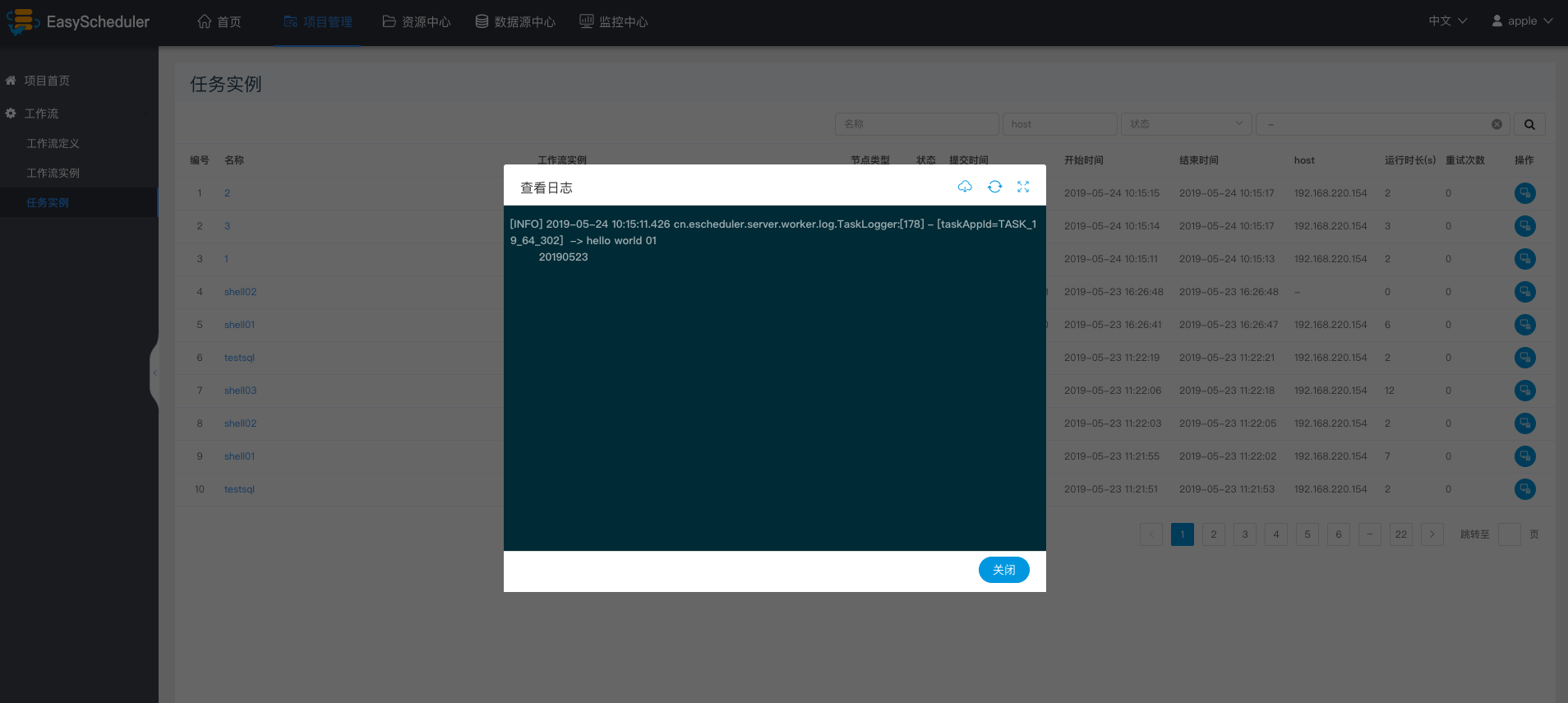 -
-
-  -
-
- 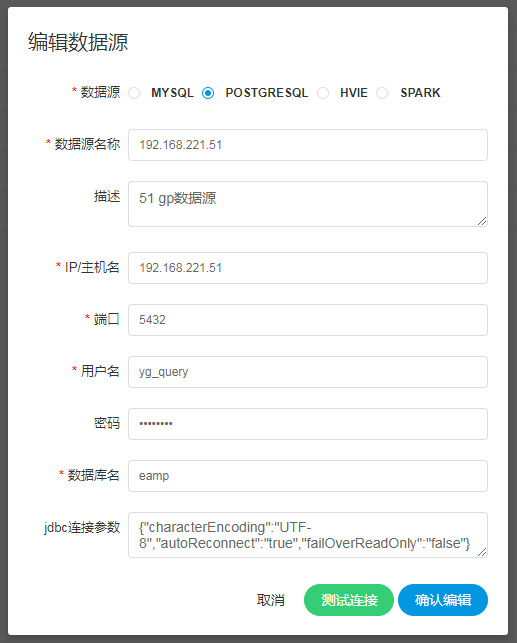 -
-
- 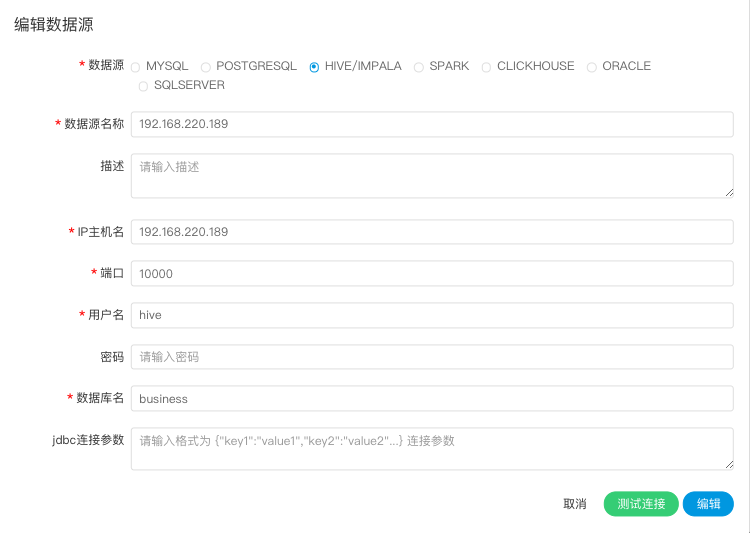 -
-
- 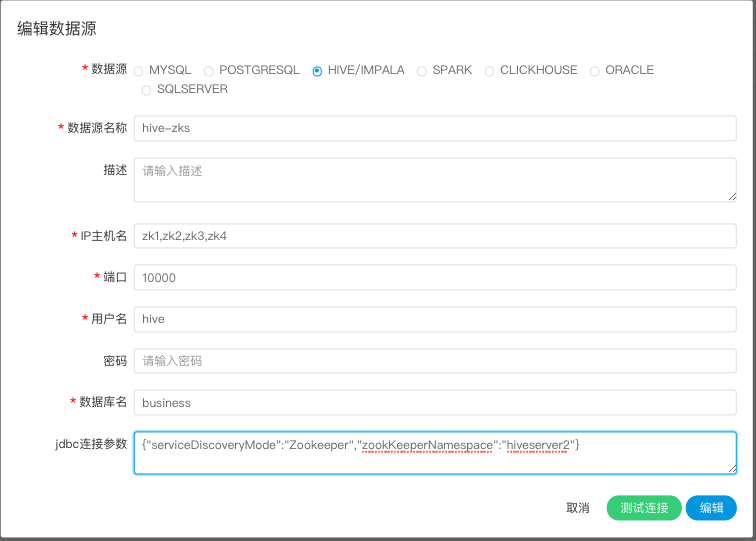 -
-
- 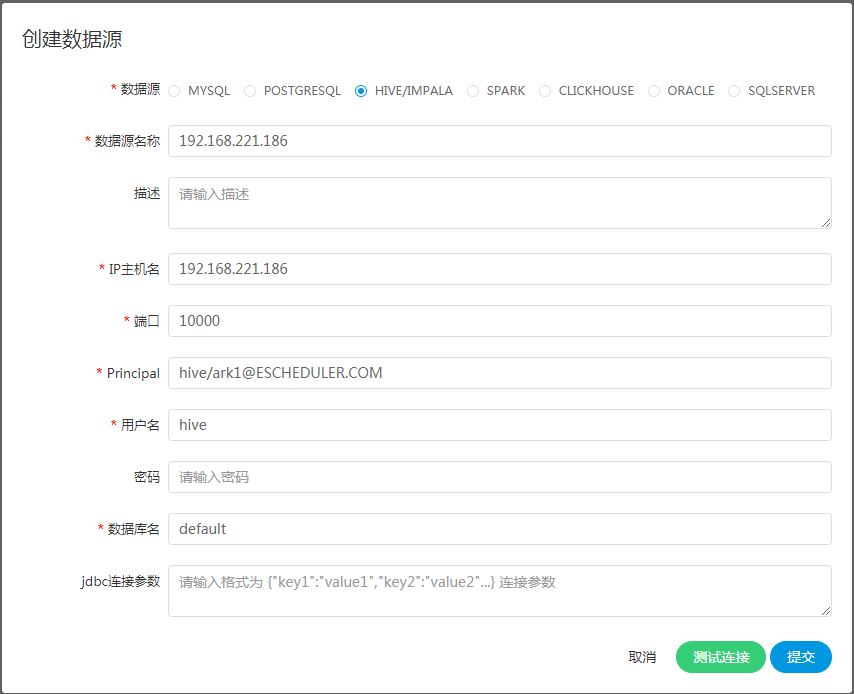 -
-
- 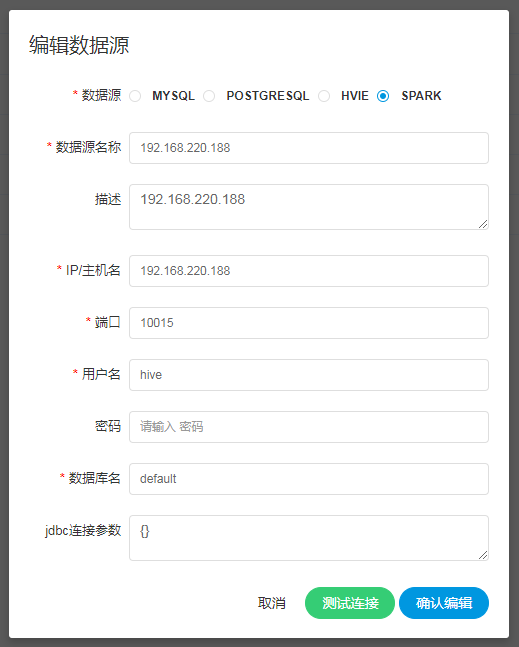 -
-
- 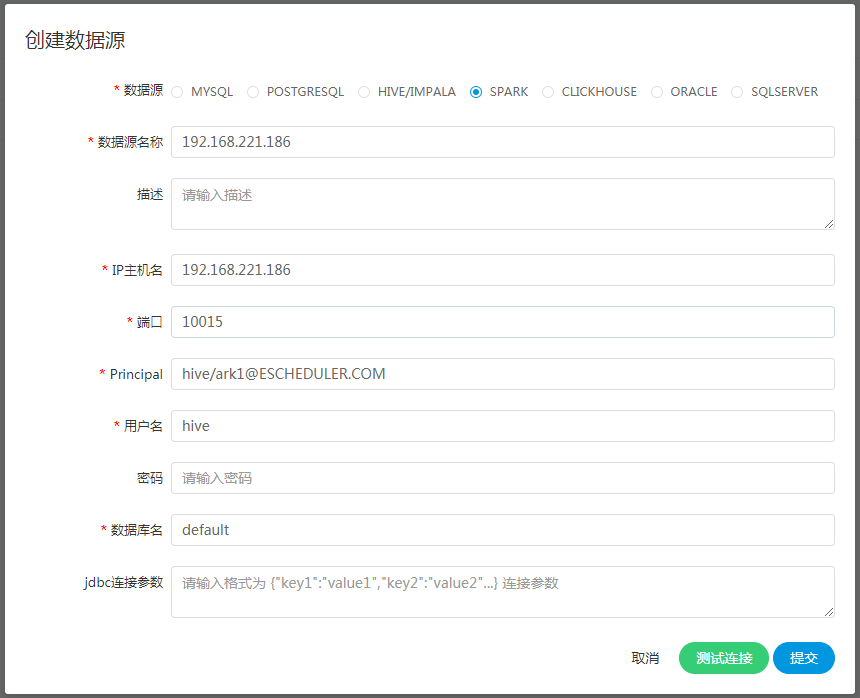 -
-
- 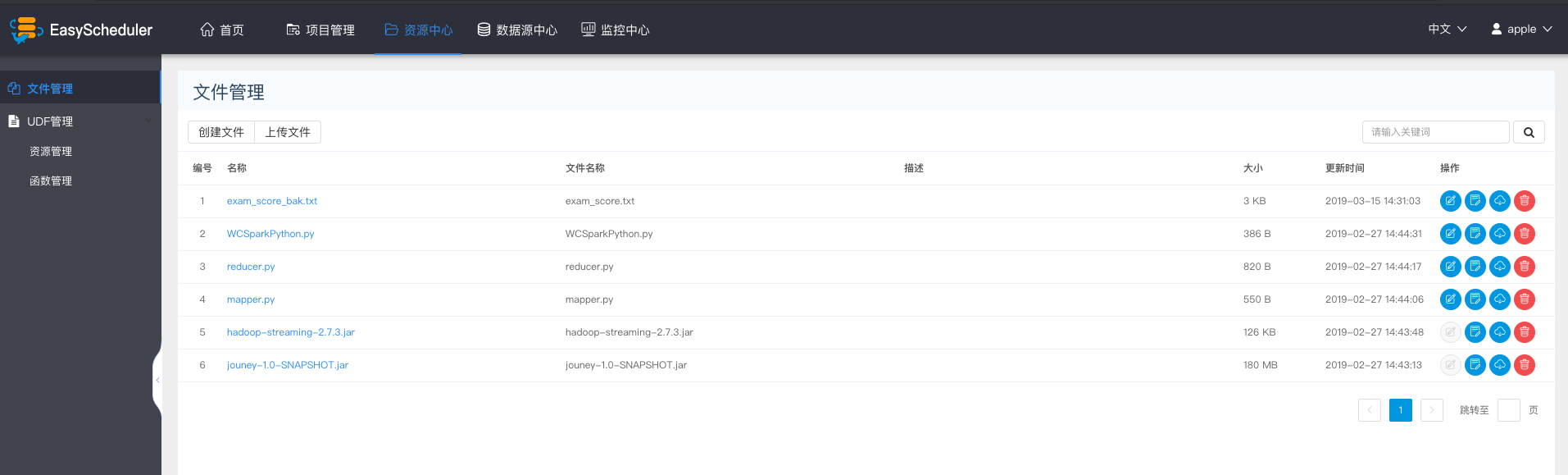 -
-
- 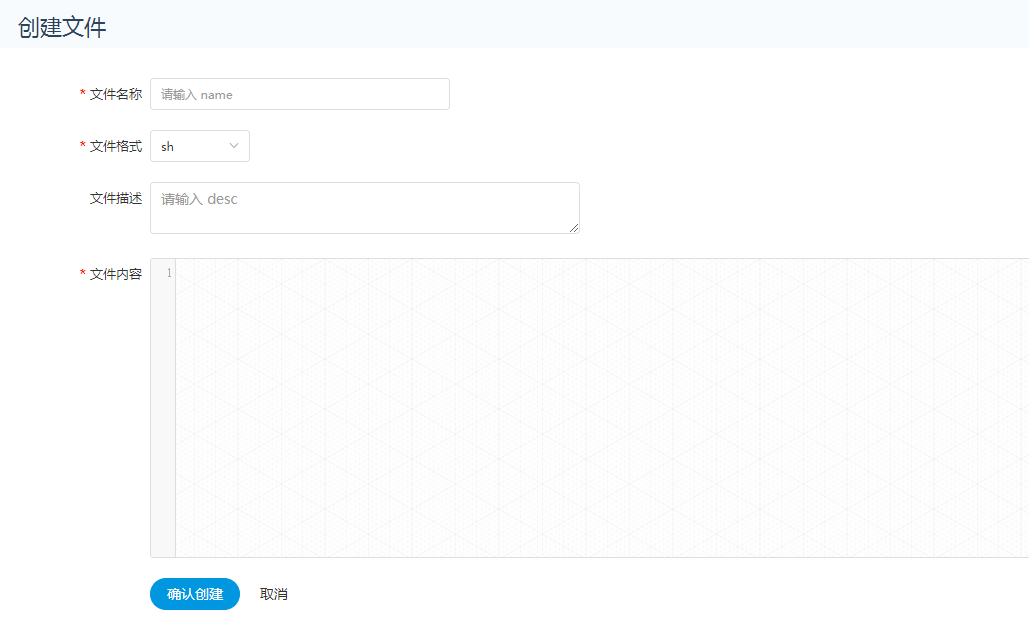 -
-
- 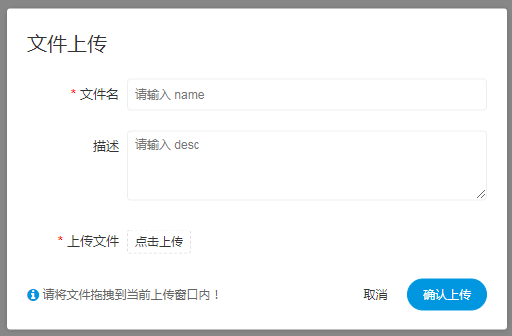 -
-
- 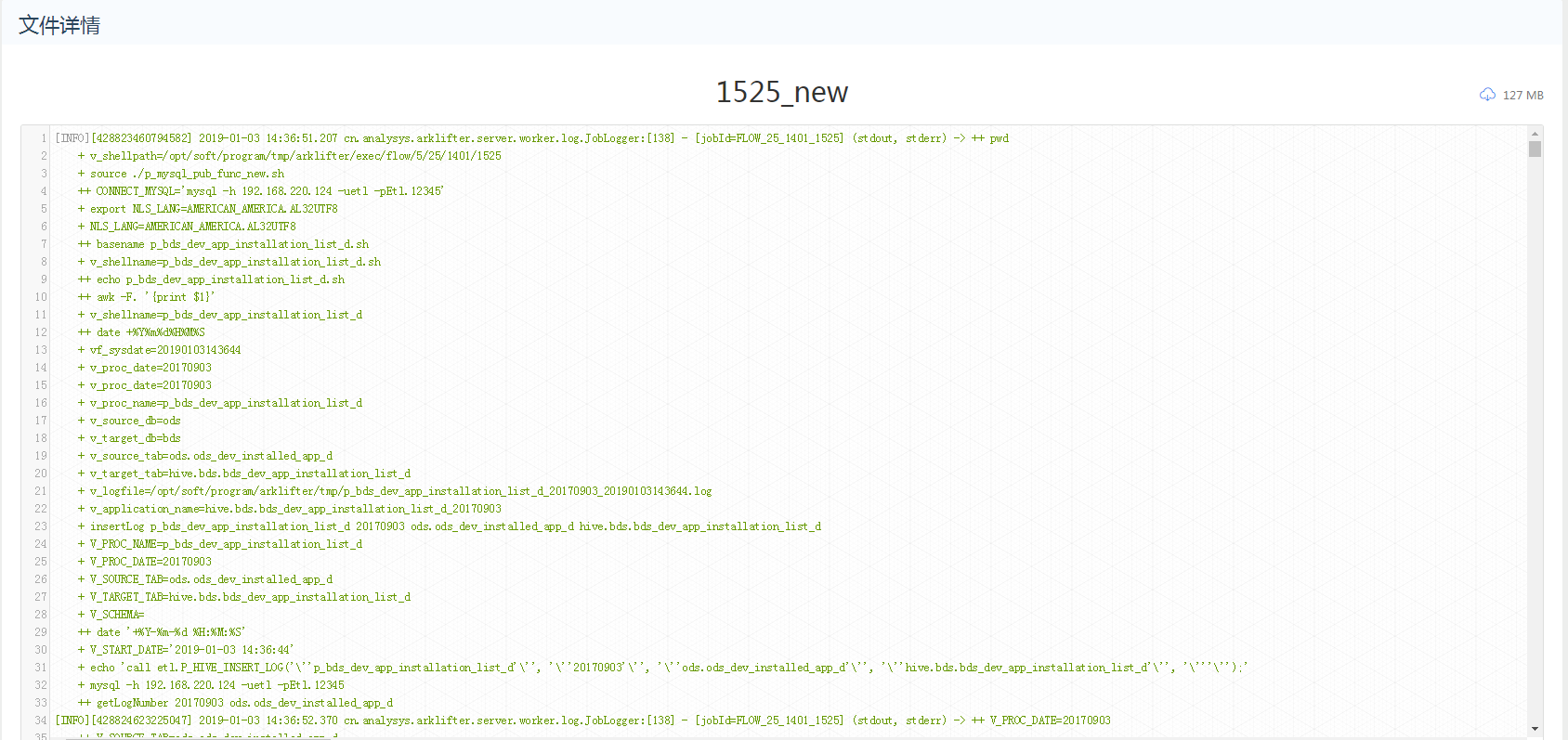 -
-
