|
|
||
|---|---|---|
| .. | ||
| evaluate_qwen15_0point5b_ptd.sh | ||
| evaluate_qwen15_1point8b_ptd.sh | ||
| evaluate_qwen15_4b_ptd.sh | ||
| evaluate_qwen15_7b_ptd.sh | ||
| evaluate_qwen15_14b_ptd.sh | ||
| evaluate_qwen15_32b_ptd.sh | ||
| evaluate_qwen15_72b_ptd.sh | ||
| generate_qwen15_0point5b_ptd.sh | ||
| generate_qwen15_1point8_ptd.sh | ||
| generate_qwen15_4b_ptd.sh | ||
| generate_qwen15_7b_ptd.sh | ||
| generate_qwen15_14b_ptd.sh | ||
| generate_qwen15_32b_lora_chat_ptd.sh | ||
| generate_qwen15_32b_ptd.sh | ||
| generate_qwen15_72b_chat_ptd.sh | ||
| generate_qwen15_72b_lora_chat_ptd.sh | ||
| pretrain_qwen15_0point5b_ptd.sh | ||
| pretrain_qwen15_1point8b_ptd.sh | ||
| pretrain_qwen15_4b_ptd.sh | ||
| pretrain_qwen15_7b_ptd.sh | ||
| pretrain_qwen15_14b_ptd.sh | ||
| pretrain_qwen15_32b_ptd.sh | ||
| pretrain_qwen15_72b_ptd.sh | ||
| README_en.md | ||
| README.md | ||
| tune_qwen15_32b_ptd.sh | ||
| tune_qwen15_72b_ptd.sh | ||
Qwen1.5 \color{black}{\rm\tiny{【Model}} \color{black}{\rm\tiny{contributed}} \color{black}{\rm\tiny{by}} \color{black}{\rm\tiny{community】}}
简体中文 | English
Contents
Qwen1.5-0.5B
Training-0.5B
Here's a hardware summary of pre-training Qwen-0.5B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install packages pip install -r requirements.txt # install torch 和 torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip3 install -e . cd .. -
Download Qwen1.5-0.5B pretrained weights and tokenizer
#!/bin/bash mkdir ./model_from_hf/qwen15-0.5b-hf/ cd ./model_from_hf/qwen15-4b-hf/ wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/model.safetensors wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-0.5B/resolve/main/vocab.json cd ../../ -
weight conversion in ptd mode
4.1 Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # convert to ptd weights python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --params-dtype bf16 \ --add-qkv-bias \ --load-dir ./model_from_hf/qwen15-0.5b-hf/ \ --save-dir ./model_weights/qwen15-0.5b-hf-v0.1-tp1-pp1/ \ --tokenizer-model ./model_from_hf/qwen15-0.5b-hf/tokenizer.json4.2 Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./ckpt/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --add-qkv-bias \ --save-dir ./model_from_hf/qwen15-0.5b-hf/ # <-- Fill in the original HF model path here, new weights will be saved in ./model_from_hf/qwen15-0.5b-hf/mg2hg/ -
pre-training
5.1 prepare dataset
Download the Qwen1.5-0.5B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/qwen15-0.5b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-0.5b-hf/ \ --output-prefix ./dataset/qwen15-0.5b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF5.2 pre-training
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/qwen15-0.5b-hf/" TOKENIZER_PATH="./model_from_hf/qwen15-0.5b-hf" #tokenizer path DATA_PATH="./dataset/qwen15-0.5b-hf/alpaca_text_document" #processed dataset CKPT_LOAD_DIR="./model_weights/qwen15-0.5b-hf-v0.1-tp1-pp1"Config Qwen1.5-0.5B pre-training script: examples/qwen15/pretrain_qwen15_0point5b_ptd.sh
-
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-0.5B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/qwen15-0.5b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-0.5b-hf/ \ --output-prefix ./finetune_dataset/qwen15-0.5b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning The configuration script for full parameters fine-tuning is basically the same as that for pretrain_qwen15_0point5b_ptd.sh.The difference is that the dataset and the training parameter is-instruction-dataset are added.
Add the fine-tuning parameter '--finetune' so that fine-tuning starts from the first step.
