|
|
||
|---|---|---|
| ci | ||
| examples | ||
| modellink | ||
| sources/images | ||
| tests | ||
| tools | ||
| .gitignore | ||
| evaluation.py | ||
| inference.py | ||
| LICENSE | ||
| OWNERS | ||
| pretrain_gpt.py | ||
| public_address_statement.md | ||
| README_en.md | ||
| README.md | ||
| requirements.txt | ||
| SECURITY.md | ||
| setup.py | ||
![]()


简体中文 | English
ModelLink provides end-to-end solutions for large language models on Ascend chips, including models, algorithms and tasks.
ModelLink Solution Overview
supported features
Current ModelLink supported features for large model usage:
- Dataset Preparation for Pre-training/Fine-tuning Instruction Dataset Preparation
- Pre-training/Full-parameter Fine-tuning/Low-parameter Fine-tuning
- Inference: human-machine dialogue
- Evaluation with numerous benchmarks
- Utilizing Acceleration Features (Acceleration Algorithms + Fusion Operators)
- Profiling data based on Ascend chips
More novel and useful features are developing for LLMs training on Ascend ...
Supported Models
Current ModelLink supports pre-training and fine-tuning for the following models:
Script Naming Rules
| Script | Rule |
|---|---|
| pretrain_xxx.sh | Pre-training Script |
| tune_xxx.sh | Fine-tuning Script |
| generate_xxx.sh | Inference Script |
| evaluation_xxx.sh | Evaluation Script |
Model Usage Guide and Version Notes
Model Usage Guide and Version Notes For the supported models listed above, we provide training scripts and readme instructions in the examples folder, which contain detailed processes for model training, inference, and evaluation.
【Please note the corresponding environment versions for model usage, as follows】
| Software | Version |
|---|---|
| Python | 3.8 |
| driver | Ascend HDK 23.0.0 |
| firmware | Ascend HDK 23.0.0 |
| CANN | CANN 7.0.0 |
| torch | 2.1.0 |
| torch_npu | release v5.0.0 |
【Based on the current version of megatron, the performance statistics from our testing are as follows】
| Model | Parameters | Cluster Scale | Precision Mode | Performance | Reference Performance | Scripts |
|---|---|---|---|---|---|---|
| Aquila | 7B | 1x8 | BF16 | 2849 | 2874 | train |
| Baichuan | 7B | 1x8 | FP16 | 2685 | 2036 | train |
| 13B | 1x8 | FP16 | 1213 | 862 | train | |
| Baichuan2 | 7B | 1x8 | BF16 | 2664 | 3969 | train |
| 13B | 1x8 | BF16 | 1668 | 2062 | train | |
| Bloom | 7B1 | 1x8 | FP16 | 2034 | 2525 | train |
| 176B | 12x8 | BF16 | 100 | 107 | train | |
| InternLM | 7B | 1x8 | BF16 | 2776 | 2854 | train |
| 65B | 4x8 | BF16 | 341 | 414 | train | |
| LLaMA | 7B | 1x8 | FP16 | 3600 | 3804 | train |
| 13B | 1x8 | FP16 | 1895 | 2012 | train | |
| 33B | 4x8 | FP16 | 621 | 776 | train | |
| 65B | 4x8 | |||||
| BF16 | 348 | 426 | train | |||
| LLaMA2 | 7B | 1x8 | BF16 | 2884 | 2884 | train |
| 13B | 1x8 | BF16 | 1550 | 1750 | train | |
| 34B | 2x8 | BF16 | 690 | 796 | train | |
| 70B | 8x8 | BF16 | 350 | 339 | train | |
| LLaMA3 | 8B | 1x8 | BF16 | 2275 | 2570 | train |
| 70B | 8x8 | BF16 | 283 | -- | train | |
| Qwen | 7B | 1x8 | BF16 | 2499 | 2867 | train |
| 14B | 1x8 | BF16 | 1560 | 1578 | train | |
| 72B | 16x8 | BF16 | 285 | 345 | train | |
| Mixtral | 8x7B | 2x8 | BF16 | 1054 | 1139 | train |
Function Usage Guide
Instruction/Pretraining dataset support
Quick Start
Use the preprocess_data.py data preprocessing tool to process raw data into binary format data for training. Below is an example of processing the Alpaca dataset:
# for llama, download alpaca dataset, like
wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# download tokenizer configs and (selective) weights from
# https://huggingface.co/yahma/llama-7b-hf/tree/main
# revise "LLaMATokenizer" as "LlamaTokenizer" in tokenizer_config.json (This is a bug of huggingface)
mkdir dataset
python tools/preprocess_data.py --input train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix dataset/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
The output will be two files, named alpaca_packed_input_ids_document.bin and alpaca_packed_input_ids_document.idx. In subsequent training, specify --data-path with the full path and new filename, but without the file extension. Use --tokenizer-type to specify the data preprocessing method corresponding to the model, --tokenizer-name-or-path to specify the tokenizer model path, usually downloaded along with the pre-trained weights in the open-source project, and --handler-name to specify the data set's instruction data construction method.
