40 KiB
![]()


简体中文 | English
ModelLink旨在为华为 昇腾芯片 上的大语言模型提供端到端的解决方案, 包含模型,算法,以及下游任务。
ModelLink解决方案概览
支持功能
当前ModelLink支撑大模型使用功能:
强化学习等特性持续研发中....
支持模型
当前ModelLink支持下列模型的预训练以及微调:
| 模型 | 参数 | 微调 | 推理 | 评估 | 数据集 |
|---|---|---|---|---|---|
| Aquila | 7B | -- | 对话 | 评估 | alpaca_data.json |
| Baichuan | 7B | -- | 对话 | 评估 | alpaca_data.json |
| 13B | -- | 对话 | 评估 | alpaca_data.json | |
| Baichuan2 | 7B | -- | 对话 | 评估 | alpaca_data.json |
| 13B | -- | 对话 | 评估 | alpaca_data.json | |
| Bloom | 7B1 | -- | 对话 | 评估 | alpaca_data.json |
| 176B | -- | 对话 | 评估 | alpaca_data.json | |
| InternLM | 7B | -- | 对话 | 评估 | alpaca_data.json |
| 65B | -- | -- | -- | alpaca_data.json | |
| LLaMA | 7B | lora | 对话 | 评估 | alpaca_data.json |
| 13B | lora | 对话 | 评估 | alpaca_data.json | |
| 33B | lora | 对话 | 评估 | alpaca_data.json | |
| 65B | lora | 对话 | 评估 | alpaca_data.json | |
| LLaMA2 | 7B | lora | 对话 | 评估 | alpaca_data.json |
| 13B | lora | 对话 | 评估 | alpaca_data.json | |
| 34B | lora | 对话 | 评估 | alpaca_data.json | |
| 70B | lora | 对话 | 评估 | alpaca_data.json | |
| LLaMA3 | 8B | -- | 对话 | 评估 | alpaca_data.json |
| 70B | -- | 对话 | 评估 | alpaca_data.json | |
| Qwen | 7B | -- | 对话 | 评估 | alpaca_data.json |
| 14B | -- | 对话 | 评估 | alpaca_data.json | |
| 72B | -- | 对话 | 评估 | alpaca_data.json | |
| Mixtral | 8x7B | -- | 对话 | 评估 | alpaca_data.json |
脚本命名规则
| 脚本 | 规则 |
|---|---|
| pretrain_xxx.sh | 预训练脚本 |
| tune_xxx.sh | 微调脚本 |
| generate_xxx.sh | 推理脚本 |
| evaluation_xxx.sh | 评估脚本 |
模型使用指导与版本说明
上述列表中支持的模型,我们在examples文件夹中提供了各模型的训练脚本和readme说明,里面有详细的模型训练、推理、评估流程。
【需要注意模型使用时的配套环境版本,参考如下】
| 软件 | 版本 |
|---|---|
| Python | 3.8 |
| driver | Ascend HDK 23.0.0 |
| firmware | Ascend HDK 23.0.0 |
| CANN | CANN 7.0.0 |
| torch | 2.1.0 |
| torch_npu | release v5.0.0 |
【基于现版本megatron我们实测的性能情况统计如下】
| 模型 | 参数 | 集群规模 | 精度模式 | 性能 | 参考性能 | 脚本 |
|---|---|---|---|---|---|---|
| Aquila | 7B | 1x8 | BF16 | 2849 | 2874 | 训练 |
| Baichuan | 7B | 1x8 | FP16 | 2685 | 2036 | 训练 |
| 13B | 1x8 | FP16 | 1213 | 862 | 训练 | |
| Baichuan2 | 7B | 1x8 | BF16 | 2664 | 3969 | 训练 |
| 13B | 1x8 | BF16 | 1668 | 2062 | 训练 | |
| Bloom | 7B1 | 1x8 | FP16 | 2034 | 2525 | 训练 |
| 176B | 12x8 | BF16 | 100 | 107 | 训练 | |
| InternLM | 7B | 1x8 | BF16 | 2776 | 2854 | 训练 |
| 65B | 4x8 | BF16 | 341 | 414 | 训练 | |
| LLaMA | 7B | 1x8 | FP16 | 3600 | 3804 | 训练 |
| 13B | 1x8 | FP16 | 1895 | 2012 | 训练 | |
| 33B | 4x8 | FP16 | 621 | 776 | 训练 | |
| 65B | 4x8 | |||||
| BF16 | 348 | 426 | 训练 | |||
| LLaMA2 | 7B | 1x8 | BF16 | 2884 | 2884 | 训练 |
| 13B | 1x8 | BF16 | 1550 | 1750 | 训练 | |
| 34B | 2x8 | BF16 | 690 | 796 | 训练 | |
| 70B | 8x8 | BF16 | 350 | 339 | 训练 | |