DATA_PATH="./finetune_dataset/qwen15-0.5b-hf/alpaca" TOKENIZER_PATH="./model_from_hf/qwen15-0.5b-hf/" CKPT_PATH="./model_weights/qwen15-0.5b-hf-v0.1-tp1-pp1/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-type PretrainedFromHF \ --tokenizer-name-or-path ${TOKENIZER_PATH} \ --tokenizer-not-use-fast \
Performance-0.5B
Machine performance
The performance of Qwen1.5-0.5B in Ascend NPU and Reference:
| Device | Model | total Iterations | throughput rate (tokens/s/p) |
|---|---|---|---|
| NPUs | Qwen1.5-0.5B | 2000 | 22834 |
| Reference | Qwen1.5-0.5B | 2000 | 25306 |
Inference-0.5B
Config Qwen1.5-0.5B inference script: examples/qwen15/generate_qwen1.5_0point5b_ptd.sh
# modify the script according to your own ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/qwen15-0.5b-hf-v0.1-tp1-pp1"
TOKENIZER_PATH="./model_from_hf/qwen15-0.5b-hf/"
Config Qwen1.5-0.5B inference script
bash examples/qwen15/generate_qwen15_0point5b_ptd.sh
Some inference samples are as follows:

Evaluation-0.5B
We use MMLU benchmark to evaluate our model. Benchmark Download here. Config Qwen1.5-0.5B evaluation script: examples/qwen15/evaluate_qwen15_0point5b_ptd.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
TOKENIZER_PATH="./model_from_hf/qwen15-0.5b-hf/" #tokenizer path
CHECKPOINT="./model_weights/qwen15-0.5b-hf-v0.1-tp1-pp1" #model path
# configure task and data path
DATA_PATH="./mmlu/data/test/"
TASK="mmlu"
Launch evaluation script:
bash examples/qwen15/evaluate_qwen15_0point5b_ptd.sh
Evaluation results
| dataset | subject_num | question_num | reference_acc | NPU acc |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 0.318 | 0.318 |
Qwen1.5-1.8B
Training-1.8B
Here's a hardware summary of pre-training Qwen-1.8B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install packages pip install -r requirements.txt # install torch 和 torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip3 install -e . cd .. -
Download Qwen1.5-1.8B pretrained weights and tokenizer
#!/bin/bash mkdir ./model_from_hf/qwen15-4b-hf/ cd ./model_from_hf/qwen15-4b-hf/ wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/model.safetensors wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-1.8B/resolve/main/vocab.json cd ../../ -
weight conversion in ptd mode
4.1 Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # convert to ptd weights python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --params-dtype bf16 \ --add-qkv-bias \ --load-dir ./model_from_hf/qwen15-1.8b-hf/ \ --save-dir ./model_weights/qwen15-1.8b-hf-v0.1-tp1-pp1/ \ --tokenizer-model ./model_from_hf/qwen15-1.8b-hf/tokenizer.json4.2 Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./ckpt/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --add-qkv-bias \ --save-dir ./model_from_hf/qwen15-1.8b-hf/ # <-- Fill in the original HF model path here, new weights will be saved in ./model_from_hf/qwen15-1.8b-hf/mg2hg/ -
pre-training
5.1 prepare dataset
Download the Qwen1.5-1.8B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/qwen15-1.8b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-1.8b-hf/ \ --output-prefix ./dataset/qwen15-1.8b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF5.2 pre-training
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/qwen15-1.8b-hf/" TOKENIZER_PATH="./model_from_hf/qwen15-1.8b-hf" #tokenizer path DATA_PATH="./dataset/qwen15-1.8b-hf/alpaca_text_document" #processed dataset CKPT_LOAD_DIR="./model_weights/qwen15-1.8b-hf-v0.1-tp1-pp1"Config Qwen1.5-1.8B pre-training script: examples/qwen15/pretrain_qwen15_1point8b_ptd.sh
-
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-1.8B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/qwen15-1.8b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-1.8b-hf/ \ --output-prefix ./finetune_dataset/qwen15-1.8b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning The configuration script for full parameters fine-tuning is basically the same as that for pretrain_qwen15_1point8b_ptd.sh.The difference is that the dataset and the training parameter is-instruction-dataset are added.
Add the fine-tuning parameter '--finetune' so that fine-tuning starts from the first step.
