| .. | ||
| images | ||
| generate_baichuan_13B_tp8_pp1.sh | ||
| pretrain_baichuan_ptd_13B.sh | ||
| pretrain_baichuan_zero_7B.sh | ||
| README.md | ||
Baichuan-13B
Contents
Pre-Training
Here's a quick summary of training baichuan-13B:
| Hardware | 96 64GB Altas 910B NPUs |
| Software | AscendSpeed |
| Dataset | alpaca-data-conversation |
Datasets
Vicuna is created by fine-tuning a LLaMA base model using approximately 70K user-shared conversations gathered from ShareGPT.com with public APIs. To ensure data quality, we convert the HTML back to markdown and filter out some inappropriate or low-quality samples. Additionally, we divide lengthy conversations into smaller segments that fit the model's maximum context length. For detailed instructions to clean the ShareGPT data, check out here.
Due to some concerns, we may not release the data at the moment. If you would like to try the fine-tuning code, you can try to run it with our preprocessed alpaca dataset (originally from here).
Script
1.Install AscendSpeed requirement environment.
2.Download alpaca-data-conversation dataset:https://github.com/lm-sys/FastChat/blob/v0.1.10/playground/data/alpaca-data-conversation.json
3.Config Baichuan-13B pre-training script: AscendSpeed/examples/baichuan/pretrain_baichuan_ptd_13B.sh
# This is an example: training llama using PTD/
# The number of parameters is not aligned
export LD_LIBRARY_PATH=/usr/local/lib:/root/miniconda3/lib:$LD_LIBRARY_PATH
export HCCL_CONNECT_TIMEOUT=1200
# Change for multinode config
MASTER_ADDR=localhost
MASTER_PORT=12892
NNODES=1
NODE_RANK=0
NPUS_PER_NODE=8
WORLD_SIZE=$(($NPUS_PER_NODE*$NNODES))
GLOBAL_BATCH=32
MICRO_BATCH=1
DATA_PATH=./data/baichuan_text
TOKENIZER_PATH=./tokenizer
CHECKPOINT_PATH=./ckpt
LOAD_PATH=./weight
DISTRIBUTED_ARGS="--nproc_per_node $NPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
logfile=$(date +%Y%m%d)_$(date +%H%M%S)
rm -rf kernel_meta*
# Main script
python -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_baichuan.py \
--DDP-impl local \
--tensor-model-parallel-size 8 \
--pipeline-model-parallel-size 1 \
--sequence-parallel \
--num-layers 40 \
--hidden-size 5120 \
--ffn-hidden-size 13696 \
--num-attention-heads 40 \
--micro-batch-size $MICRO_BATCH \
--global-batch-size $GLOBAL_BATCH \
--seq-length 4096 \
--max-position-embeddings 4096 \
--train-iters 100000 \
--save $CHECKPOINT_PATH \
--load $LOAD_PATH \
--data-path $DATA_PATH \
--tokenizer-name-or-path $TOKENIZER_PATH \
--tokenizer-not-use-fast \
--data-impl mmap \
--split 949,50,1 \
--make-vocab-size-divisible-by 8 \
--distributed-backend nccl \
--lr 1e-6 \
--lr-decay-style cosine \
--min-lr 1e-8 \
--weight-decay 1e-1 \
--position-embedding-type alibi \
--clip-grad 1.0 \
--initial-loss-scale 8188.0 \
--seed 1234 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--adam-eps 1.0e-5 \
--log-interval 1 \
--save-interval 1000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16 | tee logs/loss_${logfile}.log
4.Launch Baichuan-13B pre-training script: AscendSpeed/examples/baichuan/pretrain_baichuan_ptd_13B.sh
bash examples/baichuan/pretrain_baichuan_ptd_13B.sh
There is an hourly pulse checking script running that checks that the training is either running or scheduled.