| LLaMA3 | 8B | 1x8 | BF16 | 2275 | 2570 | 训练 |
| 70B | 8x8 | BF16 | 283 | -- | 训练 | |
| Qwen | 7B | 1x8 | BF16 | 2499 | 2867 | 训练 |
| 14B | 1x8 | BF16 | 1560 | 1578 | 训练 | |
| 72B | 16x8 | BF16 | 285 | 345 | 训练 | |
| Mixtral | 8x7B | 2x8 | BF16 | 1054 | 1139 | 训练 |
功能使用指导
制作预训练数据集/制作指令微调数据集
快速开始
使用preprocess_data.py数据预处理工具将raw数据处理为用于训练的二进制格式数据,下面是一个处理alpaca数据集的样例:
# 对于llama, 可以下载alpaca数据集, 比如
wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# 下载 tokenizer 配置, 地址:
# https://huggingface.co/yahma/llama-7b-hf/tree/main
# 这里要将tokenizer_config.json中的"LLaMATokenizer"修改为"LlamaTokenizer"(这是huggingface的一个bug)
mkdir dataset
python tools/preprocess_data.py --input train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix dataset/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
输出将是两个文件,在本例中名为alpaca_packed_input_ids_document.bin和alpaca_packed_input_ids_document.idx,后面的训练中指定--data-path的是完整路径和新文件名,但不带文件扩展名。使用--tokenizer-type指定模型对应的数据预处理方法,使用--tokenizer-name-or-path指定tokenizer模型路径,通常是与开源项目中的预训练权重一起下载,--handler-name指定数据集的指令数据构造方法。
制作预训练数据集
wikipedia 数据集
- 下载 wikipedia 数据集到 WORKSPACE/wikipedia 目录
- 下载 llama tokenizer 配置到 WORKSPACE/llama-7b-hf 目录
- 再使用如下脚本处理数据集
# 这里认为 数据集 和 tokenizer 已经下载放到了 WORKSPACE.
cd WORKSPACE
mkdir wikipedia_preprocessed
hf_config_json="./hf_config_json.json"
cat <<EOT > $hf_config_json
{
"path": "WORKSPACE/wikipedia",
"name": "20220301.en",
"streaming: True,
"split": "train"
}
EOT
python tools/preprocess_data.py \
--input "WORKSPACE/wikipedia" \
--hf-datasets-params ${hf_config_json} \
--output-prefix WORKSPACE/wikipedia_preprocessed/wikipedia \
--dataset-impl mmap \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--streaming \
--workers 8
处理完后, WORKSPACE/wikipedia_preprocessed 文件夹下会有 wikipedia_text_document.bin 和 wikipedia_text_document.idx 文件, 我们便可以使用 --data-path WORKSPACE/wikipedia_preprocessed/wikipedia_text_document 标志训练模型了
请注意huggingface中的数据集格式是这样的. 我们处理数据时利用的数据列可以通过 --json-key 标志设置,默认为 text,
比如,wikipedia数据集有四列, 包括 id, url, title 和 text, 我们就可以通过 --json-key 标志选择一列处理该数据集
alpaca 数据集
此外, 我们也可以使用 alpaca 数据集用于预训练如下:
python tools/preprocess_data.py --input WORKSPACE/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--json-key text
制作指令微调数据集
alpaca 数据集
# 数据集:wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
cd WORKSPACE
mkdir alpaca_preprocessed
python tools/preprocess_data.py --input WORKSPACE/alpaca/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler \
--append-eod
在处理后,WORKSPACE/alpaca_preprocessed 文件夹下会有3个 bin 文件 和 3个 idx 文件,我们便可以通过添加 --data-path WORKSPACE/alpaca_preprocessed/alpaca 和 --is-instruction-dataset 标志来进行指令微调。