DATA_PATH="./finetune_dataset/qwen15-1.8b-hf/alpaca" TOKENIZER_PATH="./model_from_hf/qwen15-1.8b-hf/" CKPT_PATH="./model_weights/qwen15-1.8b-hf-v0.1-tp1-pp1/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-type PretrainedFromHF \ --tokenizer-name-or-path ${TOKENIZER_PATH} \ --tokenizer-not-use-fast \
Performance-1.8B
Machine performance
The performance of Qwen1.5-1.8B in Ascend NPU and Reference:
| Device | Model | total Iterations | throughput rate (tokens/s/p) |
|---|---|---|---|
| NPUs | Qwen1.5-1.8B | 2000 | 13029 |
| Reference | Qwen1.5-1.8B | 2000 | 12181 |
Inference-1.8B
Config Qwen1.5-1.8B inference script: examples/qwen1.5/generate_qwen15_1point8b_ptd.sh
# modify the script according to your own ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/qwen15-1.8b-hf-v0.1-tp1-pp1"
TOKENIZER_PATH="./model_from_hf/qwen15-1.8b-hf/"
Config Qwen1.5-1.8B inference script
bash examples/qwen1.5/generate_qwen1.5_1point8b_ptd.sh
Some inference samples are as follows:
Evaluation-1.8B
We use MMLU benchmark to evaluate our model. Benchmark Download here. Config Qwen1.5-1.8B evaluation script: examples/qwen15/evaluate_qwen15_1point8b_ptd.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
TOKENIZER_PATH="./model_from_hf/qwen15-1.8b-hf/" #tokenizer path
CHECKPOINT="./model_weights/qwen15-1.8b-hf-v0.1-tp1-pp1" #model path
# configure task and data path
DATA_PATH="./mmlu/data/test/"
TASK="mmlu"
Launch evaluation script:
bash examples/qwen15/evaluate_qwen15_1point8b_ptd.sh
Evaluation results
| dataset | subject_num | question_num | reference_acc | NPU acc |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 0.468 | 0.462 |
Qwen1.5-4B
Training-4B
Here's a hardware summary of pre-training Qwen-4B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install other packages pip install -r requirements.txt # install torch 和 torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip3 install -e . cd .. -
Download Qwen1.5-4B pretrained weights and tokenizer
#!/bin/bash mkdir ./model_from_hf/qwen15-4b-hf/ cd ./model_from_hf/qwen15-4b-hf/ wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/model-00001-of-00002.safetensors wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/model-00002-of-00002.safetensors wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-4B/resolve/main/vocab.json cd ../../ -
weight conversion in ptd mode
4.1 Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # convert to ptd weights python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 2 \ --params-dtype bf16 \ --add-qkv-bias \ --load-dir ./model_from_hf/qwen15-4b-hf/ \ --save-dir ./model_weights/qwen15-4b-hf-v0.1-tp1-pp2/ \ --tokenizer-model ./model_from_hf/qwen15-4b-hf/tokenizer.json4.2 Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./ckpt/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --add-qkv-bias \ --save-dir ./model_from_hf/qwen15-4b-hf/ # <-- Fill in the original HF model path here, new weights will be saved in ./model_from_hf/qwen15-4b-hf/mg2hg/ -
pre-training
5.1 prepare dataset
Download the Qwen1.5-4B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/qwen15-4b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-4b-hf/ \ --output-prefix ./dataset/qwen15-4b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF5.2 pre-training
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/qwen15-4b-hf/" TOKENIZER_PATH="./model_from_hf/qwen15-4b-hf" #tokenizer path DATA_PATH="./dataset/qwen15-4b-hf/alpaca_text_document" #processed dataset CKPT_LOAD_DIR="./model_weights/qwen15-4b-hf-v0.1-tp1-pp2"Config Qwen1.5-4B pre-training script: examples/qwen15/pretrain_qwen15_4b_ptd.sh
-
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-4B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/qwen15-4b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/qwen15-4b-hf/ \ --output-prefix ./finetune_dataset/qwen15-4b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning The configuration script for full parameters fine-tuning is basically the same as that for pretrain_qwen15_4b_ptd.sh.The difference is that the dataset and the training parameter is-instruction-dataset are added.
Add the fine-tuning parameter '--finetune' so that fine-tuning starts from the first step.
