|
|
||
|---|---|---|
| .. | ||
| evaluate_baichuan2_7B_ptd.sh | ||
| evaluate_baichuan2_13B_ptd.sh | ||
| generate_baichuan2_7b_ptd.sh | ||
| generate_baichuan2_13b_ptd.sh | ||
| pretrain_baichuan2_ptd_7B.sh | ||
| pretrain_baichuan2_ptd_13B.sh | ||
| README_en.md | ||
| README.md | ||
BaiChuan2
简体中文 | English
Contents
Baichuan2-7B
Training
Here's a hardware summary of pre-training Baichuan2-7B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout -f bcce6f cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install torch and torch_npu pip install torch-2.1.0-cp38-cp38m-linux_aarch64.whl pip install torch_npu-2.1.0.XXX-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify the path according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install AscendSpeed git clone https://gitee.com/ascend/AscendSpeed.git cd AscendSpeed git checkout 224ae35e8fc96778f957029d1371ddb623452a50 pip install -r requirements.txt pip3 install -e . cd .. # install other packages pip install -r requirements.txt -
Prepare pretrained weights Download the Baichuan2-7B checkpoint from here
mkdir ./model_from_hf/Baichuan2-7B/ cd ./model_from_hf/Baichuan2-7B/ wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/config.json wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/configuration_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/generation_utils.py wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/modeling_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00001-of-00002.bin wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model-00002-of-00002.bin wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/pytorch_model.bin.index.json wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/quantizer.py wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/special_tokens_map.json wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenization_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer.model wget https://huggingface.co/baichuan-inc/Baichuan2-7B-Base/resolve/main/tokenizer_config.json cd ../../ -
Weights convert
In order to adapt to the baichuan2-7B model, the following script is used to convert the model pre-training weights. (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --load-dir ./model_from_hf/Baichuan2-7B/ \ --save-dir ./model_weights/Baichuan2-7B-v0.1-tp8-pp1/ \ --tokenizer-model ./model_from_hf/Baichuan2-7B/tokenizer.model \ --params-dtype bf16 \ --w-pack TrueAny Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./model_weights/Baichuan2-7B-v0.1-tp8-pp1/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --w-pack True \ --save-dir ./model_from_hf/Baichuan2-7B/ # <-- Fill in the original HF model path here, new weights will be saved in ./model_from_hf/Baichuan2-7B/mg2hg/ -
Prepare dataset
Download the Baichuan2-7B-Base datasets from here
# download datasets cd ./dataset/ wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/Baichuan2-7B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Baichuan2-7B/ \ --output-prefix ./dataset/Baichuan2-7B/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF -
Config Baichuan2-7B pre-training script : examples/baichuan2/pretrain_baichuan2_ptd_7B.sh
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify script orign dataset path according to your own dataset path CKPT_SAVE_DIR="./ckpt/Baichuan2-7B/" DATA_PATH="./dataset/Baichuan2-7B/alpaca_text_document" TOKENIZER_MODEL="./model_from_hf/Baichuan2-7B/tokenizer.model" CKPT_LOAD_DIR="./model_weights/Baichuan2-7B-v0.1-tp8-pp1/" -
Launch Baichuan2-7B pre-training script: examples/baichuan2/pretrain_baichuan2_ptd_7B.sh
bash examples/baichuan2/pretrain_baichuan2_ptd_7B.shNote: If using multi machine training, it is necessary to set up multi machine data sharing, and non primary nodes can read the primary node data through data sharing. Alternatively, directly copy the data generated by the master node to non master nodes.
Performance
Machine performance
The performance of Baichuan2-7B in Ascend NPU and Reference:
| Device | Model | total Iterations | throughput rate (samples/s) | throughput rate (tokens/s/p) | single-step time (s/step) |
|---|---|---|---|---|---|
| NPUs | Baichuan2-7B | 1000 | 5.2 | 2664 | 12.3 |
| Reference | Baichuan2-7B | 1000 | -- | 3969 | -- |
Inference
Config baichuan2-7B inference script: examples/baichuan2/generate_baichuan2_7b_ptd.sh
# modify the script according to your own ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Baichuan2-7B-v0.1-tp8-pp1/"
TOKENIZER_PATH="./model_from_hf/Baichuan2-7B/"
Launch baichuan2-7B inference script: examples/baichuan2/generate_baichuan2_7b_ptd.sh
bash examples/baichuan2/generate_baichuan2_7b_ptd.sh
Some inference samples are as follows:
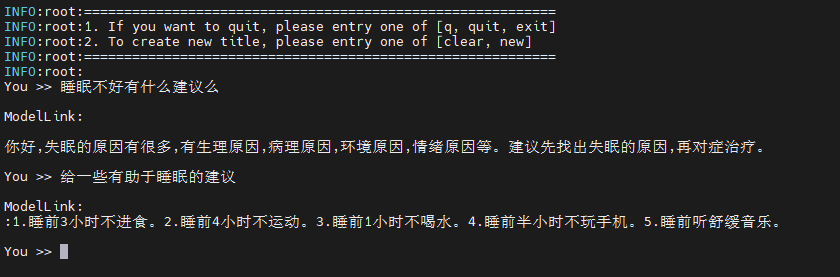
Evaluation
We use the boolq benchmark to evaluate our model. Benchmark Download.