此外,基于指令数据集,我们还可以通过加上 --variable-seq-lengths 标志使用动态序列长度训练模型。
请注意,使用 --handler-name GeneralInstructionHandler 标志的指令数据集,在处理时会从 modellink/data/data_handler.py 中选择 GeneralInstructionHandler 类来制作prompt。如果你处理的是 alpaca 格式风格的数据集,即包含 instruction, input 和 output 列的数据集,可以直接使用 --handler-name GeneralInstructionHandler 标志。
此外,BelleMultiTurnInstructionHandler 可以被用于处理 belle 格式的数据集,MOSSInstructionHandler 可以被用于处理 MOSS 格式的数据集,LeetcodePythonInstructionHandler 可以被用于处理 Leetcode 风格的数据集
预训练
# 配置LLaMA-7B 预训练脚本: pretrain_llama_7b.sh
# 根据实际情况配置词表、数据集、模型参数保存路径
TOKENIZER_PATH=WORKSPACE/llama-7b-hf/tokenizer.model #词表路径
DATA_PATH=WORKSPACE/alpaca_preprocessed/alpaca_text_document #预训练数据集路径
启动 LLaMA-7B 预训练脚本: examples/llama/pretrain_llama_7b_ptd.sh
bash examples/llama2/pretrain_llama_7b_ptd.sh
全参微调
# 在预训练脚本的基础上,给出预训练权重路径,数据集使用指令数据集路径,使能微调开关--finetune
LOAD_CHECKPOINT_PATH="your init model weight load path"
DATA_PATH=WORKSPACE/alpaca_preprocessed/alpaca_text_document #指令微调数据集路径
torchrun $DISTRIBUTED_ARGS pretrain_gpt.py \
--load ${LOAD_CHECKPOINT_PATH} \
--finetune \
... \
...
低参微调
Lora
当前 ModelLink基于 peft 仓库支持对大模型的 Lora 微调功能:
pip install peft==0.4.0
当torch==1.11.0的时候,你也可以选择直接从它Github仓库的 源码安装, 通过修改它的setup.py文件来回避一些依赖问题。
之后,你仅仅只需要在启动脚本中使能如下标志便可以启动lora微调训练:
# Llama example
--lora-target-modules query_key_value dense gate_proj dense_h_to_4h dense_4h_to_h \
Lora有一些相关参数,在 PEFT 仓库中有详细介绍,比如:
# Llama example
--lora-r 64 \
--lora-alpha 128 \
--lora-modules-to-save word_embeddings output_layer \
--lora-register-forward-hook word_embeddings input_layernorm \
在这些参数中,标志 --lora-register-forward-hook 被用于修复由PP造成的梯度链中断,它仅仅只需要在每一个PP阶段的输入层设置,并不会增加训练参数。 标志 --lora-modules-to-save 被用于扩展词表时的微调,若没此需求则无需传入此参数。
最后,Lora微调后保存的权重仅仅只会包含新增的Lora权重。相似的,当你加载一个Lora模型时,除了原始权重路径需要设置,还需要设置一个加载Lora权重的路径,如下:
--load ${ORIGIN_CHECKPOINT} \
--lora-load ${LORA_CHECKPOINT} \
这个 例子 可以用于参考。
在使用 Lora 微调 Llama 模型以后,指令对话的效果如下:
You >> Give three tips for staying healthy.
ModelLink:
- Start exercising regularly and eat healthy food.
- Get a good eight hours of sleep each night.
- Take medications regularly.
推理( 人机对话)
当前,我们支持使用如下策略训练的模型进行推理: 当前,我们支持使用如下并行策略训练的模型进行推理:
- 仅仅使用 PTD 策略训练的模型
- 使用 Lora 策略微调的模型
【同时对于已经支持的模型,我们提供了样例,请参考下列快速开始】
快速开始
-
如果你尝试使用 huggingface 的模型权重,请首先进行权重转换, 以 Llama-7B 为例:
- PTD 策略的转换
python tools/checkpoint/convert_ckpt.py --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 8 \ --load-dir ./model_from_hf/llama-7b-hf \ --save-dir ./model_weights/llama-7b-tp1-pp8 \ --tokenizer-model ./model_from_hf/llama-7b-hf/tokenizer.model
- PTD 策略的转换
-
下面脚本中的一些路径需要修改,比如:模型权重路径 和 词表路径.