DATA_PATH="./finetune_dataset/qwen15-4b-hf/alpaca" TOKENIZER_PATH="./model_from_hf/qwen15-4b-hf/" CKPT_PATH="./model_weights/qwen15-4b-hf-v0.1-tp1-pp2/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-type PretrainedFromHF \ --tokenizer-name-or-path ${TOKENIZER_PATH} \ --tokenizer-not-use-fast \
Performance-4B
Machine performance
The performance of Qwen1.5-4B in Ascend NPU and Reference:
| Device | Model | total Iterations | throughput rate (tokens/s/p) |
|---|---|---|---|
| NPUs | Qwen1.5-4B | 1000 | 5033 |
| Reference | Qwen1.5-4B | 1000 | 5328 |
Inference-4B
Config Qwen1.5-4B inference script: examples/qwen15/generate_qwen15_4b_ptd.sh
# modify the script according to your own ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/qwen15-4b-hf-v0.1-tp1-pp2"
TOKENIZER_PATH="./model_from_hf/qwen15-4b-hf/"
Config Qwen1.5-4B inference script
bash examples/qwen15/generate_qwen15_4b_ptd.sh
Some inference samples are as follows:
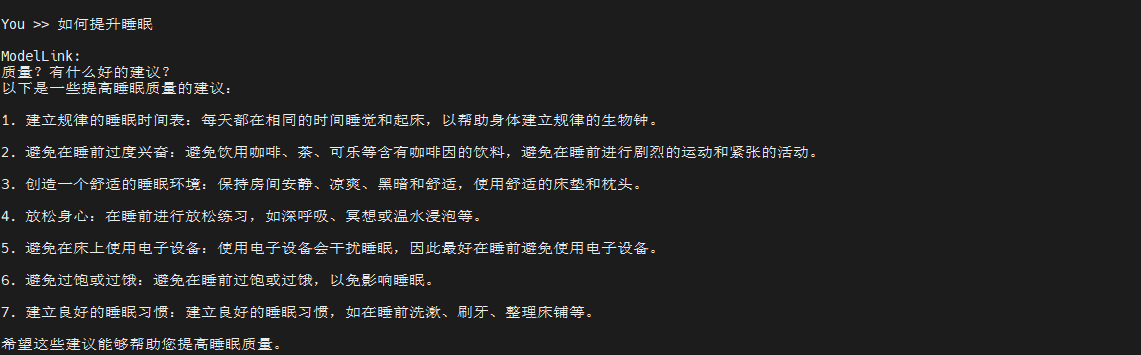
Evaluation-4B
We use MMLU benchmark to evaluate our model. Benchmark Download here. Config Qwen1.5-4B evaluation script: examples/qwen15/evaluate_qwen15_4b_ptd.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
TOKENIZER_PATH="./model_from_hf/qwen15-4b-hf/" #tokenizer path
CHECKPOINT="./model_weights/qwen15-4b-hf-v0.1-tp1-pp2" #model path
# configure task and data path
DATA_PATH="./mmlu/data/test/"
TASK="mmlu"
Launch evaluation script:
bash examples/qwen15/evaluate_qwen15_4b_ptd.sh
Evaluation results
| dataset | subject_num | question_num | reference_acc | NPU acc |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 0.561 | 0.550 |
Qwen1.5-7B
Training
Here's a hardware summary of pre-training Qwen1.5-7B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install other packages pip install -r requirements.txt # install torch and torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip install -e . cd .. -
Prepare pretrained weights and tokenizer Download the Qwen1.5-7B checkpoint from here
mkdir ./model_from_hf/Qwen1.5-7B/ cd ./model_from_hf/Qwen1.5-7B/ wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/model-00001-of-00004.safetensors wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/model-00002-of-00004.safetensors wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/model-00003-of-00004.safetensors wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/model-00004-of-00004.safetensors wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/special_tokens_map.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-7B/resolve/main/vocab.json cd ../../ -
Weights convert
Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --target-pipeline-parallel-size 1 \ --make-vocab-size-divisible-by 16 \ --load-dir ./model_from_hf/Qwen1.5-7B/ \ --save-dir ./model_weights/Qwen1.5-7B-v0.1-tp8-pp1/ \ --tokenizer-model ./model_from_hf/Qwen1.5-7B/tokenizer.json \ --add-qkv-bias \ --params-dtype bf16Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --add-qkv-bias \ --load-dir ./model_weights/Qwen1.5-7B-v0.1-tp8-pp1 \ --save-dir ./model_from_hf/Qwen1.5-7B # Fill in the original HF model path here, new weights will be saved in 1.5/mg2hg/ -
Pre-training
5.1 prepare dataset
Download the Qwen1.5-7B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/Qwen1.5-7B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-7B \ --output-prefix ./dataset/Qwen1.5-7B/alpaca \ --tokenizer-type PretrainedFromHF \ --seq-length 8192 \ --workers 4 \ --log-interval 10005.2 pre-training
Config Qwen1.5-7B pre-training script: examples/qwen15/pretrain_qwen15_7b_ptd.sh
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/Qwen1.5-7B/" TOKENIZER_PATH="./model_from_hf/Qwen1.5-7B" #tokenizer path DATA_PATH="./dataset/Qwen1.5-7B/alpaca_text_document" #processed dataset CKPT_LOAD_DIR="./model_weights/Qwen1.5-7B-v0.1-tp8-pp1"Multi-machine training requires the addition of parameter
--overlap-grad-reduce.Launch Qwen1.5-7B pre-training script: examples/qwen15/pretrain_qwen15_7b_ptd.sh
bash examples/qwen15/pretrain_qwen15_7b_ptd.sh -
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-7B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/Qwen1.5-7B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-7B/ \ --output-prefix ./finetune_dataset/Qwen1.5-7B/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning
The configuration script with the fine-tuning parameters is basically the same as the pre-training script.