reprocessing pretraining dataset
wikipedia dataset
- download wikipedia data from huggingface to WORKSPACE/wikipedia
- download llama tokenizer model and config from huggingface to WORKSPACE/llama-7b-hf
- use preprocessing script to preprocess wikipedia data
# We assume that data and tokenizer has already been downloaded to WORKSPACE.
cd WORKSPACE
mkdir wikipedia_preprocessed
# specify huggingface load_dataset parameters.(--input param will be ignored)
# these params will just be feed into datasets.load_dataset function
hf_config_json="./hf_config_json.json"
cat <<EOT > $hf_config_json
{
"path": "WORKSPACE/wikipedia",
"name": "20220301.en",
"streaming: True,
"split": "train"
}
EOT
python tools/preprocess_data.py \
--input "WORKSPACE/wikipedia" \
--hf-datasets-params ${hf_config_json} \
--output-prefix WORKSPACE/wikipedia_preprocessed/wikipedia \
--dataset-impl mmap \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--streaming \
--workers 8
After preprocessing, there will be a wikipedia_text_document.bin and a wikipedia_text_document.idx in the WORKSPACE/wikipedia_preprocessed dictionary.
Then, we can train a model with --data-path WORKSPACE/wikipedia_preprocessed/wikipedia_text_document flag.
Note that datasets in huggingface have a format like this. The name of the text field of the dataset can be changed by using the --json-key flag which default is text.
In wikipedia dataset, it has four columns, including id, url, title and text, where we can choose a column used for training by --json-key flag.
alpaca dataset
Besides, we can also use alpaca dataset for pretraining as below.
python tools/preprocess_data.py --input WORKSPACE/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--json-key text
Preprocessing instruction dataset
alpaca dataset
# for llama, download alpaca dataset, like
# wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# download tokenizer configs and (selective) weights from
# https://huggingface.co/yahma/llama-7b-hf/tree/main
# revise "LLaMATokenizer" as "LlamaTokenizer" in tokenizer_config.json (This is a bug of huggingface)
cd WORKSPACE
mkdir alpaca_preprocessed
python tools/preprocess_data.py --input WORKSPACE/alpaca/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler \
--append-eod
After preprocessing, there will be three bin files and three idx files in the WORKSPACE/alpaca_preprocessed dictionary. Then, we can train a model with --data-path WORKSPACE/alpaca_preprocessed/alpaca and --is-instruction-dataset flags.
In addition, we have developed the dynamic padding function based on the instruction dataset, which can be implemented using the --variable-seq-lengths flag.
Note that instruction dataset has a --handler-name GeneralInstructionHandler flag which will choose GeneralInstructionHandler class to create prompt in modellink/data/data_handler.py.
If you have an alpaca-style dataset which have instruction, input and output columns, just use GeneralInstructionHandler.
