mirror of
https://gitee.com/ascend/ModelLink.git
synced 2024-12-05 05:17:40 +08:00
|
|
||
|---|---|---|
| ci | ||
| docs | ||
| examples | ||
| modellink | ||
| sources/images | ||
| tests | ||
| .gitignore | ||
| convert_ckpt.py | ||
| evaluation.py | ||
| inference.py | ||
| LICENSE | ||
| OWNERS | ||
| posttrain_gpt.py | ||
| preprocess_data.py | ||
| pretrain_gpt.py | ||
| README.md | ||
| requirements.txt | ||
| SECURITYNOTE.md | ||
| setup.py | ||
| Third_Party_Open_Source_Software_Notice | ||
![]()


MindSpeed-LLM作为昇腾大模型训练框架,旨在为华为 昇腾芯片 提供端到端的大语言模型训练方案, 包含分布式预训练、分布式指令微调、分布式偏好对齐以及对应的开发工具链。
MindSpeed-LLM 大模型训练框架功能特性概览
训练方案
- 分布式预训练:预训练方案/并行策略/加速算法/融合算子
- 分布式指令微调:指令微调方案/Prompt模板/动态padding/长序列方案
- 分布式偏好对齐:偏好对齐方案/DPO/奖励模型
- 开发工具链:权重转换/数据处理/分布式推理/分布式评估
- 昇腾工具链:Profiling采集/确定性计算/高可用
预置模型
- MindSpeed-LLM 100+ 预置大模型及其权重下载地址
- MindSpeed-LLM 使用指南
- 基于 Megatron-LM + MindSpeed-LLM 训练自定义大模型
研发中特性与模型
- O1: https://openai.com/index/learning-to-reason-with-llms/
- COT:Chain-of-Thought Reasoning without Prompting
- GRPO: DeepSeek Reinforcement Learning
- Search: AlphaZero-Like Tree-Search
- PPO: Proximal Policy Optimization Algorithms
- PRM: Reward Modeling as Next-Token Prediction
- QLoRA: Efficient Finetuning of Quantized LLMs
- Mamba2: Transformers are SSMs
- Mamba-Hybird: An Empirical Study of Mamba-based Language Models
- DeepSeek-V2: 236B
- DeepSeek-V2.5: 236B
- QWen2.5: 7B, 14B, 32B, 72B
- InternLM2.5: 1.8B, 7B, 20B
- MiniCPM3: 4B
- Yi1.5: 6B, 9B, 34B
- Phi3.5: MoE, Mini
分布式预训练
【预训练实测集群性能与线性度】
| 模型系列 | 实验模型 | 硬件信息 | 集群规模 | MFU |
|---|---|---|---|---|
| LLAMA2 | LLAMA2-7B | Atlas 900 A2 PODc | 1x8 | 65.8% |
| LLAMA2-13B | Atlas 900 A2 PODc | 1x8 | 57.4% | |
| LLAMA2-70B | Atlas 900 A2 PODc | 4x8 | 53.9% |
基于 GPT3-175B 稠密大模型,从128颗 NPU 扩展到 7968颗 NPU 进行 MFU 与线性度实验,下图是实验数据:
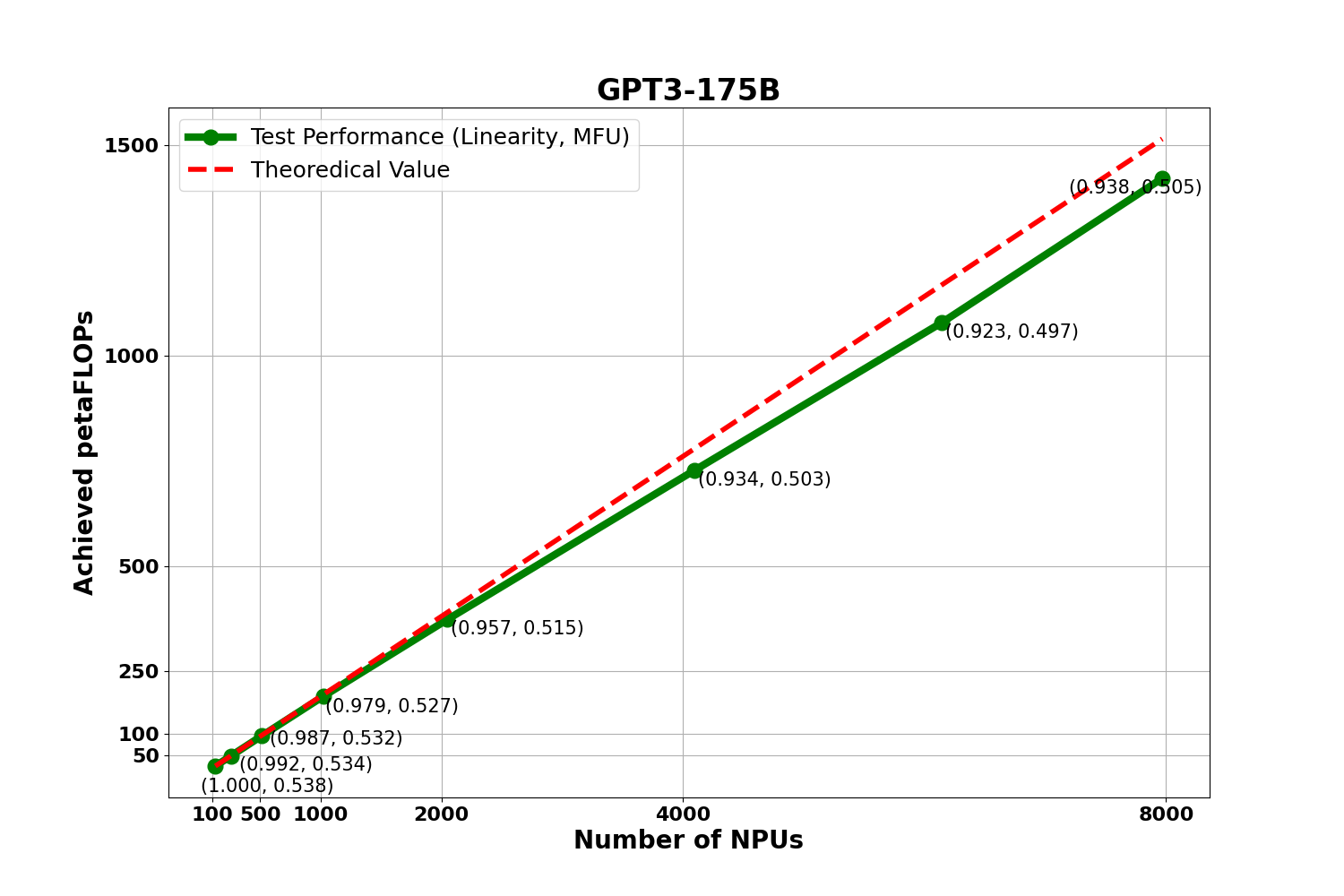
