|
|
||
|---|---|---|
| ci | ||
| examples | ||
| modellink | ||
| sources/images | ||
| tests | ||
| .gitignore | ||
| convert_ckpt.py | ||
| evaluation.py | ||
| inference.py | ||
| LICENSE | ||
| merge_datasets.py | ||
| OWNERS | ||
| preprocess_data.py | ||
| pretrain_gpt.py | ||
| README.md | ||
| requirements.txt | ||
| SECURITYNOTE.md | ||
| setup.py | ||
![]()


ModelLink旨在为华为 昇腾芯片 上提供端到端的大语言模型方案, 包含模型,算法,以及下游任务。
ModelLink大模型方案概览
当前ModelLink支撑大模型使用功能:
- 制作预训练数据集/制作指令微调数据集 【NAIE】【昇腾】
- 预训练/全参微调/低参微调 【昇腾】【GTS】【NAIE】
- 流式推理/人机对话 【NAIE】【昇腾】
- 评估基线数据集【NAIE】
- 加速算法/融合算子/并行策略【昇腾】【计算算法部】【计算研究部】
- 基于昇腾芯片采集Profiling数据 【昇腾】
- Huggingface与Megatron-LM权重转换 【昇腾】【OCK】
- 基于昇腾芯片的确定性计算功能 【昇腾】
- 基于昇腾芯片的高可用特性 【计算研究部】
强化学习等特性持续研发中....
ModelLink版本维护策略
ModelLink版本有以下五个维护阶段:
| 状态 | 时间 | 说明 |
|---|---|---|
| 计划 | 1—3 个月 | 计划特性 |
| 开发 | 3 个月 | 开发特性 |
| 维护 | 6-12 个月 | 合入所有已解决的问题并发布版本,针对不同的ModelLink版本采取不同的维护策略,常规版本和长期支持版本维护周期分别为6个月和12个月 |
| 无维护 | 0—3 个月 | 合入所有已解决的问题,无专职维护人员,无版本发布 |
| 生命周期终止(EOL) | N/A | 分支不再接受任何修改 |
ModelLink已发布版本维护策略:
| ModelLink版本 | 维护策略 | 当前状态 | 发布时间 | 后续状态 | EOL日期 |
|---|---|---|---|---|---|
| bk_origin_23 | Demo | EOL | 2023 | 生命周期终止 | 2024/6/30 |
| 1.0 | 常规版本 | 维护 | 2024/03/30 | 预计2024/9/30起无维护 | |
| 1.1 | 常规版本 | 维护 | 2024/06/30 | 预计2024/12/30起无维护 |
配套版本与支持模型
【版本配套环境】
| 软件 | 版本 |
|---|---|
| Python | 3.8 |
| Driver | 在研版本 |
| Firmware | 在研版本 |
| CANN | 在研版本 |
| Torch | 2.1.0、2.2.0 |
| Torch_npu | 在研版本 |
【预训练集群性能与线性度】
ModelLink 通过模型并行与数据并行来训练大语言模型,为了演示如何使用多个昇腾芯片和模型大小进行扩展性训练,我们使用 GPT3-175B 稠密大模型,从128颗 NPU 扩展到 7968颗 NPU 进行实验,下图是实验数据:

图中呈现了对应集群规模下的 MFU 值与集群整体的 线性度情况. 计算公式已经放到社区,点击链接可进行参考:MFU计算公式,线性度计算公式
【现版本实测性能(硬件信息:Atlas 900 A2 PODc)】
下述列表中支持的模型,我们在examples/README.md中提供了相应的使用说明,里面有详细的模型训练、推理、评估流程
参数列中的超链接指向模型的预训练文件下载地址,模型列中的超链接指向更多的社区资源地址,包括Chat/Instruct权重等
认证【Pass】表示经过昇腾官方版本测试的模型,【Test】表示待测试模型
表中为开启 mc2 特性后预训练实测性能,该特性只在24RC2以上版本支持,本仓库代码层面默认关闭,若要使用,请参考加速算法与融合算子章节
| 模型 | 参数 | 序列 | 实现 | 集群 | 模式 | 性能 | 性能2 | 参考 | 贡献方 | 认证 |
|---|---|---|---|---|---|---|---|---|---|---|
| Aquila | 7B | 2K | Legacy | 1x8 | BF16 | 2849 | -- | 2874 | 【GTS】 | 【Pass】 |
| Aquila2 | 7B | 2K | Legacy | 1x8 | FP16 | 3323 | -- | 2673 | 【GTS】 | 【Test】 |