In addition, BelleMultiTurnInstructionHandler is used to handle belle dataset,
MOSSInstructionHandler is used to handle MOSS dataset and LeetcodePythonInstructionHandler is used to handle Leetcode dataset.
Pre-training
# Configure LLaMA-7B pre-training script: pretrain_llama_7b.sh
# Configure vocabulary, dataset, and model parameter saving path according to actual conditions
TOKENIZER_PATH=WORKSPACE/llama-7b-hf/tokenizer.model # Path to the vocabulary
DATA_PATH=WORKSPACE/alpaca_preprocessed/alpaca_text_document # Path to pre-training dataset
Launch LLaMA-7B pre-training script: examples/llama/pretrain_llama_7b_ptd.sh
bash examples/llama2/pretrain_llama_7b_ptd.sh
Full-parameter Fine-tuning
# Based on the pre-training script, provide the pre-training weight path, use instruction dataset path, and enable fine-tuning switch --finetune
LOAD_CHECKPOINT_PATH="your init model weight load path"
DATA_PATH=WORKSPACE/alpaca_preprocessed/alpaca_text_document # Instruction fine-tuning dataset path
torchrun $DISTRIBUTED_ARGS pretrain_gpt.py \
--load ${LOAD_CHECKPOINT_PATH} \
--finetune \
... \
...
Low-parameter fine-tuning
Lora
Now, we support Lora to fine-tune your models.
First, you need to install version 0.4.0 of the peft library, like this:
pip install peft==0.4.0
When torch==1.11.0, You can also choose to install from the source package in the GitHub repository, so you can modify the setup.py file to avoid some dependency issues.
Next, you just need to add this argument in your script to open Lora:
# Llama example
--lora-target-modules query_key_value dense gate_proj dense_h_to_4h dense_4h_to_h \
There are other Lora related arguments here, you can find their definitions in the PEFT library.
# Llama example
--lora-r 64 \
--lora-alpha 128 \
--lora-modules-to-save word_embeddings output_layer \
--lora-register-forward-hook word_embeddings input_layernorm \
Among them, the argument --lora-register-forward-hook is used to repair the gradient chain break caused by PP. It only needs to be set to the input layer of each PP stage, and the repair will not increase the trainable parameters. The argument --lora-modules-to-save is used for fine-tuning when expanding the vocabulary. If there is no need for this, there is no need to pass in this argument.
Finally, only Lora's parameters are saved after turning on Lora. Similarly, when loading a model, you need to specify the original model weight path and the Lora weight path. Parameters such as the optimizer are subject to those in the Lora weight path.
--load ${ORIGIN_CHECKPOINT} \
--lora-load ${LORA_CHECKPOINT} \
There is an example could be referred.
After using Lora to fine-tune the Llama model, the instruction dialogue effect is as follows:
You >> Give three tips for staying healthy.
ModelLink:
- Start exercising regularly and eat healthy food.
- Get a good eight hours of sleep each night.
- Take medications regularly.
Inference: human-machine dialogue
Currently, we support the following four cases of inference:
- PTD
- Model fine-tuned with lora
【For supported models, we also provide examples. Please refer to the following quick start】
Quick Start
Please Note that:
-
If you want to use the weight from huggingface, please run the weight conversion script first. Take Llama-7B, for example:
- PTD only
python tools/checkpoint/convert_ckpt.py --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 8 \ --load-dir ./model_from_hf/llama-7b-hf \ --save-dir ./model_weights/llama-7b-tp1-pp8 \ --tokenizer-model ./model_from_hf/llama-7b-hf/tokenizer.model
- PTD only
-
You need to modify some variables in the shell script such as model weight path and vocab path.
- PTD only: In this mode, the model is split by pipeline parallel and tensor parallel mode in megatron ways.
sh examples/llama/generate_llama_7B_tp2_pp2.sh - If you want to use lora model, for details, refer to:
sh examples/llama/generate_llama_7b_lora_ptd.sh
- PTD only: In this mode, the model is split by pipeline parallel and tensor parallel mode in megatron ways.