- 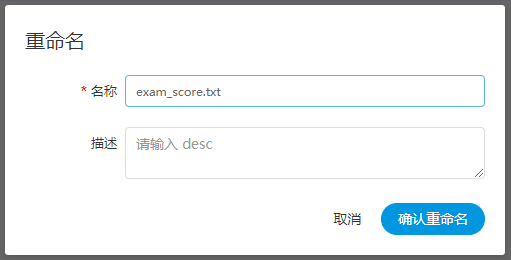 -
-
- 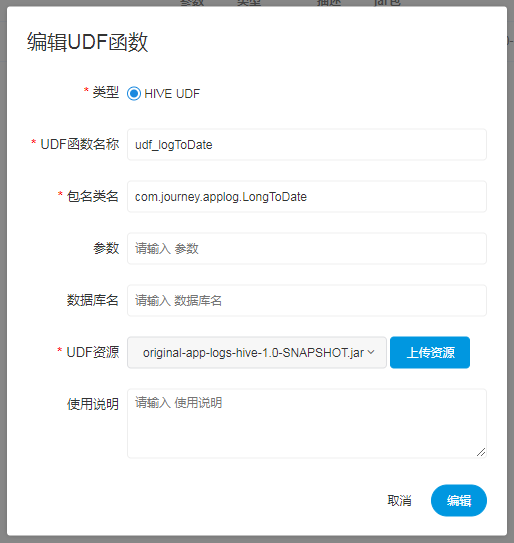 -
-
-
-
-
-
-
-
-
-
- 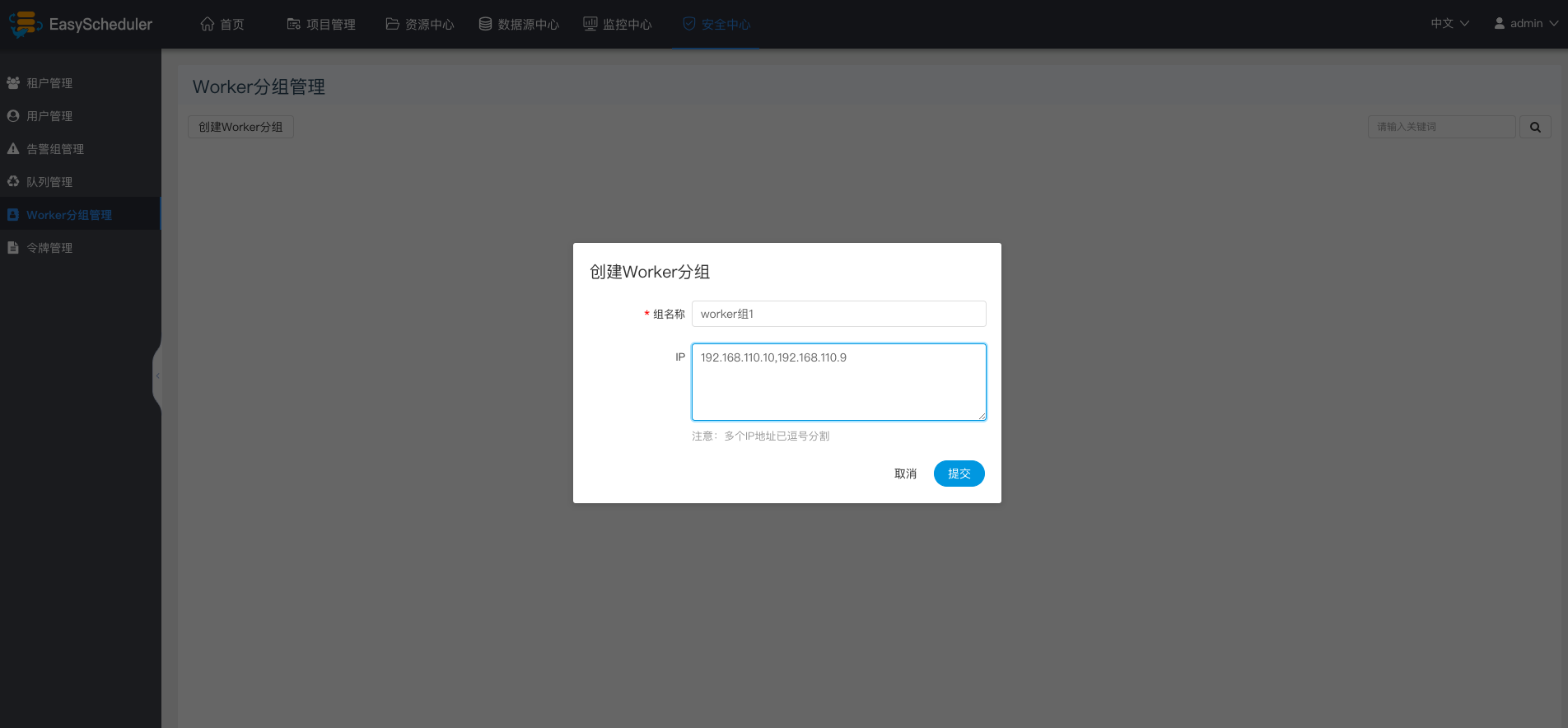 -
-
-  -
-
- 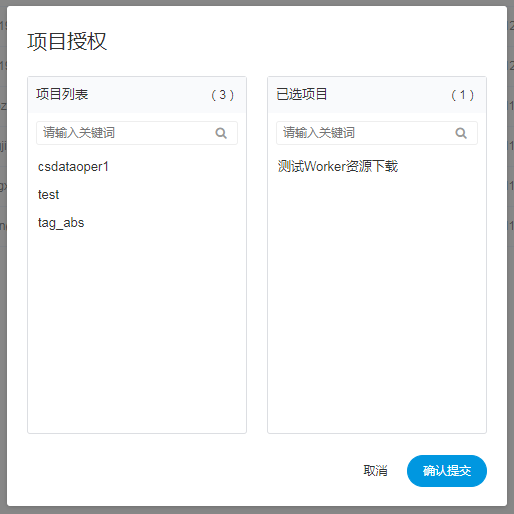 -
-
-  -
-
- 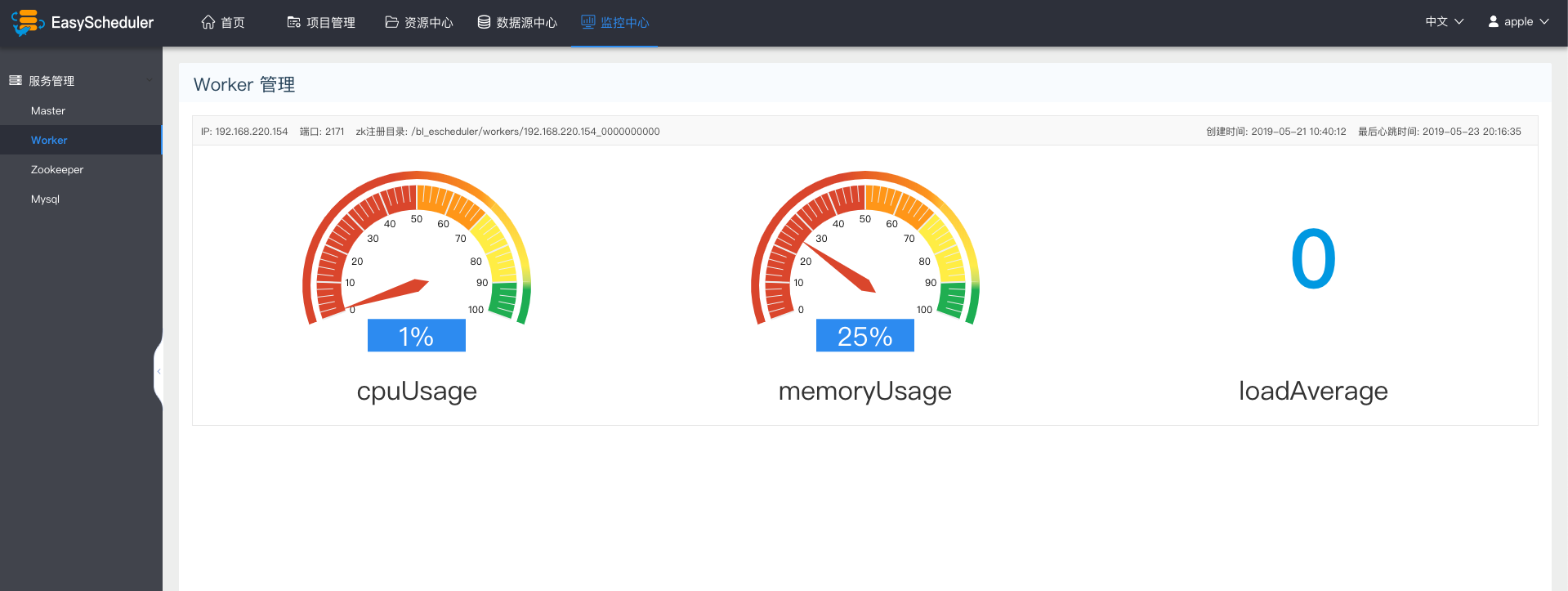 -
-
- 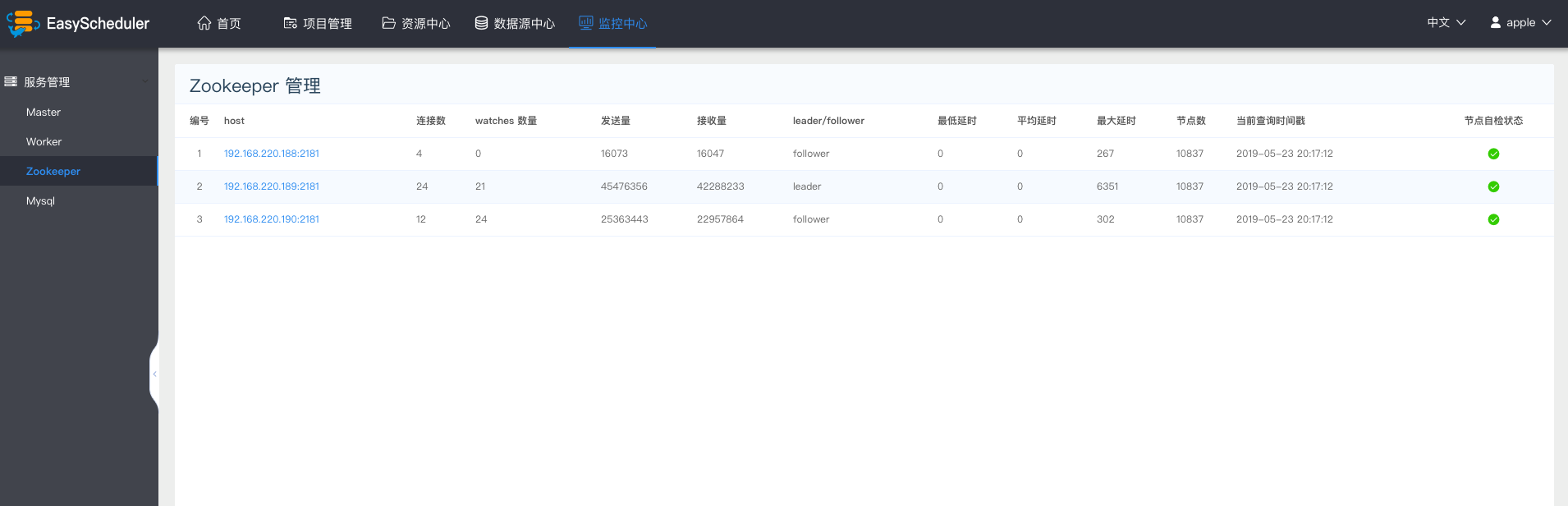 -
-
- 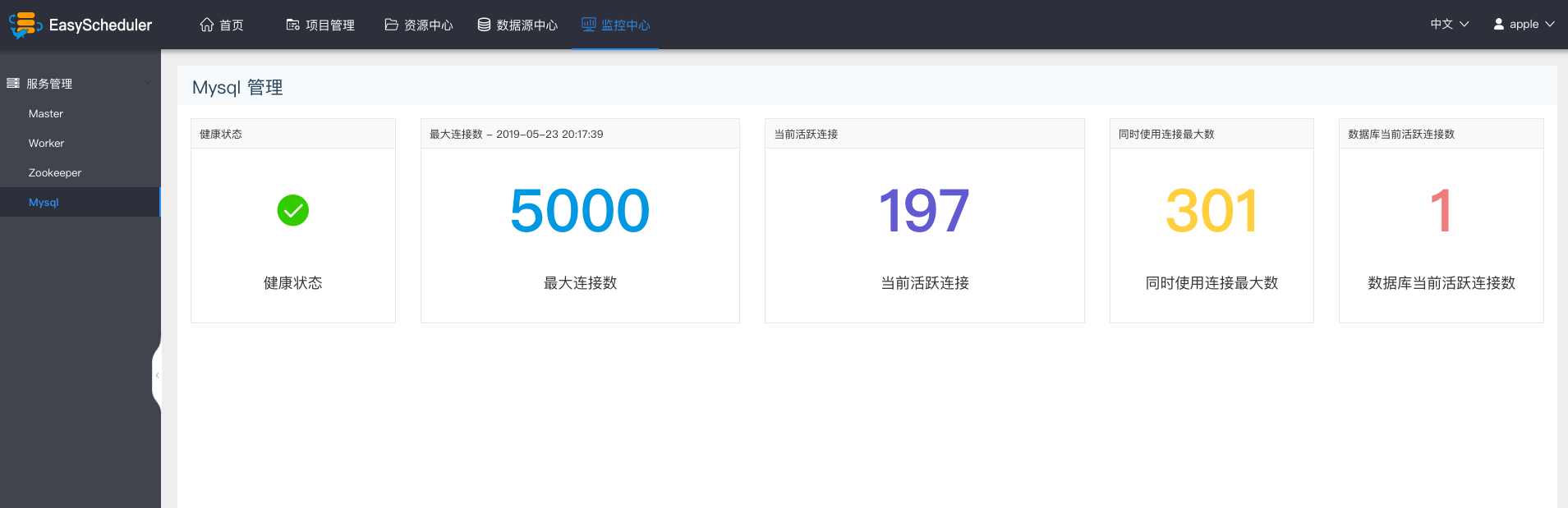 -
-
- 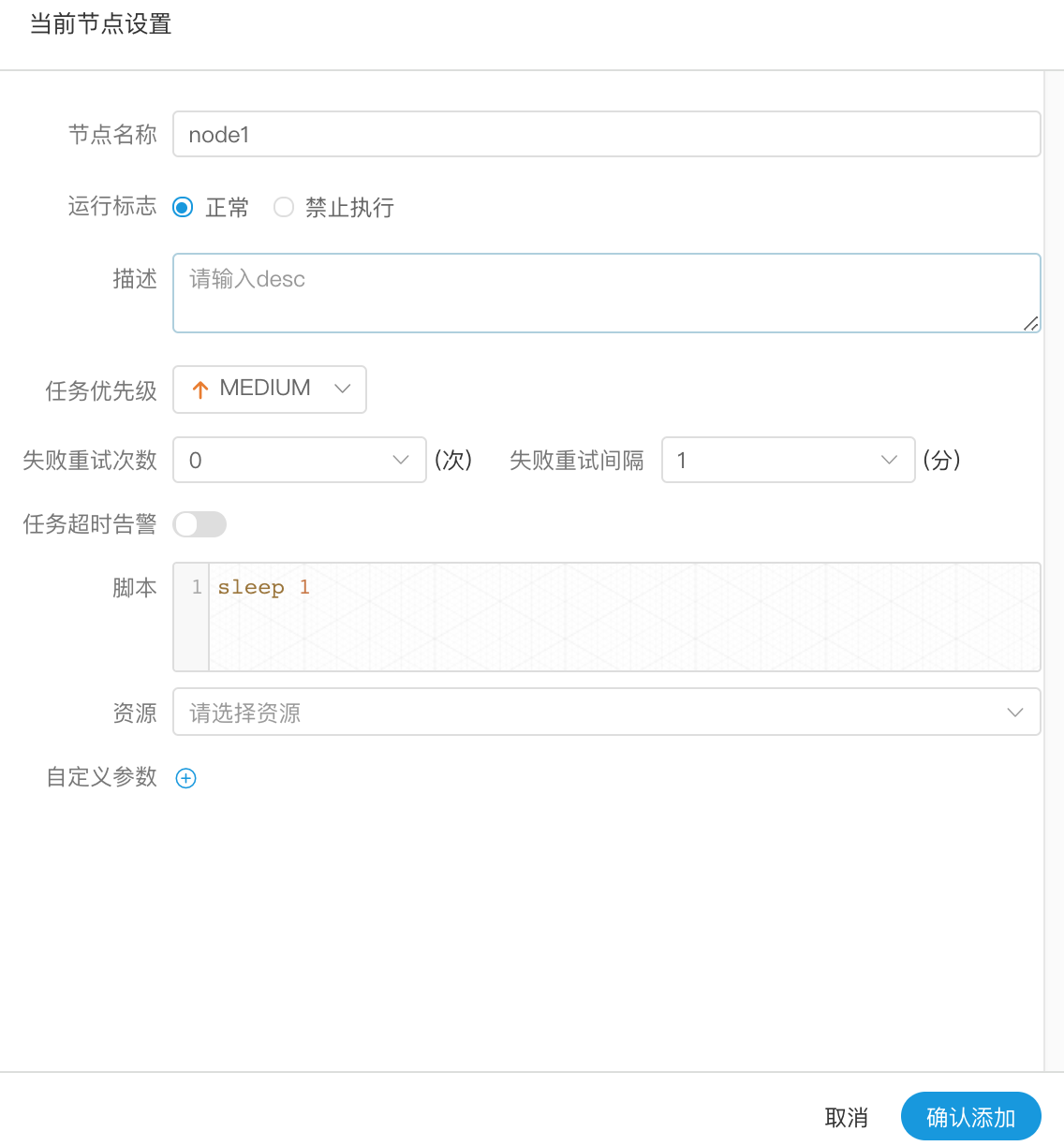 -
-
- 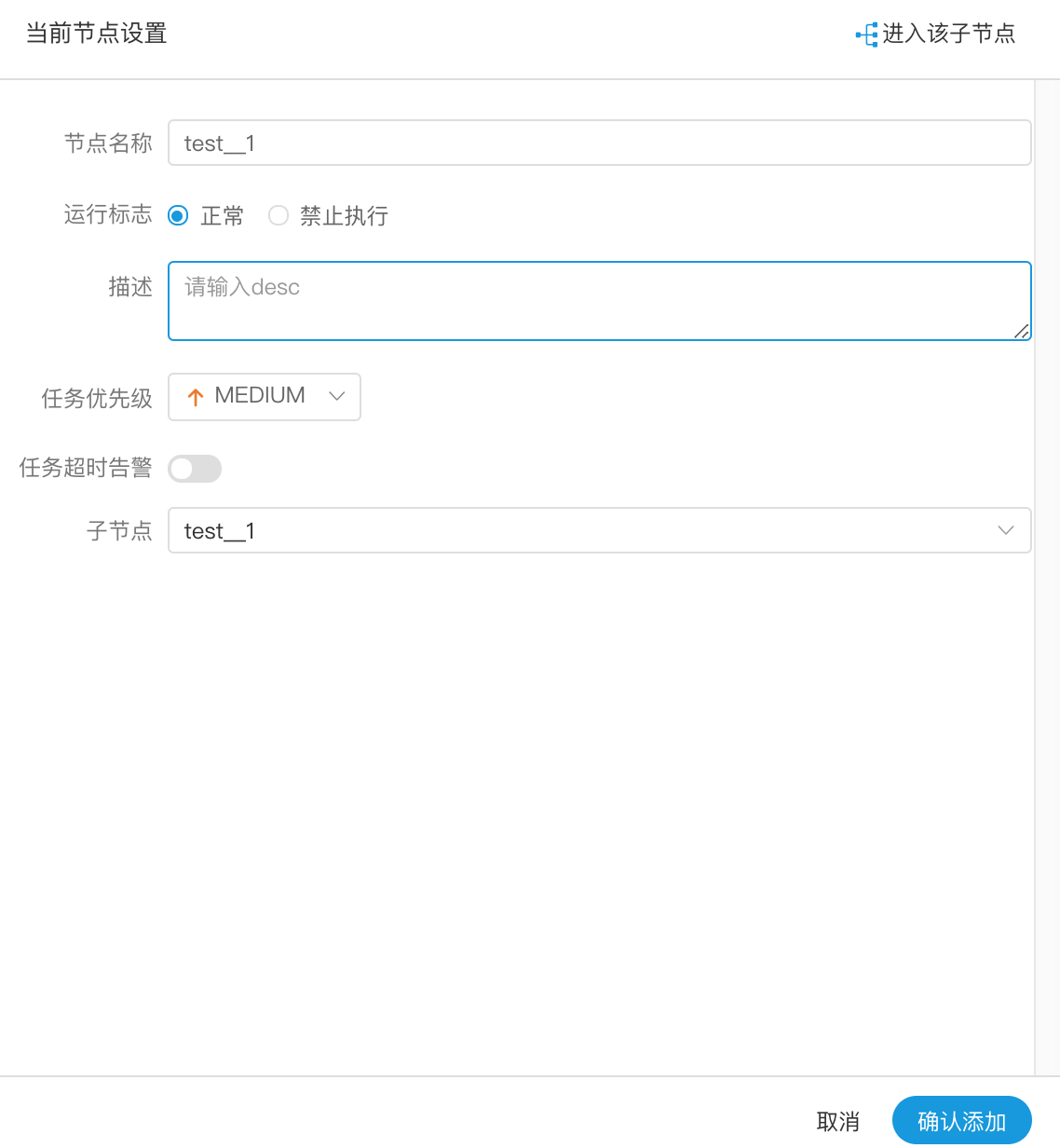 -
-
- 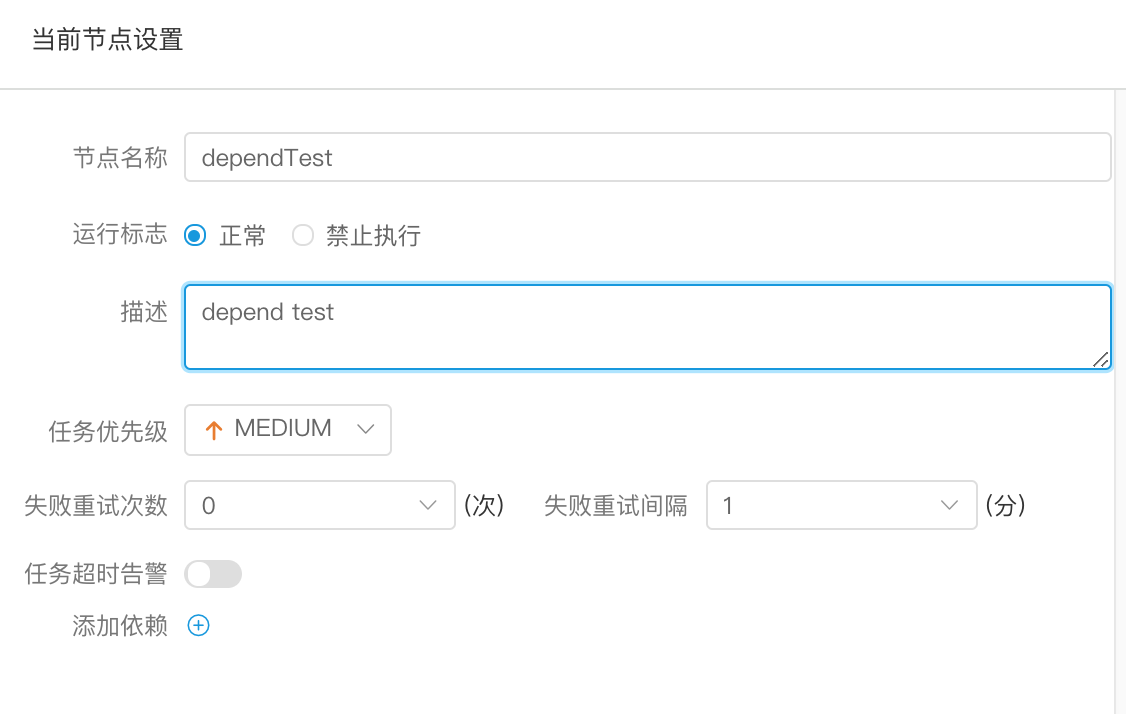 -
-
- 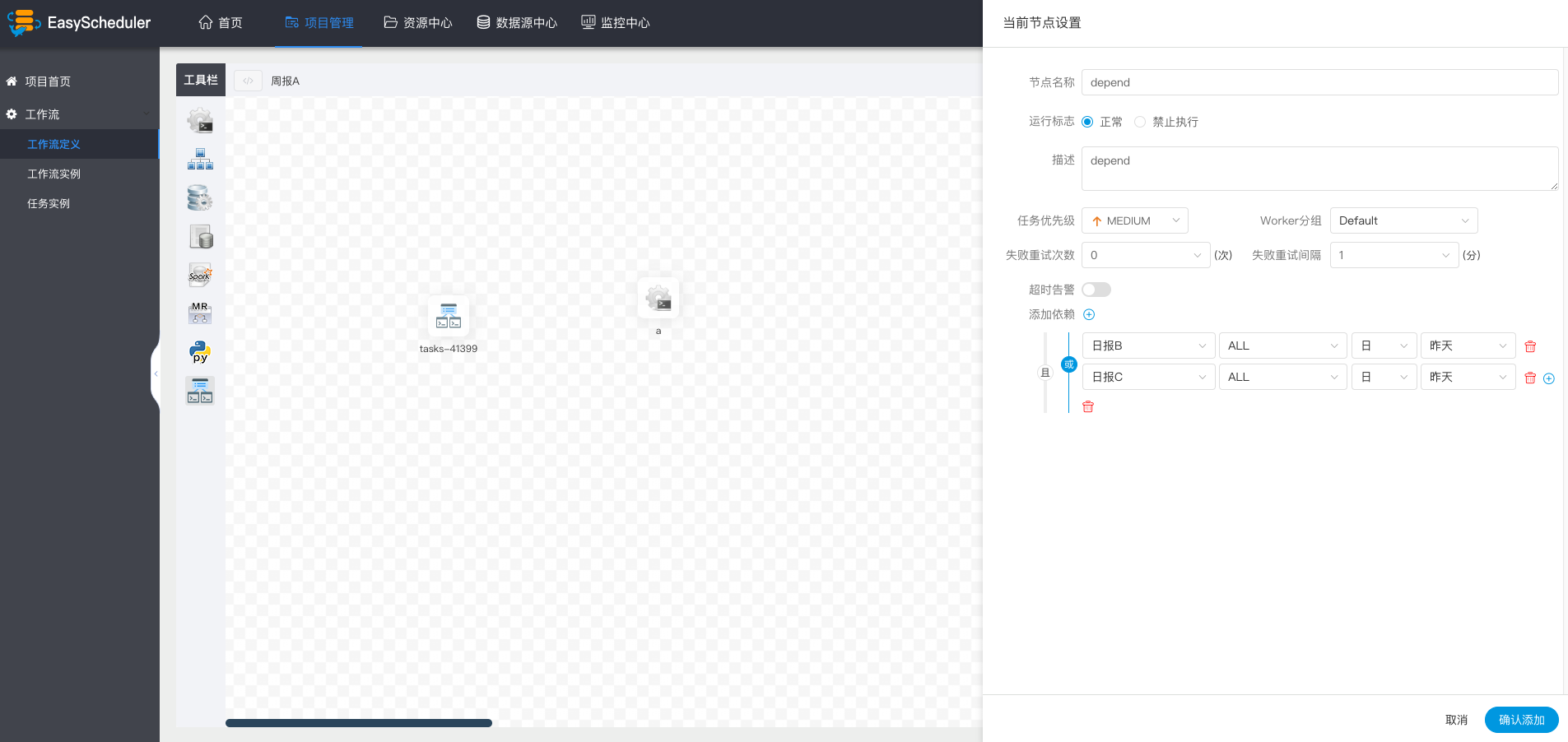 -
-