| 34B | 4K | Legacy | 2x8 | BF16 | 854 | -- | 732 | 【GTS】 | 【Test】 | |
| Baichuan | 7B | 4K | Legacy | 1x8 | FP16 | 2685 | -- | 2036 | 【GTS】 | 【Pass】 |
| 13B | 4K | Legacy | 1x8 | FP16 | 1213 | -- | 862 | 【GTS】 | 【Pass】 | |
| Baichuan2 | 7B | 4K | Legacy | 1x8 | BF16 | 2664 | -- | 3969 | 【昇腾】 | 【Pass】 |
| 13B | 4K | Mcore | 1x8 | BF16 | 1754 | -- | 2062 | 【昇腾】 | 【Pass】 | |
| Bloom | 7B1 | 2K | Legacy | 1x8 | FP16 | 2034 | -- | 2525 | 【昇腾】 | 【Pass】 |
| 176B | 2K | Legacy | 12x8 | BF16 | 100 | -- | 107 | 【昇腾】 | 【Pass】 | |
| ChatGLM3 | 6B | 8K | Mcore | 1x8 | FP16 | 4611 | -- | 4543 | 【昇腾】 | 【Test】 |
| 6B | 32K | Mcore | 1x8 | FP16 | 2650 | -- | 2887 | 【昇腾】 | 【Test】 | |
| 6B | 64K | Mcore | 2x8 | FP16 | 1724 | -- | 2097 | 【昇腾】 | 【Test】 | |
| GLM4 | 9B | 8K | Mcore | 1x8 | BF16 | 2221 | -- | 2708 | 【GTS】 | 【Test】 |
| 9B | 32K | Mcore | 2x8 | BF16 | 1482 | -- | 1752 | 【GTS】 | 【Test】 | |
| CodeLlama | 34B | 4K | Mcore | 2x8 | BF16 | 902 | -- | 762 | 【GTS】 | 【Test】 |
| InternLM | 7B | 2K | Legacy | 1x8 | BF16 | 2776 | -- | 2854 | 【昇腾】 | 【Pass】 |
| 65B | 2K | Legacy | 4x8 | BF16 | 341 | -- | 414 | 【昇腾】 | 【Pass】 | |
| InternLM2 | 20B | 4K | Mcore | 1x8 | BF16 | 1141 | -- | 1348 | 【GTS】 | 【Test】 |
| 32K | Mcore | 1x8 | BF16 | 4982 | -- | 5476 | 【GTS】 | 【Test】 | ||
| LLaMA | 7B | 2K | Legacy | 1x8 | FP16 | 3600 | -- | 3804 | 【昇腾】 | 【Pass】 |
| 13B | 2K | Legacy | 1x8 | FP16 | 1895 | -- | 2012 | 【昇腾】 | 【Pass】 | |
| 33B | 2K | Legacy | 4x8 | FP16 | 621 | -- | 776 | 【昇腾】 | 【Pass】 | |
| 65B | 2K | Legacy | 4x8 | BF16 | 348 | -- | 426 | 【昇腾】 | 【Pass】 | |
| LLaMA2 | 7B | 4K | Mcore | 1x8 | BF16 | 4672 | -- | 3850 | 【NAIE】 | 【Pass】 |
| 13B | 4K | Mcore | 1x8 | BF16 | 2016 | -- | 1920 | 【NAIE】 | 【Pass】 | |
| 34B | 4K | Mcore | 2x8 | BF16 | 810 | -- | 796 | 【GTS】 | 【Pass】 | |
| 70B | 4K | Mcore | 4x8 | BF16 | 439 | -- | 430 | 【GTS】 | 【Pass】 | |
| LLaMA3 | 8B | 8K | Mcore | 1x8 | BF16 | 2400 | -- | 2674 | 【GTS】 | 【Test】 |
| 70B | 8K | Mcore | 4x8 | BF16 | 353 | -- | 355 | 【GTS】 | 【Test】 | |
| LLaMA3.1 | 8B | 8K | Mcore | 1x8 | BF16 | 2280 | -- | 2520 | 【GTS】 | 【Test】 |
| 8B | 128K | Mcore | 4x8 | BF16 | 1297 | -- | -- | 【GTS】 | 【Test】 | |