Usage Guide
Some examples with Chinese-LLaMA-Alpaca-13B weights is as below:
Initializing the Distributed Environment
initialize_megatron(args_defaults={'no_load_rng': True, 'no_load_optim': True})
Initializing model and loading weights
from modellink import get_args
from modellink.model import GPTModel
from modellink.arguments import core_transformer_config_from_args
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
config = core_transformer_config_from_args(get_args())
init_model = GPTModel(
config,
num_tokentypes=0,
parallel_output=False,
return_moe_loss=False,
pre_process=pre_process,
post_process=post_process
)
return init_model
model = GPTModel.from_pretrained(
model_provider=model_provider,
pretrained_model_name_or_path="your model weight path"
)
"""
This is an API for initializing model and loading weight.
Parameters:
----------
model_provider(`func`):
Function used to generate model objects which is similar to the training define.
pretrained_model_name_or_path(`str`, *optional*, defaults to None):
File path of Model weight in megatron format (TP, PP may be used).
If it is None, the random initialized weights will be used.
"""
Generate text in HuggingFace-like ways
-
Greedy Search
responses = model.generate( "Write quick sort code in python", max_new_tokens=512 )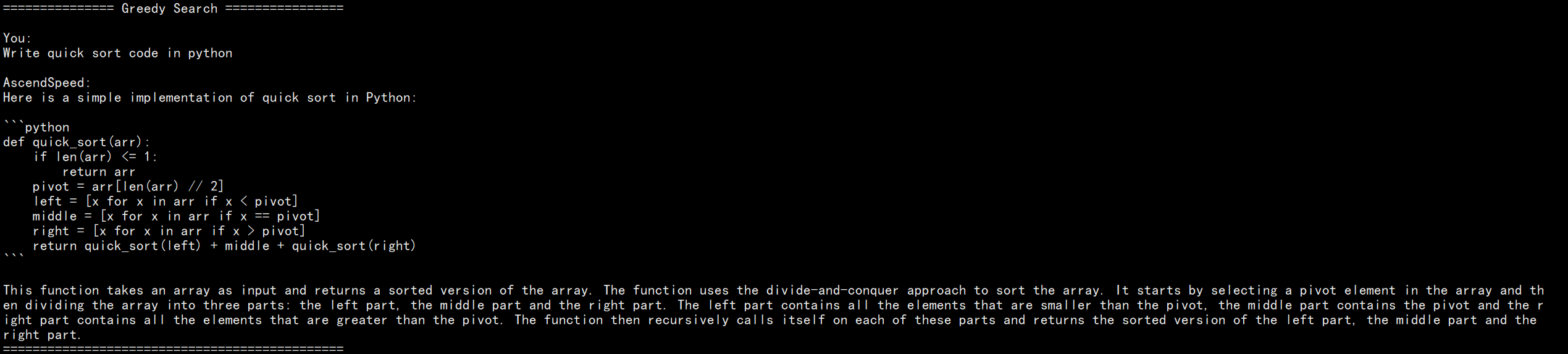
-
Do sample with top-k and top-p
responses = model.generate( "Write quick sort code in python", do_sample=True, temperature=1.0, top_k=50, top_p=0.95, max_new_tokens=512 )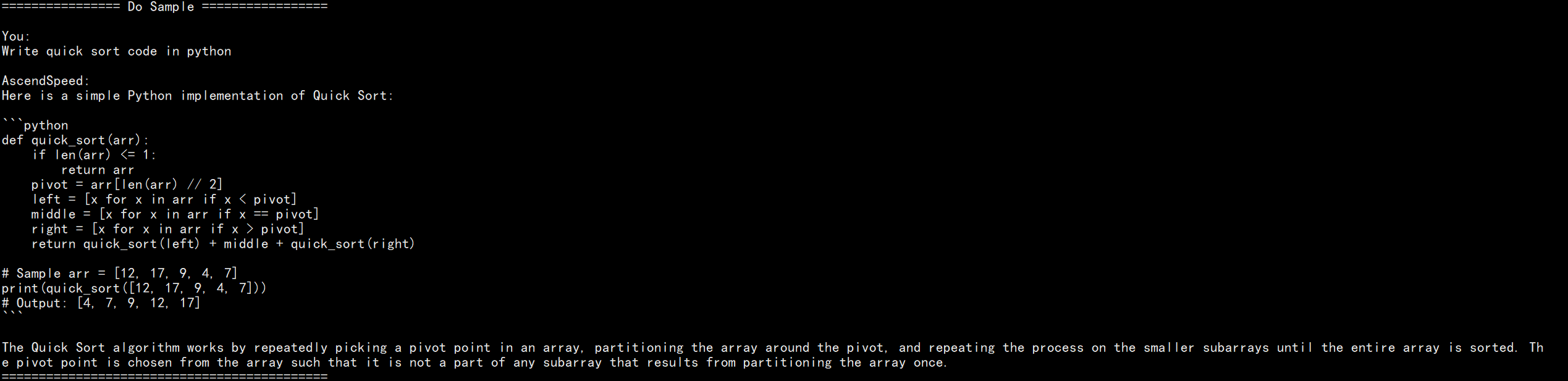
-
Beam search with top-k and top-p