- 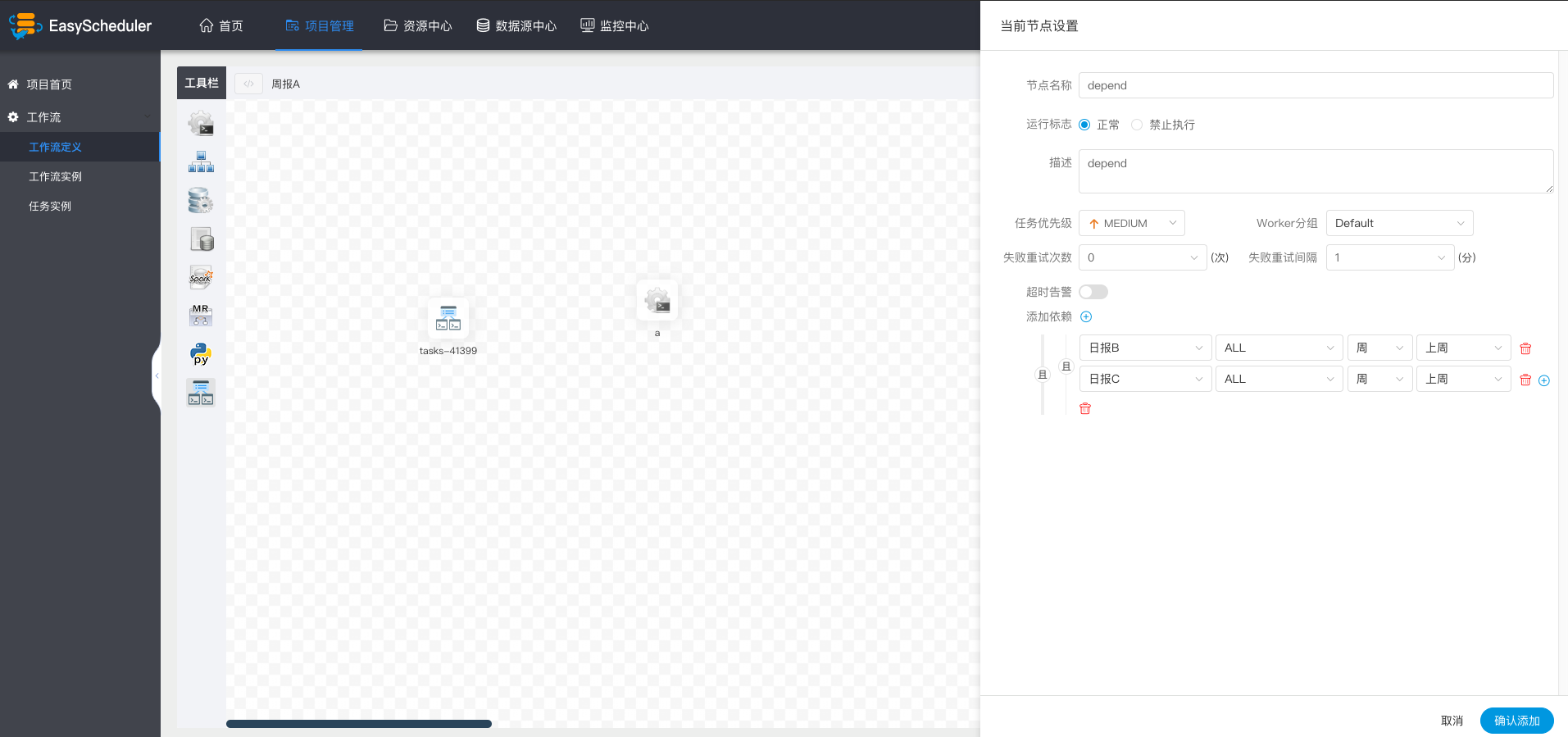 -
-
- 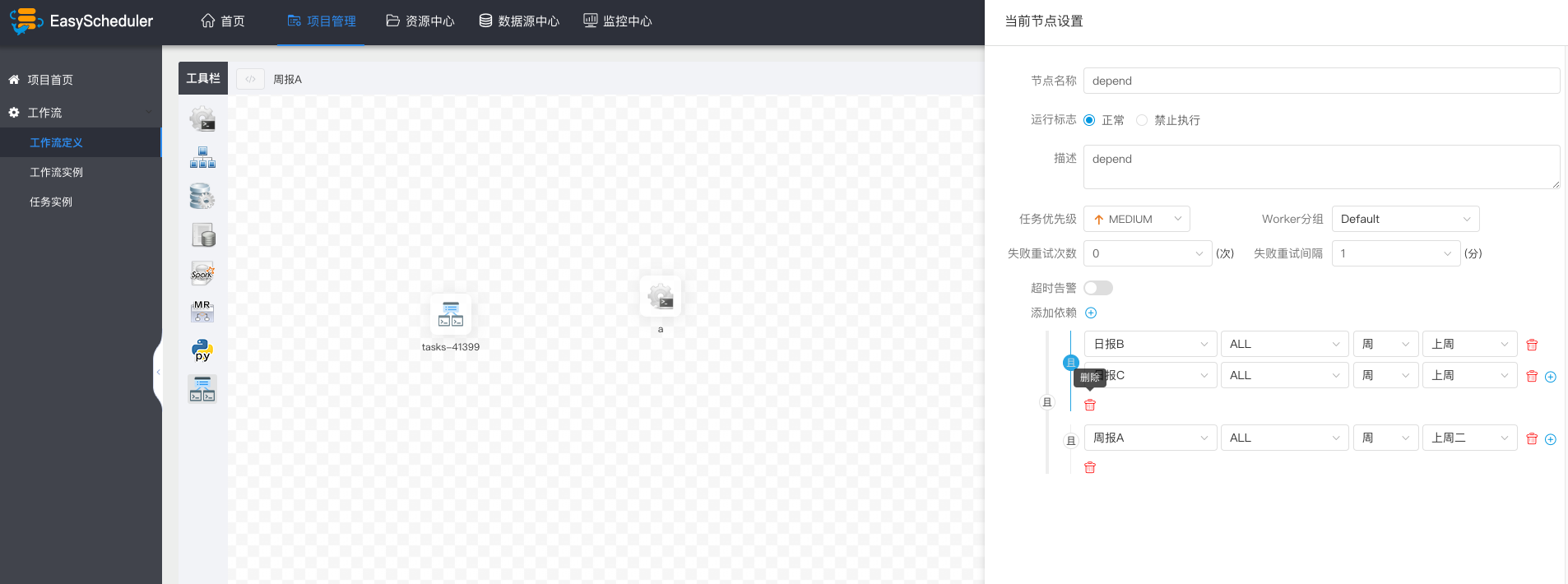 -
-
- 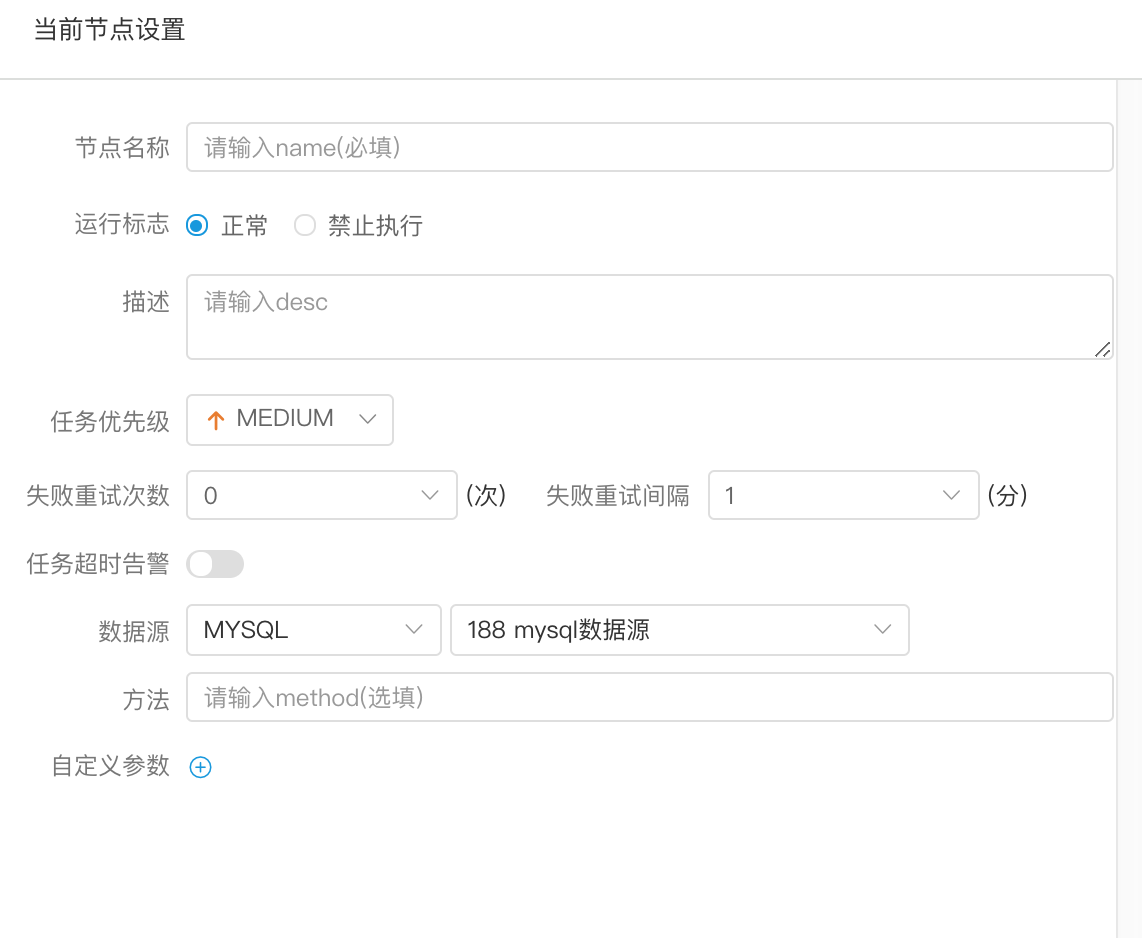 -
-
- 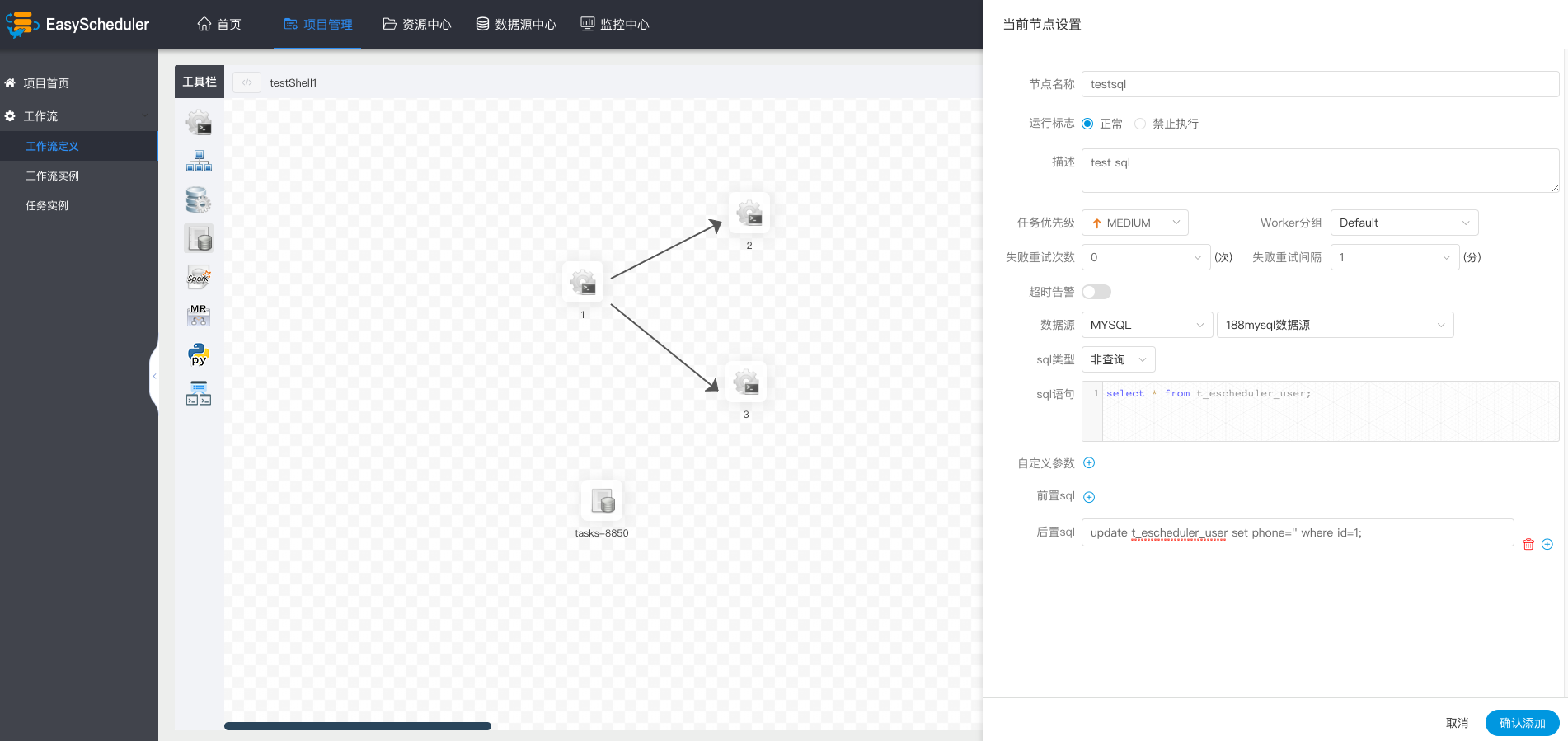 -
-
- 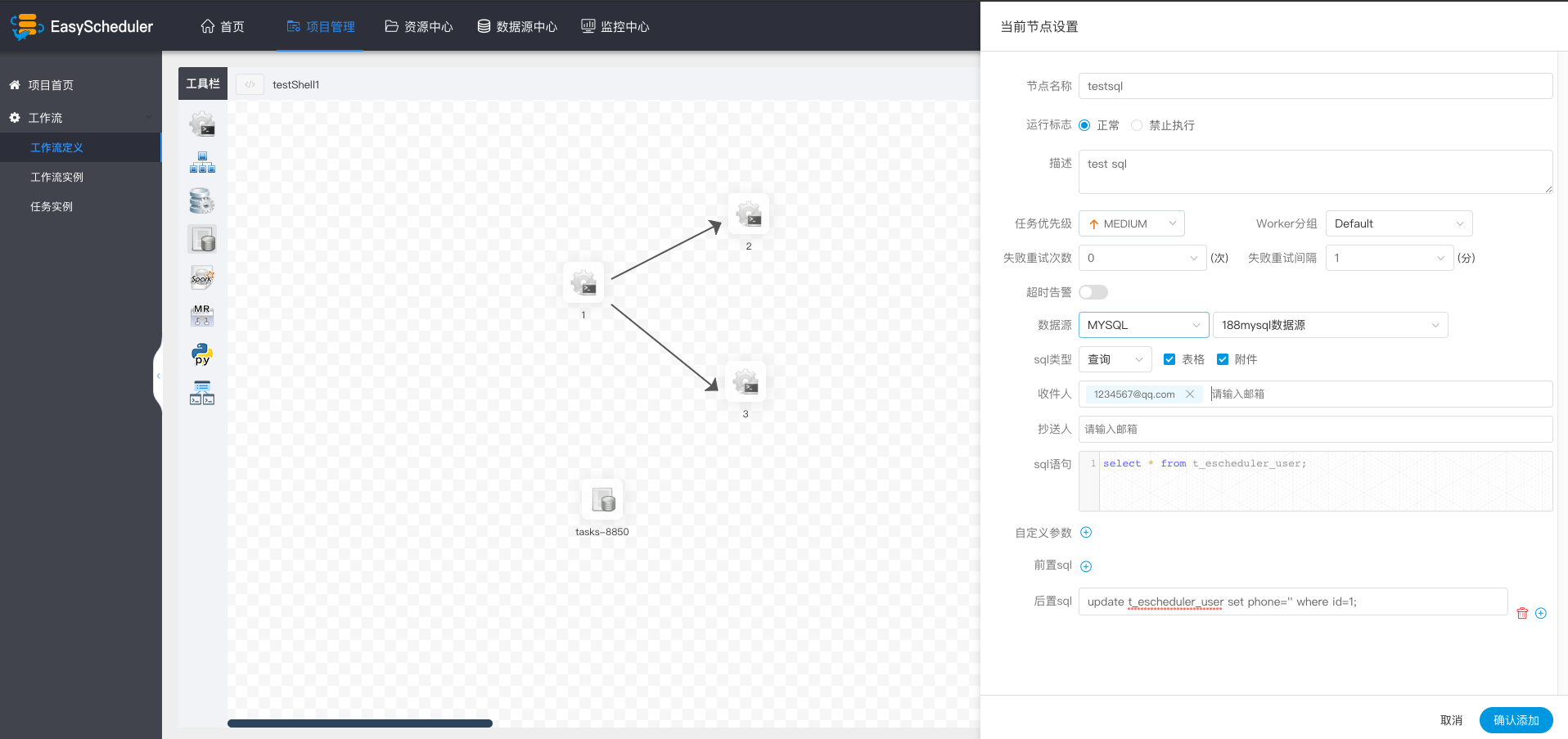 -
-
- 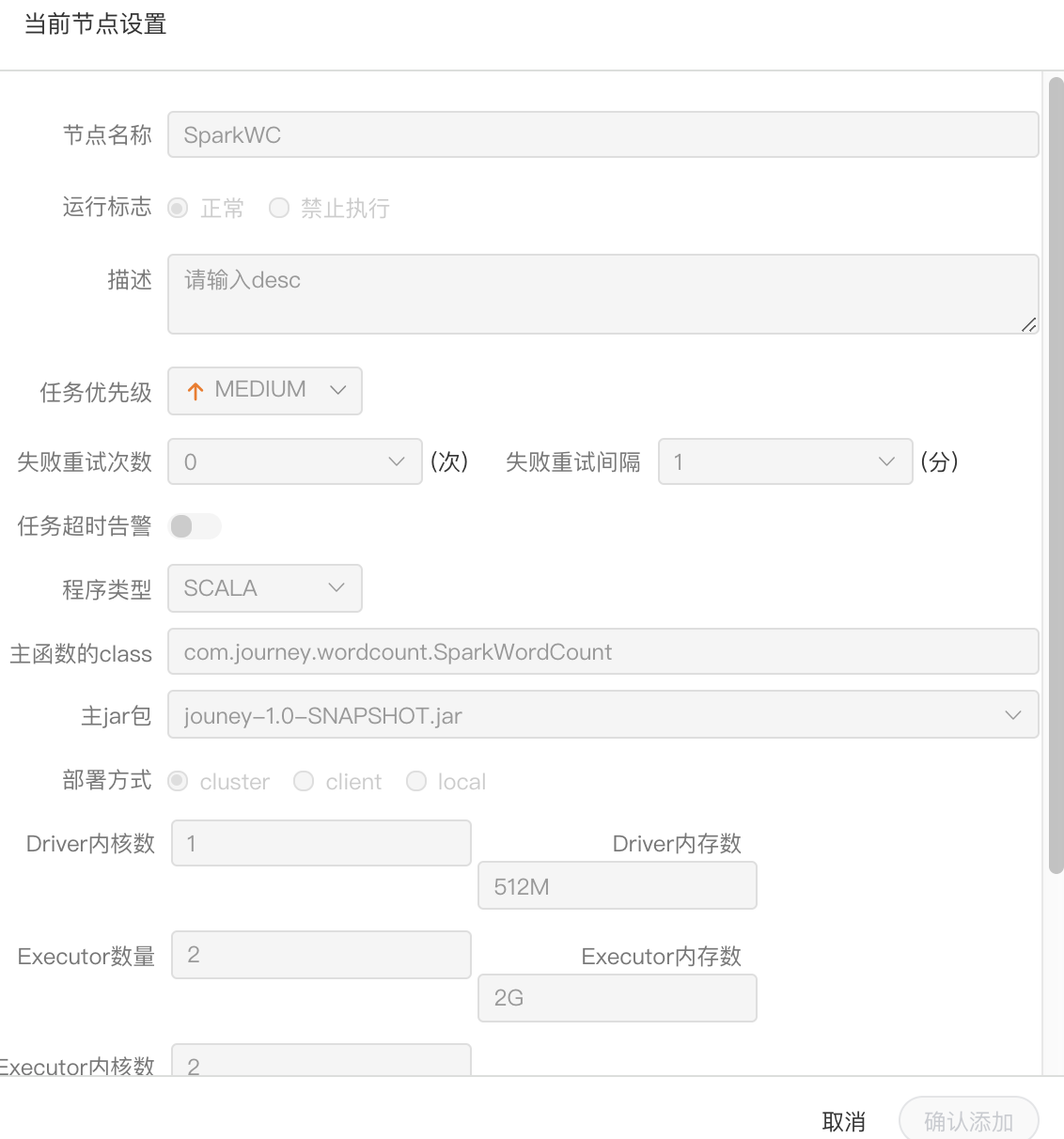 -
-
- 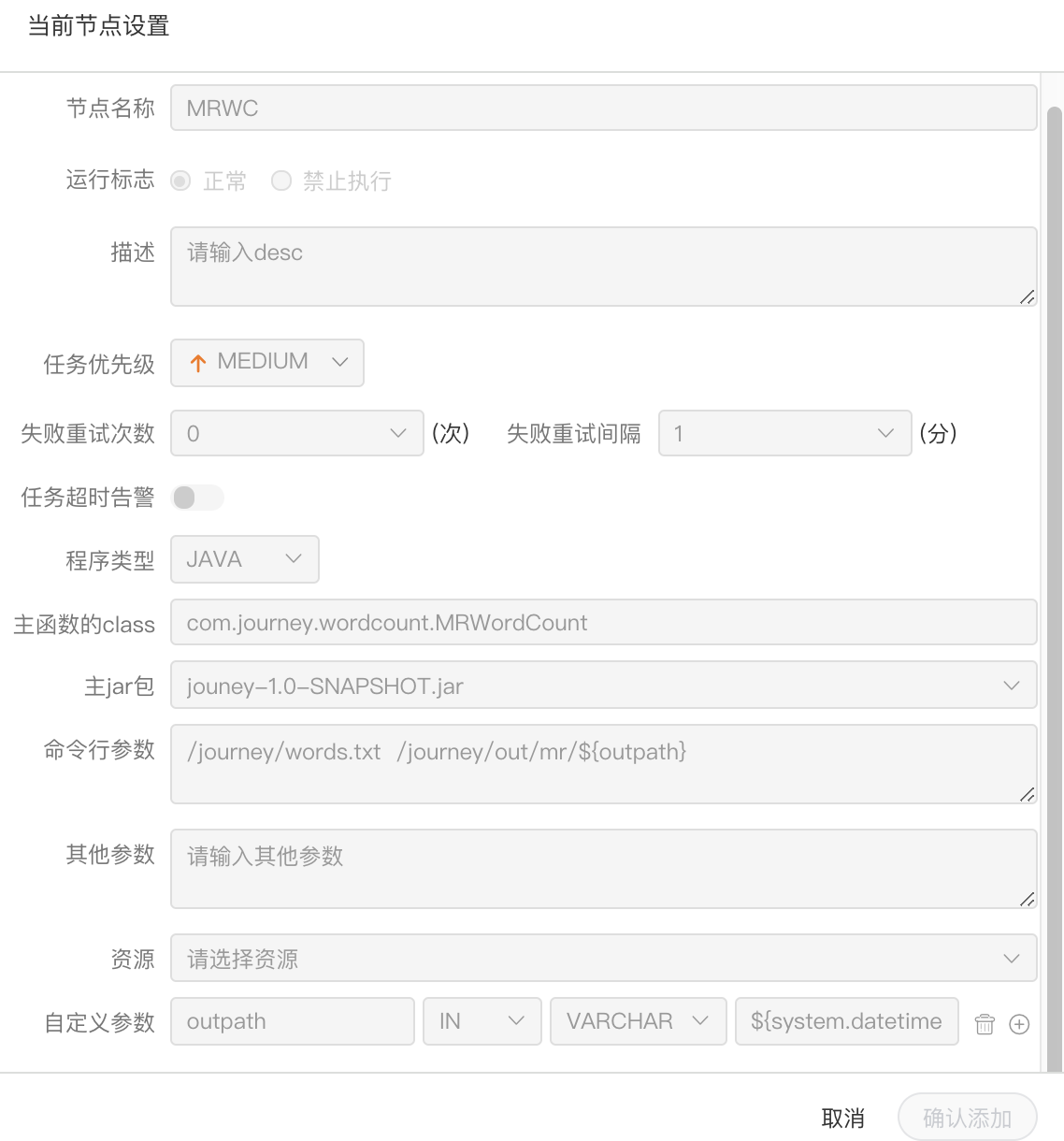 -
-
- 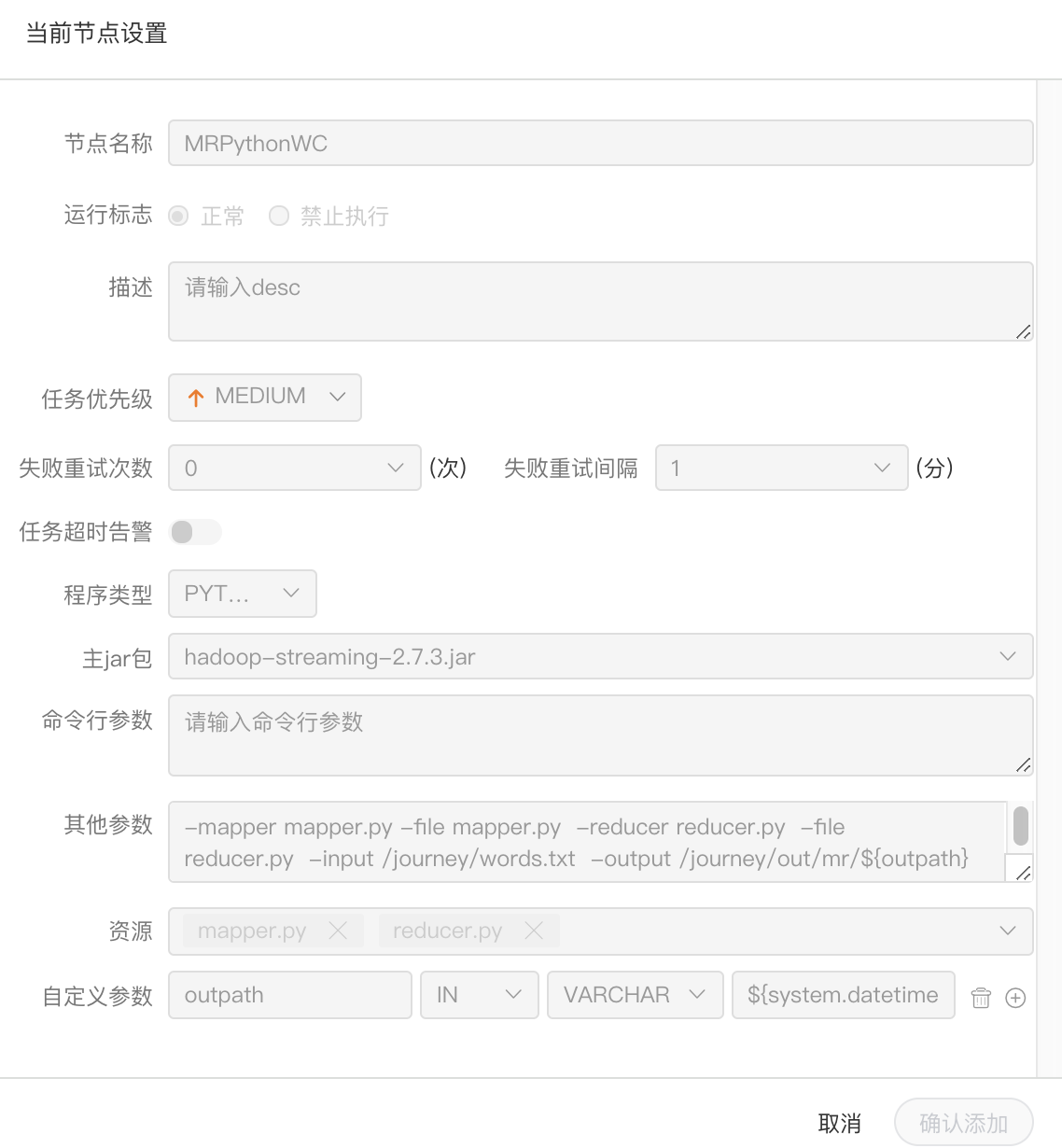 -
-
- 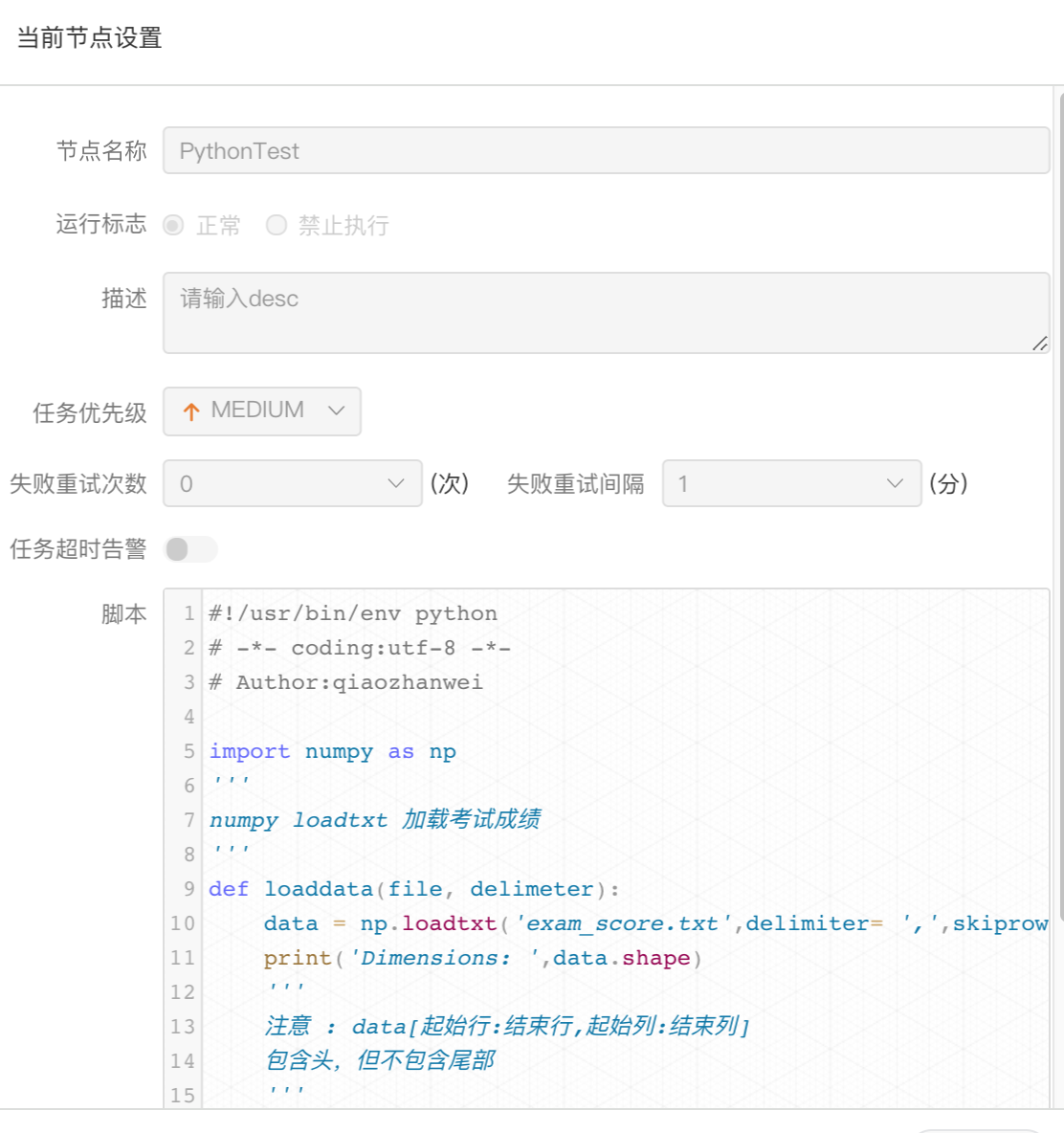 -
-
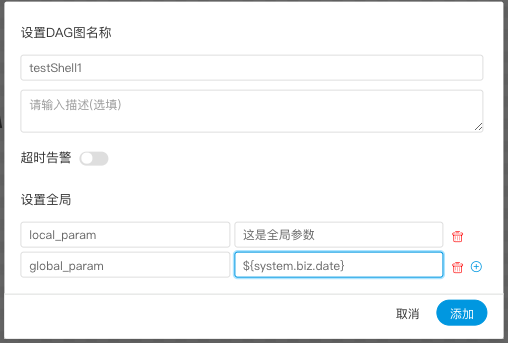
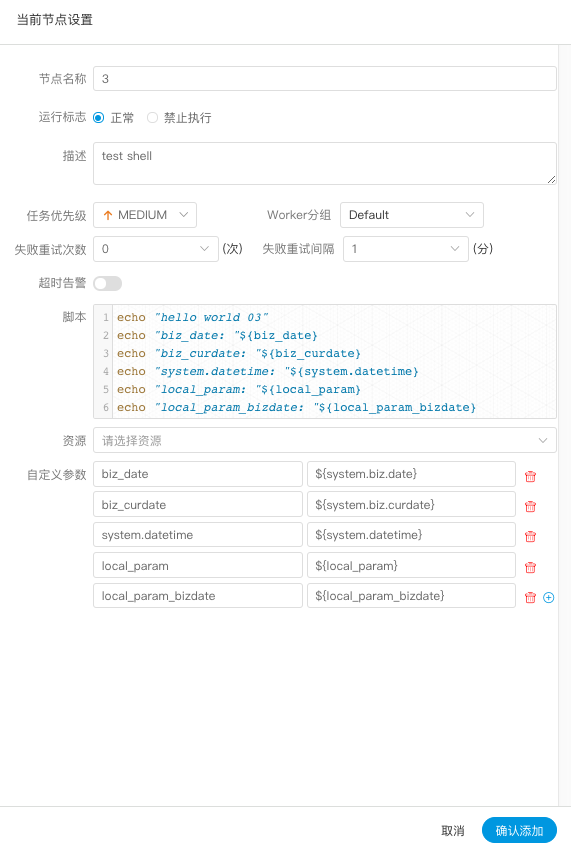
| 变量 | 含义 |
|---|---|