| 70B | 8K | Mcore | 4x8 | BF16 | 399 | -- | -- | 【GTS】 | 【Test】 | |
| Qwen | 7B | 8K | Legacy | 1x8 | BF16 | 2499 | -- | 2867 | 【GTS】 | 【Pass】 |
| 14B | 2K | Legacy | 1x8 | BF16 | 1560 | -- | 1578 | 【GTS】 | 【Pass】 | |
| 72B | 8K | Legacy | 16x8 | BF16 | 285 | -- | 345 | 【GTS】 | 【Pass】 | |
| Qwen1.5 | 0.5B | 8K | Legacy | 1x8 | BF16 | 22834 | -- | 25306 | 【GTS】 | 【Test】 |
| 1.8B | 8K | Legacy | 1x8 | BF16 | 13029 | -- | 12181 | 【GTS】 | 【Test】 | |
| 4B | 8K | Legacy | 1x8 | BF16 | 5033 | -- | 5328 | 【GTS】 | 【Test】 | |
| 7B | 8K | Legacy | 1x8 | BF16 | 2862 | -- | 2621 | 【GTS】 | 【Test】 | |
| 14B | 8K | Legacy | 1x8 | BF16 | 1717 | -- | 1702 | 【GTS】 | 【Test】 | |
| 32B | 8K | Legacy | 4x8 | BF16 | 751 | -- | 708 | 【GTS】 | 【Test】 | |
| 72B | 8K | Mcore | 8x8 | BF16 | 339 | -- | 317 | 【GTS】 | 【Test】 | |
| 110B | 8K | Mcore | 8x8 | BF16 | 223 | -- | -- | 【GTS】 | 【Test】 | |
| CodeQwen1.5 | 7B | 8K | Mcore | 1x8 | BF16 | 3146 | -- | 3866 | 【GTS】 | 【Test】 |
| Qwen2 | 0.5B | 4K | Mcore | 1x8 | BF16 | 28618 | -- | 34859 | 【GTS】 | 【Test】 |
| 32K | Mcore | 1x8 | BF16 | 11338 | -- | -- | 【GTS】 | 【Test】 | ||
| 1.5B | 4K | Mcore | 1x8 | BF16 | 15456 | -- | 15603 | 【GTS】 | 【Test】 | |
| 32K | Mcore | 1x8 | BF16 | 7281 | -- | 8538 | 【GTS】 | 【Test】 | ||
| 7B | 4K | Mcore | 1x8 | BF16 | 4034 | -- | 4241 | 【GTS】 | 【Test】 | |
| 32K | Mcore | 1x8 | BF16 | 2040 | -- | 2045 | 【GTS】 | 【Test】 | ||
| 72B | 4K | Mcore | 4x8 | BF16 | 368 | -- | -- | 【GTS】 | 【Test】 | |
| Yi | 34B | 4K | Mcore | 2x8 | BF16 | 855 | -- | 730 | 【GTS】 | 【Test】 |
| Mixtral | 8x7B | 32K | Mcore | 8x8 | BF16 | 706 | -- | 837 | 【昇腾】 | 【Pass】 |
| 8x22B | 32K | Mcore | 8x8 | BF16 | 239 | 254 | -- | 【NAIE】 | 【Test】 | |
| 64K | Mcore | 8x8 | BF16 | -- | 215 | -- | 【NAIE】 | 【Test】 | ||
| Mistral | 7B | 32K | Mcore | 1x8 | BF16 | 2900 | -- | 2734 | 【NAIE】 | 【Pass】 |
| Gemma | 2B | 8K | Mcore | 1x8 | BF16 | 7067 | -- | 7602 | 【GTS】 | 【Test】 |
| 7B | 8K | Mcore | 1x8 | BF16 | 2939 | -- | 2607 | 【GTS】 | 【Test】 | |
| Gemma2 | 9B | 8K | Mcore | 1x8 | BF16 | 1713 | -- | 1595 | 【GTS】 | 【Test】 |
| 27B | 8K | Mcore | 2x8 | BF16 | 827 | -- | 800 | 【GTS】 | 【Test】 | |