The Training log will look like these:
TODO
Performance
Machine performance
The performance of the NPUs in Ascend910 B1 64GB and GPUs is A800:
| Device | Model | total Iterations | throughput rate (samples/s/p) | throughput rate (tokens/s/p) | single-step time (s/step) | floating point operation (TFLOPs/s) |
|---|---|---|---|---|---|---|
| GPUs | Baichuan-13B | 1000 | 1.535 | 785 | 20.852 | 68.39 |
| NPUs | Baichuan-13B | 1000 | 1.928 | 1024 | 16.067 | 89.37 |
Notes:
- Baichuan-13B model trained on alpaca-data-conversation on a single machine with 8 NPUs
Here's a hardware summary of pre-training Baichuan-13B:
| Hardware | Value |
|---|---|
| CPU | 4xKunPeng920@3.0GHz,64 Core Pre Socket 256CPUS |
| RAM | 32x32 GB DDR4 |
| NPU | 8 x Ascend910B1 64G |
Here's a software summary of pre-training Baichuan-13B:
| Software | Version |
|---|---|
| OS | Euler OS release 2.0(SP10) |
| uname | aarch64 |
| Python | 3.7.16 |
| driver | 23.0.RC3.B051 |
| firmware | 23.0.RC3.B051 |
| CANN | 7.0.RC1 |
| binary arithmetic package | Ascend-cann-kernels-910b_7.0.T8_linux |
| torch | 1.11.0 |
| torch_npu | 1.11.0.post4-20230915 |
| deepspeed | 0.9.2 |
| deepspeed-npu | 0.1 |
| transformers | 4.30.2 |
| Ascendspeed | 2023-7-21 |
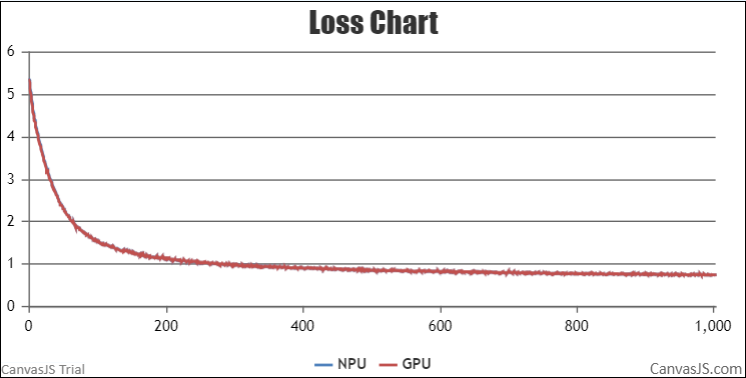
Accuracy of the loss
NPU vs GPU loss.
The NPU runs smoothly, the resource usage is stable, no errors are reported in the middle of the process, the Loss is on a decreasing trend, and the convergence speed is as expected.
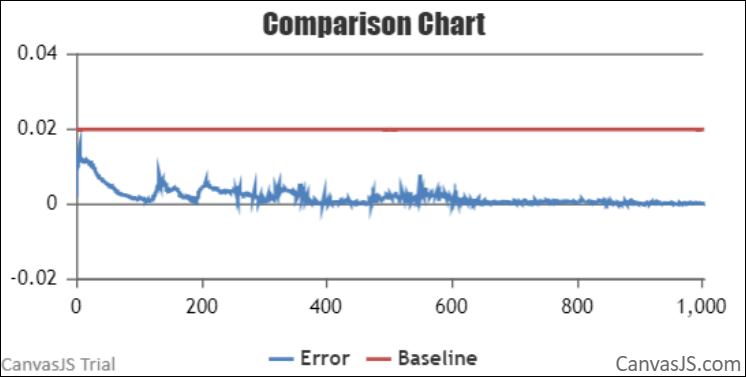
NPU vs GPU loss relative error.
The relative error between NPU and GPU Loss is less than 0.02 throughout, as expected.
Fine-tune and Evaluation
TODO
Inference
We support AscendSpeed Inference for text generation with Baichuan-13B.
Model weights
We provide scripts that support converting pretrained weights into weights that AscendSpeed can load and used for inference. Download the Baichuan-13B checkpoint from here, make sure all chunks are downloaded completely, then use the following command to convert them into checkpoints that AscendSpeed can load.
#!/bin/bash
SCRIPT_PATH=./tools/ckpt_convert/llama/convert_weights_from_huggingface.py
python $SCRIPT_PATH \
--input-model-dir "your huggingface checkpoint path" \
--output-model-dir "your ascendspeed checkpoint path" \
--tensor-model-parallel-size 8 \
--pipeline-model-parallel-size 1 \
--type 13B
Set CHECKPOINT_PATH in ./examples/baichuan/generate_baichuan_13B_tp8_pp1.sh to the path of the extracted folder. Since the checkpoint file is large, it is recommended to use the SSD or RAM disk to reduce the checkpoint loading time.
Script
We generate text samples using the generate_baichuan_13B_tp8_pp1.sh script. Inference different from pre-training, such as we need to Load pre training checkpoint and the length of the output samples:
bash ./examples/baichuan/generate_baichuan_13B_tp8_pp1.sh
Alternatively you can also use DeepSpeed from source:
TODO: XXXX
Citation
You may also consider original work in your reference.