# config origin weight and vocab file path
CHECKPOINT=<origin-ckpt-path>
TOKENIZER_PATH=<tokenizer-path>
# config tasks and dataset path
DATA_PATH="./boolq/"
TASK="boolq"
bash ./examples/baichuan2/evaluate_baichuan2_13B_ptd.sh
| Task | Subset | Model | NPU | OpenSource |
|---|---|---|---|---|
| Boolq | test | Baichuan2-7B | 0.7 | 0.632 |
Baichuan2-13B
Training
Here's a hardware summary of pre-training Baichuan2-13B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout -f bcce6f cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install torch and torch_npu pip install torch-2.1.0-cp38-cp38m-linux_aarch64.whl pip install torch_npu-2.1.0.XXX-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify the path according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install AscendSpeed git clone https://gitee.com/ascend/AscendSpeed.git cd AscendSpeed git checkout 224ae35e8fc96778f957029d1371ddb623452a50 pip install -r requirements.txt pip3 install -e . cd .. # install other packages pip install -r requirements.txt -
Prepare pretrained weights
Download the Baichuan2-13B checkpoint from here
mkdir ./model_from_hf/Baichuan2-13B/ cd ./model_from_hf/Baichuan2-13B/ wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/config.json wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/configuration_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/generation_utils.py wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/modeling_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/pytorch_model-00001-of-00003.bin wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/pytorch_model-00002-of-00003.bin wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/pytorch_model-00003-of-00003.bin wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/pytorch_model.bin.index.json wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/quantizer.py wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/special_tokens_map.json wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/tokenization_baichuan.py wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/tokenizer_config.json wget https://huggingface.co/baichuan-inc/Baichuan2-13B-Base/resolve/main/tokenizer.model cd ../../ -
Weights convert
In order to adapt to the baichuan2-13B model, the following script is used to convert the model pre-training weights. (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --load-dir ./model_from_hf/Baichuan2-13B/ \ --save-dir ./model_weights/Baichuan2-13B-v0.1-tp8-pp1/ \ --tokenizer-model ./model_from_hf/Baichuan2-13B/tokenizer.model \ --params-dtype bf16 \ --w-pack TrueAny Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./model_weights/Baichuan2-13B-v0.1-tp8-pp1/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --w-pack True \ --save-dir ./model_from_hf/Baichuan2-13B/ # <-- Fill in the original HF model path here, new weights will be saved in ./model_from_hf/Baichuan2-13B/mg2hg/ -
Prepare dataset
Download the Baichuan2-13B datasets from here
cd dataset/ wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. mkdir ./dataset/Baichuan2-13B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Baichuan2-13B/ \ --output-prefix ./dataset/Baichuan2-13B/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF -
Config Baichuan2-13B pre-training script: examples/baichuan2/pretrain_baichuan2_ptd_13B.sh
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify script orign dataset path according to your own dataset path CKPT_SAVE_DIR="./ckpt/Baichuan2-13B/" DATA_PATH="./dataset/Baichuan2-13B/alpaca_text_document" TOKENIZER_MODEL="./model_from_hf/Baichuan2-13B/tokenizer.model" CKPT_LOAD_DIR="./model_weights/Baichuan2-13B-v0.1-tp8-pp1/" -
Launch Baichuan2-13B pre-training script: examples/baichuan2/pretrain_baichuan2_ptd_13B.sh
bash examples/baichuan2/pretrain_baichuan2_ptd_13B.shNote: If using multi machine training, it is necessary to set up multi machine data sharing, and non primary nodes can read the primary node data through data sharing. Alternatively, directly copy the data generated by the master node to non master nodes.
Performance
Machine performance
The performance of the Baichuan2-13B in Ascend NPU and Reference:
| Device | Model | total Iterations | throughput rate (samples/s/p) | throughput rate (tokens/s/p) | single-step time (s/step) |
|---|---|---|---|---|---|
| NPUs | Baichuan2-13B | 1000 | - | 1668 | - |
| Reference | Baichuan2-13B | - | - | 2062 | - |
Inference
Config baichuan2-13B inference script: examples/baichuan2/generate_baichuan2_13b_ptd.sh
# modify the script according to your own ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Baichuan2-13B-v0.1-tp8-pp1/"
TOKENIZER_PATH="./model_from_hf/Baichuan2-13B/"
Launch baichuan2-13B inference script: examples/baichuan2/generate_baichuan2_13b_ptd.sh
bash examples/baichuan2/generate_baichuan2_13b_ptd.sh
Some inference samples are as follows:

Evaluation
We use the boolq benchmark to evaluate our model. Benchmark Download.
# config origin weight and vocab file path
CHECKPOINT=<origin-ckpt-path>
TOKENIZER_PATH=<tokenizer-path>
# config tasks and dataset path
DATA_PATH="./boolq/"
TASK="boolq"
bash ./examples/baichuan2/evaluate_baichuan2_13B_ptd.sh
| Task | Subset | Model | NPU | OpenSource |
|---|---|---|---|---|
| Boolq | test | Baichuan2-13B | 0.78 | 0.67 |