| GPT3 | 175B | 2K | Legacy | 16x8 | FP16 | 153 | -- | -- | 【昇腾】 | 【Test】 |
| 15B | 2K | Legacy | 1x8 | FP16 | 1890 | -- | 1840 | 【昇腾】 | 【Test】 | |
| GPT4 | 4x13B | 128K | Mcore | 8x8 | BF16 | 424 | 1066 | -- | 【NAIE】 | 【Test】 |
| 4x16B | 128K | Mcore | 8x8 | BF16 | 351 | 918 | -- | 【昇腾】 | 【Test】 | |
| Grok1 | 8x5B | 8K | Mcore | 4x8 | BF16 | 1082 | -- | 993.8 | 【昇腾】 | 【Pass】 |
| DeepSeek-V2 | 60B | 8K | Mcore | 4x8 | BF16 | 1083 | -- | 1343 | 【昇腾】 | 【Test】 |
| MiniCPM | 2B | 4K | Mcore | 1x8 | BF16 | 7314 | -- | 7953 | 【NAIE】 | 【Test】 |
| 8x2B | 4K | Mcore | 1x8 | BF16 | 2981 | -- | 3172 | 【昇腾】 | 【Test】 |
Huggingface与Megatron-LM权重转换
ModelLink支持Huggingface、Megatron-Legacy以及Megatron-Core之间的权重格式互转,具体功能列表如下:
| 源格式 | 目标格式 | 支持特性 | 特性入参 |
|---|---|---|---|
| HuggingFace | Megatron-Legacy | 张量并行 | --target-tensor-parallel-size |
| 流水并行 | --target-pipeline-parallel-size | ||
| 流水并行动态划分 | --num-layer-list | ||
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage | ||
| Megatron-Core | 张量并行 | --target-tensor-parallel-size | |
| 流水并行 | --target-pipeline-parallel-size | ||
| 流水并行动态划分 | --num-layer-list | ||
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage | ||
| 专家并行 | --expert-model-parallel-size | ||
| Megatron-Legacy | Huggingface | 张量并行 | --target-tensor-parallel-size |
| 流水并行 | --target-pipeline-parallel-size | ||
| LoRA训练模块 | --lora-target-modules | ||
| LoRA权重 | --lora-load | ||
| LoRA r | --lora-r | ||
| LoRA alpa | --lora-alpha | ||
| Megatron-Core | 张量并行 | --target-tensor-parallel-size | |
| 流水并行 | --target-pipeline-parallel-size | ||
| 流水并行动态划分 | --num-layer-list | ||
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage | ||
| Megatron-Legacy | 张量并行 | --target-tensor-parallel-size | |
| 流水并行 | --target-pipeline-parallel-size | ||
| LoRA训练模块 | --lora-target-modules | ||
| LoRA权重 | --lora-load | ||
| LoRA r | --lora-r | ||
| LoRA alpa | --lora-alpha | ||
| Megatron-Core | Huggingface | 张量并行 | --target-tensor-parallel-size |
| 流水并行 | --target-pipeline-parallel-size | ||
| Megatron-Legacy | 张量并行 | --target-tensor-parallel-size | |
| 流水并行 | --target-pipeline-parallel-size | ||