- 仅仅使用 PTD 策略训练的模型:在这种模式下,模型以 Megatron-LM 的风格被 流水并行 和 张量并行 切分
sh examples/llama/generate_llama_7b_ptd.sh - 如果你仅仅使用 Lora, 可以参考:
sh examples/llama/generate_llama_7b_lora_ptd.sh
- 仅仅使用 PTD 策略训练的模型:在这种模式下,模型以 Megatron-LM 的风格被 流水并行 和 张量并行 切分
使用手册
这里列举了一些使用 Chinese-LLaMA-Alpaca-13B 权重进行推理的例子, 同时依据下列步骤可以写出你自己的推理例子:
初始化分布式环境
initialize_megatron(args_defaults={'no_load_rng': True, 'no_load_optim': True})
初始化模型和权重
from modellink import get_args
from modellink.model import GPTModel
from modellink.arguments import core_transformer_config_from_args
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
config = core_transformer_config_from_args(get_args())
init_model = GPTModel(
config,
num_tokentypes=0,
parallel_output=False,
return_moe_loss=False,
pre_process=pre_process,
post_process=post_process
)
return init_model
model = GPTModel.from_pretrained(
model_provider=model_provider,
pretrained_model_name_or_path="your model weight path"
)
"""
This is an API for initializing model and loading weight.
Parameters:
----------
model_provider(`func`):
Function used to generate model objects which is similar to the training define.
pretrained_model_name_or_path(`str`, *optional*, defaults to None):
File path of Model weight in megatron format (TP, PP may be used).
If it is None, the random initialized weights will be used.
"""
以 HuggingFace 的风格生成文本
-
Greedy Search