图中呈现了对应集群规模下的 MFU 值与集群整体的 线性度情况. 计算公式已经放到社区,点击链接可进行参考:MFU计算公式,线性度计算公式.
【并行策略/加速算法/显存优化/融合算子】
| 场景 | 特性名称 | Mcore | Legacy | 贡献方 |
|---|---|---|---|---|
| SPTD并行 | 张量并行 | ✅ | ✅ | 【昇腾】 |
| 流水线并行 | ✅ | ✅ | 【昇腾】 | |
| 虚拟流水并行 | ✅ | ✅ | 【昇腾】 | |
| 序列并行 | ✅ | ✅ | 【昇腾】 | |
| 长序列并行 | Ascend Ring Attention 长序列并行 | ✅ | ❌ | 【昇腾】 |
| Ulysses 长序列并行 | ✅ | ❌ | 【昇腾】 | |
| 混合长序列并行 | ✅ | ❌ | 【昇腾】 | |
| MOE | MOE 专家并行 | ✅ | ❌ | 【昇腾】 |
| MOE 重排通信优化 | ✅ | ❌ | 【计算研究部】 | |
| 显存优化 | 参数副本复用 | ✅ | ✅ | 【计算算法部】 |
| 分布式优化器 | ✅ | ✅ | 【昇腾】 | |
| Swap Attention | ✅ | ✅ | 【计算研究部】 | |
| 重计算 | ✅ | ✅ | 【计算研究部】 | |
| 融合算子 | Flash attention | ✅ | ✅ | 【昇腾】 |
| Fused rmsnorm | ✅ | ✅ | 【昇腾】 | |
| Fused swiglu | ✅ | ✅ | 【昇腾】 | |
| Fused rotary position embedding | ✅ | ✅ | 【昇腾】 | |
| GMM | ✅ | ❌ | 【昇腾】 | |
| 通信掩盖 | 梯度reduce通算掩盖 | ✅ | ✅ | 【昇腾】 |
| Recompute in advance | ✅ | ❌ | 【昇腾】 | |
| 权重all-gather通算掩盖 | ✅ | ❌ | 【昇腾】 | |
| MC2 | ✅ | ✅ | 【昇腾】 |
分布式指令微调
【指令微调实测性能】
| 模型 | 硬件 | 集群 | 框架 | 方案 | 序列 | 性能 |
|---|---|---|---|---|---|---|
| llama2-7B | Atlas 900 A2 PODc | 1x8 | MindSpeed-LLM + NPU | 全参 | dynamic | 45.7 samples/s |
| DeepSpeed + NPU | 全参 | dynamic | 40.4 samples/s | |||
| DeepSpeed + 参考 | 全参 | dynamic | 46.5 samples/s | |||
| MindSpeed-LLM + NPU | 全参 | 16K | 1.455 samples/s | |||
| DeepSpeed + 参考 | 全参 | 16K | 1.003 samples/s | |||
| MindSpeed-LLM + NPU | 全参 | 32K | 0.727 samples/s | |||
| DeepSpeed + 参考 | 全参 | 32K | 0.4 samples/s | |||
| llama2-13B | Atlas 900 A2 PODc | 1x8 | MindSpeed-LLM + NPU | 全参 | dynamic | 28.4 samples/s |
| DeepSpeed + NPU | 全参 | dynamic | 17.8 samples/s | |||
| DeepSpeed + 参考 | 全参 | dynamic | 24.9 samples/s | |||
| llama2-70B | Atlas 900 A2 PODc | 1x8 | MindSpeed-LLM + NPU | LoRA | dynamic | 11.72 samples/s |
| DeepSpeed + 参考 | LoRA | dynamic | 3.489 samples/s |
【指令微调特性】
| 场景 | 特性名称 | Mcore | Legacy | 贡献方 |
|---|---|---|---|---|
| 微调数据集支持格式 | Alpaca 风格 | ✅ | ✅ | 【昇腾】 |