| 流水并行动态划分 | --num-layer-list | ||
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage | ||
| Megatron-Core | 张量并行 | --target-tensor-parallel-size | |
| 流水并行 | --target-pipeline-parallel-size | ||
| 专家并行 | --expert-model-parallel-size | ||
| 流水并行动态划分 | --num-layer-list | ||
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage |
具体的权重转换功能命令介绍见examples/README.md
预训练加速算法与融合算子
ModelLink预训练支持张量并行、流水线并行等多种加速算法和融合算子,下表为各种加速特性对应的使能开关:
| 使用场景 | 特性名称 | 具体参数 | Mcore | Legacy |
|---|---|---|---|---|
| PTD并行 | 张量并行 | --tensor-model-parallel-size | Yes | Yes |
| 流水线并行 | --pipeline-model-parallel-size | Yes | Yes | |
| 流水线并行动态划分 | --num-layer-list | Yes | Yes | |
| 虚拟流水并行 | --num-layers-per-virtual-pipeline-stage | Yes | Yes | |
| 序列并行 | --sequence-parallel | Yes | Yes | |
| 分布式优化器 | --use-distributed-optimizer | Yes | Yes | |
| 长序列并行 | 长序列并行 | --context-parallel-size | Yes | No |
| 多并行方案 | --context-parallel-algo | Yes | No | |
| Send/recv掩盖加速 | --cp-send-recv-overlap | Yes | No | |
| MOE | MOE专家并行 | --expert-model-parallel-size | Yes | No |
| MOE重排通信优化 | --moe-permutation-async-comm | Yes | No | |
| GEMM | --moe-grouped-gemm | Yes | No | |
| 显存优化 | 参数副本复用 | --reuse-fp32-param | Yes | Yes |
| 激活函数重计算 | --recompute-activation-function | Yes | Yes | |
| Swap Attention | --swap-attention | Yes | Yes | |
| 重计算程度 | --recompute-granularity | Yes | Yes | |
| 重计算层数 | --recompute-num-layers | Yes | Yes | |
| 重计算方法 | --recompute-method | Yes | Yes | |
| PP-Stage重计算 | --enable-recompute-layers-per-pp-rank | Yes | Yes | |
| 融合算子 | Flash attention | --use-flash-attn | Yes | Yes |
| Fused rmsnorm | --use-fused-rmsnorm | Yes | Yes | |
| Fused swiglu | --use-fused-swiglu | Yes | Yes | |
| Fused rotary position embedding | --use-fused-rotary-pos-emb | Yes | Yes | |
| Sliding window attention | --sliding-window | Yes | Yes | |
| 通信 | 梯度reduce通算掩盖 | --overlap-grad-reduce | Yes | Yes |
| 权重all-gather通算掩盖 | --overlap-param-gather | Yes | No | |
| MC2 | --use-mc2 | Yes | Yes |
注意事项
- 具体的预训练方法见examples/README.md
- 如果需要开启MC2,需将
modellink\arguments.py文件下,validate_args_decorator函数中的args.use_mc2 = False语句注释掉。 - Legacy结构模型不支持MOE和长序列特性,可以在Mcore结构模型上使能MOE和长序列特性。