responses = model.generate( "Write quick sort code in python", max_new_tokens=512 )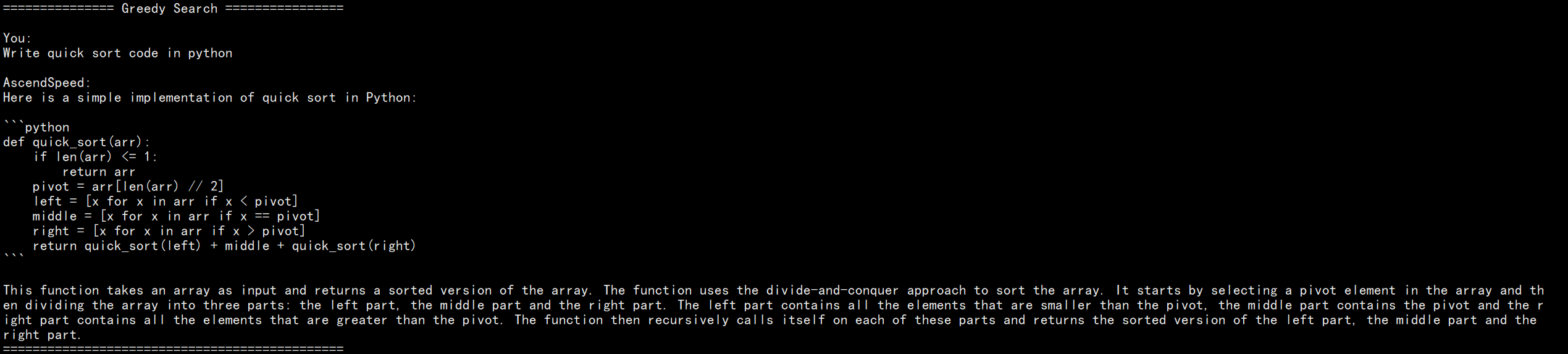
-
Do sample with top-k and top-p
responses = model.generate( "Write quick sort code in python", do_sample=True, temperature=1.0, top_k=50, top_p=0.95, max_new_tokens=512 )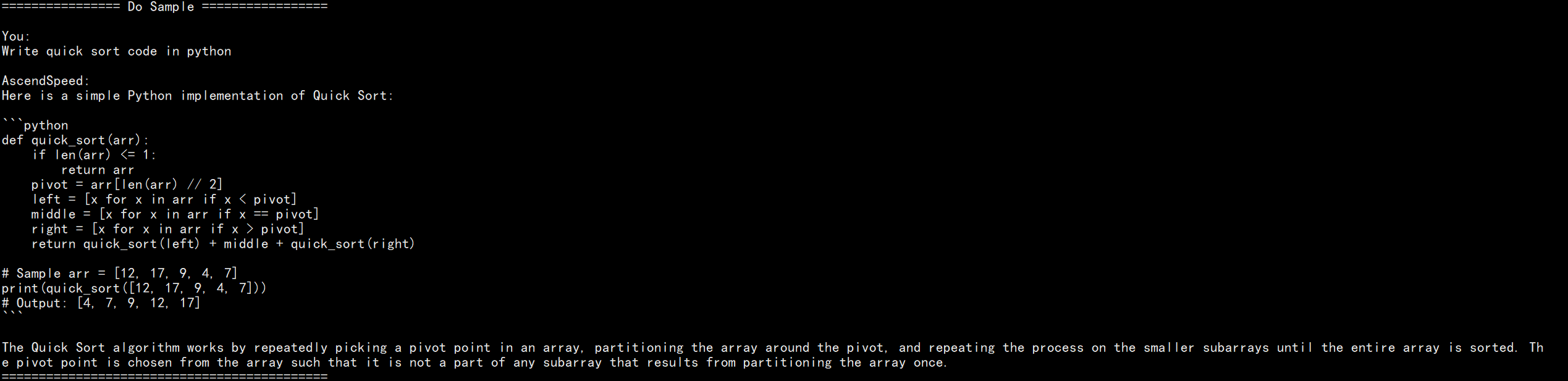
-
Beam search with top-k and top-p
responses = model.generate( "Write quick sort code in python", num_beams=4, top_k=50, top_p=0.95, max_new_tokens=512 )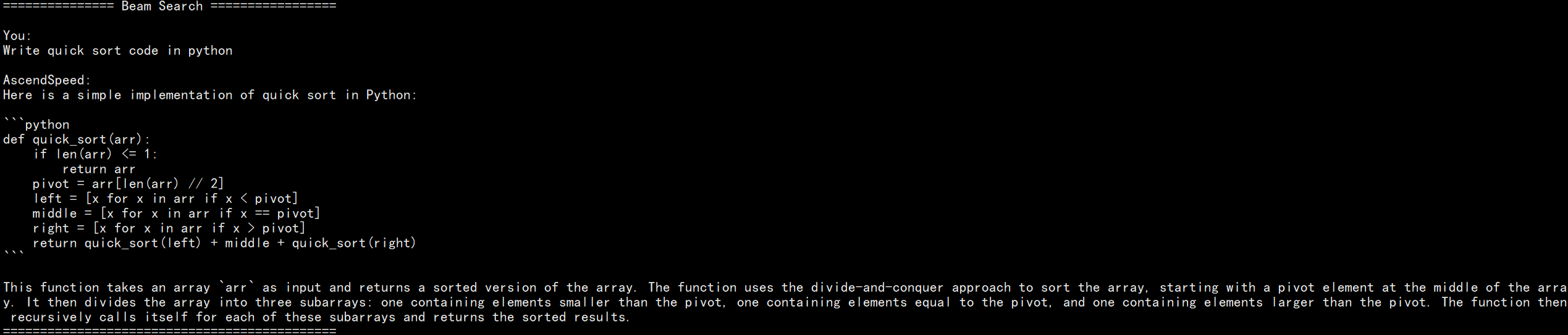
-
Beam search with top-k and top-p sampling
responses = model.generate( "Write quick sort code in python", do_sample=True, temperature=0.6, num_beams=4, top_k=50, top_p=0.95, max_new_tokens=512 )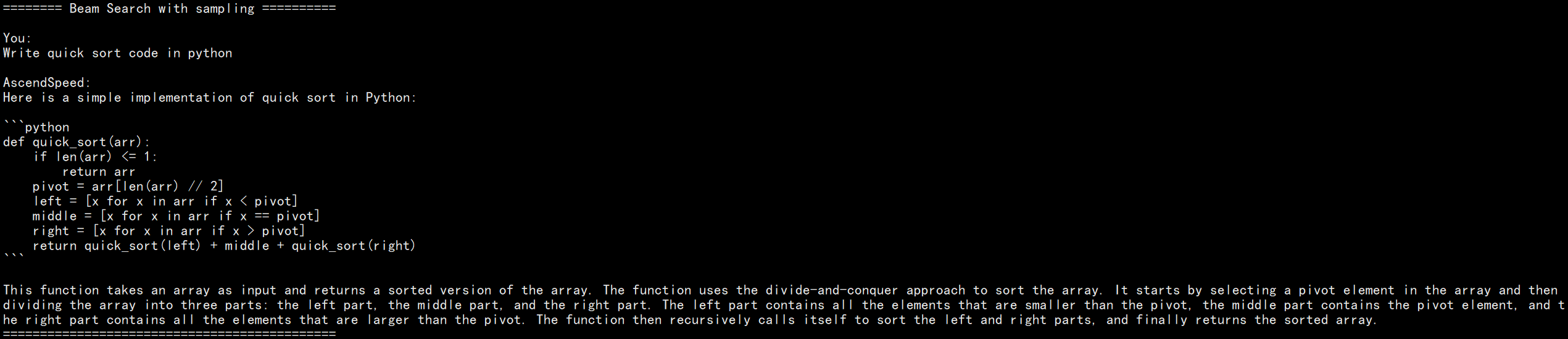
评估基线数据集(Benchmark)
数据集评估结果参考
| 任务 | 验证集 | 模型 | 昇腾值 | 参考值 | 社区值 |
|---|---|---|---|---|---|
| BBH | test | Llama7b | 0.334 | 0.333 | 0.335 |
| AGIEval | test | Llama7b | 0.210 | 0.210 | 0.206 |
| HumanEval | test | Llama7b | 0.128 | 0.128 | 0.128 |
| BoolQ | test | Llama7b | 0.742 | 0.742 | 0.754 |
| GSM8K | test | Llama7b | 0.102 | 0.103 | 0.100 |
| CEval | val | Llama7b | 0.408 | 0.404 | / |
| MMLU | test | Llama7b | 0.333 | 0.324 | 0.351 |
快速开始
# 配置模型和词表路径
# 词表路径地址:https://huggingface.co/yahma/llama-7b-hf
CHECKPOINT=../models/llama-7b-tp2-pp4/
VOCAB_FILE=../models/llama7b-hf/
# 配置任务和数据路径
DATA_PATH="dataset/boolq/test"
TASK="boolq"