| ${system.biz.date} | -日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 | -
| ${system.biz.curdate} | -日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 | -
| ${system.datetime} | -日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 | -
-  -
-
-  -
-
-
-
- dag示例 -
- - -**流程定义**:通过拖拽任务节点并建立任务节点的关联所形成的可视化**DAG** - -**流程实例**:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成,流程定义每运行一次,产生一个流程实例 - -**任务实例**:任务实例是流程定义中任务节点的实例化,标识着具体的任务执行状态 - -**任务类型**: 目前支持有SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中子 **SUB_PROCESS** 也是一个单独的流程定义,是可以单独启动执行的 - -**调度方式:** 系统支持基于cron表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 **恢复被容错的工作流** 和 **恢复等待线程** 两种命令类型是由调度内部控制使用,外部无法调用 - -**定时调度**:系统采用 **quartz** 分布式调度器,并同时支持cron表达式可视化的生成 - -**依赖**:系统不单单支持 **DAG** 简单的前驱和后继节点之间的依赖,同时还提供**任务依赖**节点,支持**流程间的自定义任务依赖** - -**优先级** :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出 - -**邮件告警**:支持 **SQL任务** 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知 - -**失败策略**:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,**继续**是指不管并行运行任务的状态,直到流程失败结束。**结束**是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束 - -**补数**:补历史数据,支持**区间并行和串行**两种补数方式 - -### 2.系统架构 - -#### 2.1 系统架构图 -
-  -
-
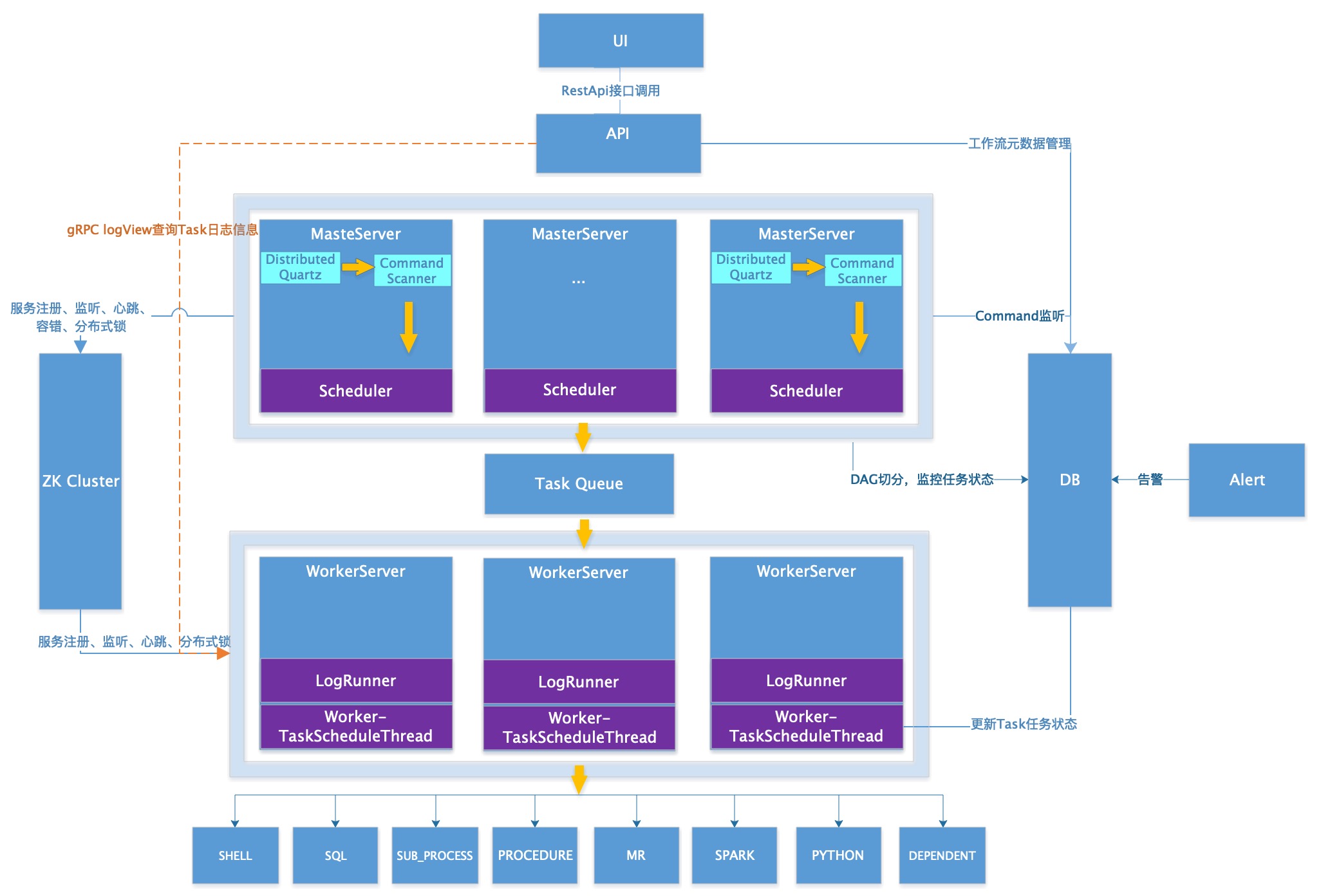
- 系统架构图 -
- - -#### 2.2 架构说明 - -* **MasterServer** - - MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 - MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 - - ##### 该服务内主要包含: - - - **Distributed Quartz**分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作 - - - **MasterSchedulerThread**是一个扫描线程,定时扫描数据库中的 **command** 表,根据不同的**命令类型**进行不同的业务操作 - - - **MasterExecThread**主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理 - - - **MasterTaskExecThread**主要负责任务的持久化 - -* **WorkerServer** - - WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 - ##### 该服务包含: - - **FetchTaskThread**主要负责不断从**Task Queue**中领取任务,并根据不同任务类型调用**TaskScheduleThread**对应执行器。 - - - **LoggerServer**是一个RPC服务,提供日志分片查看、刷新和下载等功能 - -* **ZooKeeper** - - ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 - 我们也曾经基于Redis实现过队列,不过我们希望EasyScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。 - -* **Task Queue** - - 提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,实际上我们压测过百万级数据存队列,对系统稳定性和性能没影响。 - -* **Alert** - - 提供告警相关接口,接口主要包括**告警**两种类型的告警数据的存储、查询和通知功能。其中通知功能又有**邮件通知**和**SNMP(暂未实现)**两种。 - -* **API** - - API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 - 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。 - -* **UI** - - 系统的前端页面,提供系统的各种可视化操作界面,详见**[系统使用手册](系统使用手册.md)**部分。 - -#### 2.3 架构设计思想 - -##### 一、去中心化vs中心化 - -###### 中心化思想 - -中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色: -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-