分布式指令微调
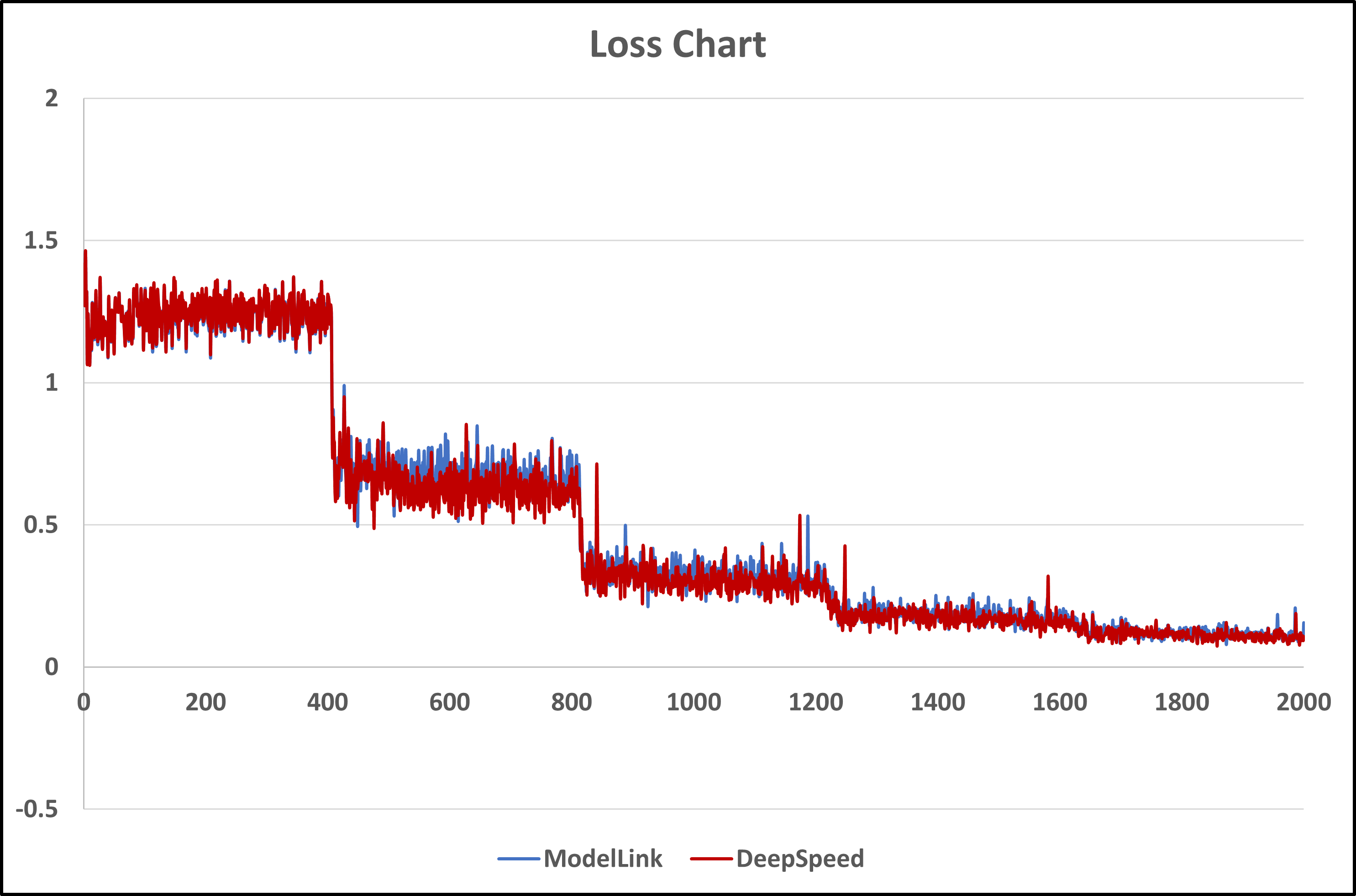
ModelLink支持指令微调,方案与DeepSpeed统一,并且微调效果在保持一致的前提下,ModelLink可以表现出优异性能。
【与DeepSpeed微调Loss对比】
| Llama2-7b模型与DeepSpeed微调5个epoch后的loss对比图
|
Qwen-7b模型与DeepSpeed微调4个epoch后的loss对比图
|
|---|

【Llama2-7b微调后对话效果对比】
| Question | ModelLink | DeepSpeed |
|---|---|---|
| What is the product of 6 and 2? | The product of 6 and 2 is 12. | The product of 6 and 2 is 12. |
| Look up the boiling point of water. | The boiling point of water is 100°C (212°F).. | The boiling point of water is 100 degrees Celsius (212 degrees Fahrenheit). |
| Generate a poem that expresses joy. | I open my arms and accept life's challenge,
Embracing all of life's uncertainty. A future of promise awaits, One that I can find in my fate. A journey full of hope and discovery, A journey that will never end in disappointment. For I have found the strength to keep going, Researching and learning, ever knowing. The future is mine, and mine alone, A future that I have to own, And I will never be alone, For I will have the courage to face all of my fears, And the joy of life will be mine forever. |
I am so happy, so thankful and blessed,
To have a heart that's full of cheer, My soul is on fire, my spirit runs free, My love is warm, my courage is high, My world is bright and my outlook is clear, My heart is light, my spirit runs free. I take each day with a positive outlook, My energy is so high, I can't be beat, My joy is real, my emotions run deep, My soul is full and my heart does soep. I am thankful for everything I have, My life is precious and my values true, My hope is high and my spirit runs free, My soul is full and my heart does soep. |
【现版本实测性能、显存(硬件信息:Atlas 900 A2 PODc)】
下述列表中的模型,我们在examples/README.md中提供了相应的使用说明,里面有详细的模型微调、推理、评估流程. 其中性能的单位是samples/s。
| 模型 | --prompt-type | ModelLink + NPU | DeepSpeed + NPU | DeepSpeed + 参考 | |||
|---|---|---|---|---|---|---|---|
| 序列长度 | 性能 | 序列长度 | 性能 | 序列长度 | 性能 | ||
| llama2-7b | llama2 | - | - | - | - | - | - |
| qwen-7b | qwen | - | - | - | - | - | - |
上述列表中的数据均为实测数据,且具体微调的数据集均保持一致。
【指令微调特性】
| 特性名称 | 特性入参 | |
|---|---|---|
| 支持数据集格式 | Alpaca风格、Sharegpt风格 | |