# 配置生成参数
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--evaluation-batch-size 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT[images](sources%2Fimages)} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
# 开启评估
bash examples/llama/evaluate_llama_7B_ptd.sh
最重要的评估参数是 --max-new-tokens, 它表示模型输出的生成长度,比如,多项选择问题的输出长度就会明显比编码任务的输出长度小,该参数也很大程度上影响了模型的评估性能。通过--evaluation-batch-size参数可以设置多batch推理,提升模型评估性能。
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--evaluation-batch-size 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
评估脚本说明
基线数据集介绍
AGIEval
AGIEval 是一个用于评估大模型在人类认知和问题解决能力方面生成能力的基准数据集,它源于20个面向普通考生的官方、公开和高标准的入学和资格考试,相关参数可以设置为 TASK="agieval", --max-new-token=5。
HumanEval
HumanEval 是一个用于挑战代码生成问题的数据集,具有164个编程问题,包含函数签名,文档,函数主体和单元测试等。该数据的所有问题都是手写的,以确保它们不在训练集中,由于答案包含长代码,相关参数可以设置为 TASK="human_eval", --max-new-token=200。
BoolQ
BoolQ 是一个 yes/no 的问答数据集, 每一个问题包含了一个(问题,文章,答案)三元组,同时有文章的标题作为额外的选择性输入。BoolQ 数据集的评估相对简单,只需要配置 TASK="boolq", --max-new-token=1。
零样本评估的结果通常会被给定的 prompt 影响,可以尝试通过在 evaluation.py 中设置合适的 prompt 得到更高的分数,
# 通过修改 template 更新prompt
template = {instruction}
Big-Bench-Hard
Big-bench-hard 数据集是 BIG-Bench 的一个子集,专注于有挑战性的23个 BIG-Bench 任务, 涵盖文本理解、推理、逻辑推理、数学推理和常识推理等多个领域,相关参数可以设置为 TASK="bbh", --max-new-token=32,--evaluation-batch-size=4。
GSM8K
GSM8K 是一个有8.5k高质量小学数学应用题文本的数据集,每一个问题的回答是具体的数字。由于该数据集通常采用 few-shot 的形式进行评估,GSM8K的问题长度相对是比较长的,输出答案包含一整个思维链路,相关入参应该设置为 TASK="gsm8k", --max-new-token=200.