responses = model.generate( "Write quick sort code in python", num_beams=4, top_k=50, top_p=0.95, max_new_tokens=512 )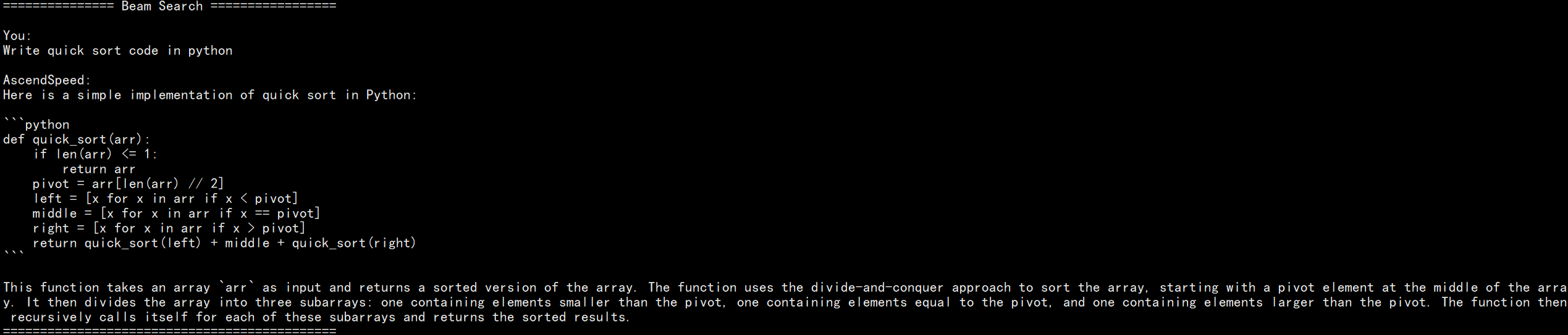
-
Beam search with top-k and top-p sampling
responses = model.generate( "Write quick sort code in python", do_sample=True, temperature=0.6, num_beams=4, top_k=50, top_p=0.95, max_new_tokens=512 )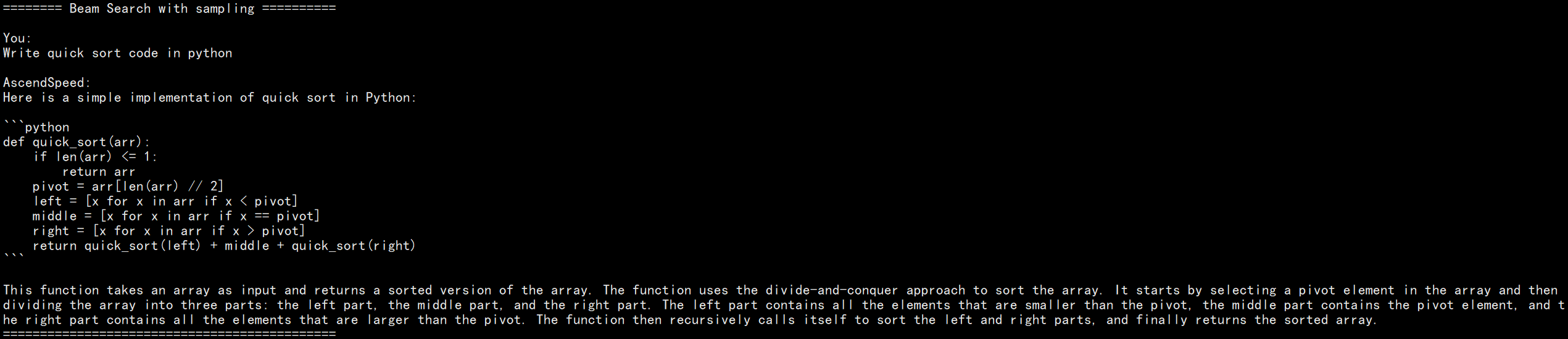
Evaluation with Numerous Benchmarks
Dataset Evaluation Results
| Task | Subset | Model | Ascend | Reference | Benchmark |
|---|---|---|---|---|---|
| BBH | test | Llama7b | 0.334 | 0.333 | 0.335 |
| AGIEval | test | Llama7b | 0.210 | 0.210 | 0.206 |
| HumanEval | test | Llama7b | 0.128 | 0.128 | 0.128 |
| BoolQ | test | Llama7b | 0.742 | 0.742 | 0.754 |
| GSM8K | test | Llama7b | 0.102 | 0.103 | 0.100 |
| CEval | val | Llama7b | 0.408 | 0.404 | / |
| MMLU | test | Llama7b | 0.333 | 0.324 | 0.351 |
Quick Start
# Configure model path and vocab_file path
# Vocab file can be downloaded from https://huggingface.co/yahma/llama-7b-hf
CHECKPOINT=../models/llama-7b-tp2-pp4/
VOCAB_FILE=../models/llama7b-hf/
# configure task and data path
DATA_PATH="dataset/boolq/test"
TASK="boolq"
# configure generation parameters
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT[images](sources%2Fimages)} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
# start evaluation
bash examples/llama/evaluate_llama_7B_ptd.sh
Task Introduction
The most important evaluation parameters must be --max-new-tokens, which means the output length of model generation. For example, multiple-choice
questions' output length is obviously shorter than coding tasks. Besides, this parameter largely decides the speed of model generation.
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--evaluation-batch-size 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
Evaluation Script Instructions
Baseline Dataset Introduction
MMLU
Since MMLU is a multidisciplinary task and 5 shots are performed, the length of each subject question varies greatly. If you want to run 57 subjects at the same time, you need to set TASK="mmlu", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=2. (--max-new-tokens can be set to between 2-4).
On many websites, the accuracy of the MMLU is evaluated according to disciplines. The 57 categories of single subjects belong to four main categories. Therefore, the statistics should be summarized according to the major categories of the subjects. The website gives the major categories of subjects for 57 categories of subjects.
GSM8K
GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers. The answer of each question is a specific number. Since few shots are performed, the question length is relatively long in GSM8K, and the output answer contains a chain of thoughts, it is necessary to configure TASK="gsm8k", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=128. (--max-new-tokens can be set between 256-512).
HumanEval
HumanEval dataset is a handcrafted set of 164 programming problems designed to challenge code generation models. The problems include a function signature, docstring, body, and several unit tests, all handwritten to ensure they're not included in the training set of code generation models.
Since the answer of HumanEval dataset contains long codes, it is necessary to configure TASK="human_eval", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=1024.