| 微调数据预处理特性 | 数据集字段映射 | --map-keys |
| prompt模板 | --prompt-type | |
| 数据集处理器 | --handler-name | |
| 微调特性 | 动态padding | --variable-seq-lengths |
| prompt模板 | --prompt-type | |
| 微调后推理对话特性 | 历史对话记录轮数 | --history-turns |
| hf对话模板 | --hf-chat-template | |
| prompt模板 | --prompt-type | |
| 微调后评估特性 | 评估数据集语言 | --eval-language |
| hf对话模板 | --hf-chat-template | |
| prompt模板 | --prompt-type | |
| 指令微调模板支持列表 | ['empty', 'default', 'chatglm3_system', 'chatml', 'qwen', 'llama2', 'llama3', 'alpaca'] | |
基于昇腾芯片采集Profiling数据
Modellink支持基于昇腾芯片采集profiling数据,以提供对模型运行情况的分析,主要API如下:
--profile # 打开profiling采集数据开关
--profile-step-start 5 # 指定开启采集数据的步骤
--profile-step-end 6 # 指定结束采集数据的步骤,实际采集步数为 end-start,不包含end
--profile-ranks 0 1 2 3 4 # 指定采集数据的卡号,默认为-1,表示采集所有rank的profiling数据,可以设置为 0 1 2 3 4 5 6 7 8 9 列表指定全局卡号
--profile-level level2 # 数据采集水平,level0, 1, 2, 级别越高采集信息越多,默认为level0
--profile-with-cpu # 是否采集CPU数据,加入参数采集
--profile-with-stack # 采集指令运行堆栈,加入参数采集
--profile-with-memory # 是否采集内存,加入参数采集
--profile-record-shapes # 是否采集计算shape,加入参数采集
--profile-save-path ./profile_dir # profiling数据采集保存路径
基于昇腾芯片的确定性计算功能
昇腾芯片默认采用了不确定计算加速模型训练,有时为了重复实验与对比实验需要确定性的计算结果,ModelLink使能确定性计算的开关如下:
- 启动命令中加入开关
--use-deter-comp
- 环境变量中加入开关
export HCCL_DETERMINISTIC=True
基于昇腾芯片的高可用特性
分布式优化器的思想是通过将优化器状态均匀地分布在数据并行组中来节省内存。基于该思想,设计了将数据并行组切分成两个副本数据并行组的方案,副本优化器将优化器状态均匀分布在副本数据并行组,实现优化器状态均有备份。结合华为自研的高可用框架,可实现以下功能:
- 训练过程中,支持故障场景保存临终checkpoint,训练结果0损失。
- 训练过程中,支持HBM的UCE故障检测,并完成在线修复,达到Step级重计算。
开启高可用特性时,副本优化器使用的静态内存有所增加,每个参数的理论字节数为(其中“d”是数据并行大小):
| Non-distributed optim | Distributed optim | Replica optim | |
|---|---|---|---|
| fp16/bf16 param, fp16/bf16 grads | 20 | 4 + 16/d | 4 + 32/d |
| fp16/bf16 param, fp32 grads | 18 | 6 + 12/d | Supporting |
| fp32 param, fp32 grads | 16 | 8 + 8/d | Supporting |
- 启动命令中加入开关,并安装华为自研高可用框架mindio_ttp.whl
- mindio_ttp相关说明:https://www.hiascend.com/document/detail/zh/mindx-dl/60rc1/mindio/mindiottp
--enable-high-availability #使能高可用特性的总开关
--enable-optimizer-state-local-copy #使能保存上一步优化器状态,内存会进一步增加,默认可关闭
致谢
ModelLink由华为公司的下列部门联合贡献 :
- 昇腾计算产品部
- 计算算法部
- 计算研究部
- 开源计算工具部: OCK
- 公共开发部:NAIE
- 全球技术服务部:GTS
感谢来自社区的每一个PR,欢迎贡献 ModelLink