| ShareGPT 风格 | ✅ | ✅ | 【昇腾】 | |
| 全参微调 | 单样本微调 | ✅ | ✅ | 【昇腾】 |
| 多样本 pack | ✅ | ✅ | 【NAIE】 | |
| 多轮对话 | ✅ | ✅ | 【昇腾】 | |
| 长序列方案 | ✅ | ✅ | 【NAIE】 | |
| 低参微调 | LoRA 微调 | ✅ | ✅ | 【NAIE】 |
| CCLoRA | ✅ | ✅ | 【计算算法部】 |
分布式偏好对齐
【偏好对齐特性】
| 场景 | 特性名称 | Mcore | Legacy | 贡献方 |
|---|---|---|---|---|
| 偏好对齐 | Offline DPO | ✅ | ❌ | 【NAIE】 |
| 奖励模型 | ORM | ✅ | ❌ | 【昇腾】 |
开发工具链
| 场景 | 特性 | Mcore | Legacy | 贡献方 |
|---|---|---|---|---|
| 权重转换 | Huggingface 与 Megatron 互转 | ✅ | ✅ | 【昇腾】 |
| 数据处理 | 预训练数据处理 | ✅ | ✅ | 【昇腾】 |
| Alpaca风格指令微调数据处理 | ✅ | ✅ | 【昇腾】 | |
| ShareGPT风格指令微调数据处理 | ✅ | ✅ | 【昇腾】 | |
| 分布式推理 | 流式推理 | ✅ | ✅ | 【NAIE】 |
| 微调后 Chat 对话 | ✅ | ✅ | 【NAIE】 | |
| 分布式评估 | 开源测评集评测 | ✅ | ✅ | 【NAIE】 |
昇腾工具链
| 场景 | 特性 | Mcore | Legacy | 贡献方 |
|---|---|---|---|---|
| 性能采集分析 | 基于昇腾芯片采集 profiling 数据 | ✅ | ✅ | 【昇腾】 |
| 高可用性 | 基于昇腾芯片开启确定性计算 | ✅ | ✅ | 【昇腾】 |
| 基于昇腾芯片开启临终 ckpt 保存 | ✅ | ✅ | 【计算研究部】 |
版本配套与维护策略
| 依赖软件 | 版本 | 软件安装指南 |
|---|---|---|
| 昇腾NPU驱动 | 在研版本 | 《驱动固件安装指南》 |
| 昇腾NPU固件 | ||
| Toolkit(开发套件) | 在研版本 | 《CANN 软件安装指南》 |
| Kernel(算子包) | ||
| PyTorch | 在研版本 | 《Ascend Extension for PyTorch 配置与安装》 |
| torch_npu插件 | ||
| apex |
MindSpeed-LLM版本有以下五个维护阶段:
| 状态 | 时间 | 说明 |
|---|---|---|
| 计划 | 1—3 个月 | 计划特性 |
| 开发 | 3 个月 | 开发特性 |
| 维护 | 6-12 个月 | 合入所有已解决的问题并发布版本,针对不同的MindSpeed-LLM版本采取不同的维护策略,常规版本和长期支持版本维护周期分别为6个月和12个月 |
| 无维护 | 0—3 个月 | 合入所有已解决的问题,无专职维护人员,无版本发布 |
| 生命周期终止(EOL) | N/A | 分支不再接受任何修改 |
MindSpeed-LLM已发布版本维护策略:
| MindSpeed-LLM版本 | 维护策略 | 当前状态 | 发布时间 | 后续状态 | EOL日期 |
|---|---|---|---|---|---|
| 1.0.RC3 | 常规版本 | 维护 | 2024/09/30 | 预计2025/03/30起无维护 | |
| 1.0.RC2 | 常规版本 | 维护 | 2024/06/30 | 预计2024/12/30起无维护 | |
| 1.0.RC1 | 常规版本 | EOL | 2024/03/30 | 生命周期终止 | 2024/9/30 |
| bk_origin_23 | Demo | EOL | 2023 | 生命周期终止 | 2024/6/30 |
致谢
MindSpeed-LLM由华为公司的下列部门联合贡献 :
- 昇腾计算产品部
- 计算算法部
- 计算研究部
- 公共开发部:NAIE
- 全球技术服务部:GTS
- 华为云计算
- 昇腾计算生态使能部
感谢来自社区的每一个PR,欢迎贡献 MindSpeed-LLM