AGIEval
AGIEval is a human-centric benchmark specifically designed to evaluate the general
abilities of foundation models in tasks pertinent to human cognition and problem-solving. This benchmark is derived from 20 official, public, and high-standard admission and qualification exams intended for general human test-takers, such as general college admission tests (e.g., Chinese College Entrance Exam (Gaokao) and American SAT), law school admission tests, math competitions, lawyer qualification tests, and national civil service exams.Since the length of answers to different type of questions varies, we have to configure TASK="agieval", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=1024 to fit the longest answer.
Big-Bench-Hard
Big-bench-hard dataset is a subset of big bench, which is a diverse evaluation suite that focuses on a suite of 23 challenging BIG-Bench tasks. These are the task for which prior language model evaluations did not outperform the average human-rater. This dataset covers multiple areas including text understanding, reasoning, logical reasoning, mathematical reasoning, and common sense reasoning.
Except word_sorting, all datasets are multiple-choice questions. So we can set TASK="bbh", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=32. (--max-new-tokens can be set between 32-64).
CEval
As C-Eval shows, C-Eval is a comprehensive Chinese evaluation suite for foundation models. It consists of 13948 multi-choice questions spanning 52 diverse disciplines and four difficulty levels, as shown below. You may explore our dataset examples at Explore, or check our paper for more details. The dataset contains validation and test data, however, only validation data has label for auto-evaluation. If you want to evaluate on test data, you should email your results to C-Eval.
Acceleration Features
ModelLink supports various acceleration algorithms such as tensor parallelism, pipeline parallelism, sequence parallelism, recomputation, distributed optimizer, and more. The table below shows the enable switches corresponding to each acceleration feature:
| Acceleration Feature | Enable Parameter |
|---|---|
| Tensor Parallel | --tensor-model-parallel-size |
| Pipeline Parallel | --pipeline-model-parallel-size |
| Dynamic division for PP | --num-layer-list |
| Sequence Parallel | --sequence-parallel |
| Recomputation | --recompute-granularity |
| Distributed Optimizer | --use-distributed-optimizer |
| overlap DDP allreduce | --overlap-grad-reduce |
| overlap DDP allgather | --overlap-param-gather |
| Flash attention | --use-flash-attn |
| Fused rmsnorm | --use-fused-rmsnorm |
| Fused swiglu | --use-fused-swiglu |
| mc2 | --use-mc2 |
| Fused rotary position embedding |
--use-fused-rotary-pos-emb |
torchrun $DISTRIBUTED_ARGS pretrain_gpt.py \
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size ${PP} \
--num-layer-list 1,2,2,2,1 \
--sequence-parallel \
--recompute-granularity full \
--recompute-method block \
--recompute-num-layers 72 \
--use-distributed-optimizer \
--use-flash-attn \
--use-fused-rmsnorm \
--use-fused-swiglu \
--overlap-grad-reduce \
--overlap-param-gather \
--use-fused-rotary-pos-emb \
--use-mc2 \
... \
...
Analyze profiling data based on Ascend chips
Modellink supports analyze profiling data based on Ascend chips, which is useful for modelling:
--profile # enable profiling
--profile-step-start 5 # the start step
--profile-step-end 6 # the end step
--profile-ranks 0 1 2 3 4 # ranks for profiling
--profile-level level2 # level0, 1, 2 for data profiling
--profile-with-cpu # profiling cpu information
--profile-with-stack # profile stack information
--profile-with-memory # profile memory information
--profile-record-shapes # profile shape information
--profile-save-path ./profile_dir # path to save data
Acknowledgments
ModelLink is jointly contributed by the following departments of Huawei Corporation:
- Ascend Computing Product Unit
- Algorithm Unit of Computing Product Unit
- Research Unit of Computing Product Unit
- Open Computing Kit of Computing Product Unit
- General Development Department
- Global Technical Service Department
We appreciate every PR from community, and welcome to contribute to ModelLink.
Appendix
- Safety Statement: Safety Statement