CEval
如 C-Eval 展示的, C-Eval 是一个针对大模型的综合中文评估数据集, 它由13948道多项选择题组成,涵盖52个不同学科和4个难度级别,划分为验证和测试集,验证集包含标签用于个人评估,测试集合的标签没有公开,如果想要知道模型得分,需要将结果 邮件发送给 C-Eval,相关参数可以设置为 TASK="ceval", --max-new-token=1。
MMLU
由于 MMLU 是一项多学科任务,并且需要进行 5-shot 评估,因此每个学科问题的长度差异很大。如果你想同时跑57个学科任务,可以尝试设置 TASK="mmlu", --max-new-token=1 。
在很多网站,MMLU 的精度会依据学科进行评估,57个学科主要属于四个大类, 因此该数据集也可以基于四个大类进行打分,网站 给出了具体的57个类别。
使用加速特性
ModelLink支持张量并行、流水线并行、序列并行、重计算、分布式优化器等多种加速算法和融合算子,下表为各种加速特性对应的使能开关:
| 加速特性 | 使能参数 |
|---|---|
| 张量并行 | --tensor-model-parallel-size |
| 流水线并行 | --pipeline-model-parallel-size |
| 流水并行动态划分 | --num-layer-list |
| 序列并行 | --sequence-parallel |
| 重计算 | --recompute-granularity |
| 分布式优化器 | --use-distributed-optimizer |
| DDP allreduce 掩盖 | --overlap-grad-reduce |
| DDP allgather 掩盖 | --overlap-param-gather |
| Flash attention | --use-flash-attn |
| Fused rmsnorm | --use-fused-rmsnorm |
| Fused swiglu | --use-fused-swiglu |
| mc2 | --use-mc2 |
| Fused rotary position embedding |
--use-fused-rotary-pos-emb |
torchrun $DISTRIBUTED_ARGS pretrain_gpt.py \
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size ${PP} \
--num-layer-list 1,2,2,2,1 \
--sequence-parallel \
--recompute-granularity full \
--recompute-method block \
--recompute-num-layers 72 \
--use-distributed-optimizer \
--use-flash-attn \
--use-fused-rmsnorm \
--use-fused-swiglu \
--overlap-grad-reduce \
--overlap-param-gather \
--use-fused-rotary-pos-emb \
--use-mc2 \
... \
...
基于昇腾芯片采集Profiling数据
Modellink支持基于昇腾芯片采集profiling数据,以提供对模型运行情况的分析,主要API如下:
--profile # 打开profiling采集数据开关
--profile-step-start 5 # 指定开启采集数据的步骤
--profile-step-end 6 # 指定结束采集数据的步骤,实际采集步数为 end-start,不包含end
--profile-ranks 0 1 2 3 4 # 指定采集数据的卡号,默认为0,可以设置为 0 1 2 3 4 5 6 7 8 9 列表指定全局卡号
--profile-level level2 # 数据采集水平,level0, 1, 2, 级别越高采集信息越多,默认为level0
--profile-with-cpu # 是否采集CPU数据,加入参数采集
--profile-with-stack # 采集指令运行堆栈,加入参数采集
--profile-with-memory # 是否采集内存,加入参数采集
--profile-record-shapes # 是否采集计算shape,加入参数采集
--profile-save-path ./profile_dir # profiling数据采集保存路径
致谢
ModelLink由华为公司的下列部门联合贡献 :
- 昇腾计算产品部
- 计算算法部
- 计算研究部
- 开源计算工具部
- 公共开发部
- 全球技术服务部
感谢来自社区的每一个PR,欢迎贡献 ModelLink