The difference is the dataset, and add the training parameter
--is-instruction dataset, add the fine-tuning parameter--finetune, add the pre-training weight loading parameter--load, so that the fine-tuning starts from the first step, modify the tokenizer parameter.Modified as follows:
CKPT_LOAD_DIR="./model_weights/Qwen1.5-7B-v0.1-tp8-pp1/" CKPT_SAVE_DIR="./ckpt/Qwen1.5-7B/" DATA_PATH="./finetune_dataset/Qwen1.5-7B/alpaca" TOKENIZER_PATH="./model_from_hf/Qwen1.5-7B/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-not-use-fast \
Performance
Machine performance
The performance of Qwen1.5-7B in Ascend NPU and Reference:
| Device | Model | throughput rate (tokens/s/p) |
|---|---|---|
| NPUs | Qwen1.5-7B | 2862 |
| Reference | Qwen1.5-7B | 2621 |
Inference
Config Qwen1.5-7B inference script: examples/qwen15/generate_qwen15_7b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Qwen1.5-7B-v0.1-tp8-pp1"
TOKENIZER_PATH="./model_from_hf/Qwen1.5-7B"
Launch Qwen1.5-7B inference script: examples/qwen15/generate_qwen15_7b_ptd.sh
bash examples/qwen15/generate_qwen15_7b_ptd.sh
Some inference samples are as follows:

Evaluation
We use the CEval benchmark and MMLU benchmark to evaluate our model.
Config Qwen1.5-7B evaluation script: examples/qwen15/evaluate_qwen15_7b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# Modify the model parameter path and vocabulary path
TOKENIZER_PATH="./model_from_hf/Qwen1.5-7B/" # vocabulary path
CHECKPOINT="./model_weights/Qwen1.5-7B-v0.1-tp8-pp1/" # parameter path
# Configure the task type and dataset path
DATA_PATH="./mmlu/data/test/" # "./ceval/val/" for ceval task
TASK="mmlu" # "ceval" for ceval task
Launch Qwen1.5-7B evaluation
bash examples/qwen15/evaluate_qwen15_7b_ptd.sh
| Task | Subset | Question | OpenSource | NPU |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 61.0 | 60.3 |
Qwen1.5-14B
Training
Here's a hardware summary of pre-training Qwen1.5-14B:
| Hardware | Value |
|---|---|
| NPU | 8 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install torch and torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip install -e . cd .. # install other packages pip install -r requirements.txt -
Prepare pretrained weights and tokenizer Download the Qwen1.5-14B checkpoint from here
mkdir ./model_from_hf/Qwen1.5-14B/ cd ./model_from_hf/Qwen1.5-14B/ wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/special_tokens_map.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/vocab.json wget https://huggingface.co/Qwen/Qwen1.5-14B/blob/main/model-00001-of-00008.safetensors ... cd ../../ -
Weights convert
Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --target-pipeline-parallel-size 1 \ --make-vocab-size-divisible-by 16 \ --load-dir ./model_from_hf/Qwen1.5-14B/ \ --save-dir ./model_weights/Qwen1.5-14B-v0.1-tp8-pp1/ \ --tokenizer-model ./model_from_hf/Qwen1.5-14B/tokenizer.json \ --add-qkv-bias \ --params-dtype bf16Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# Modify the ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --add-qkv-bias \ --load-dir ./model_weights/Qwen1.5-14B-v0.1-tp8-pp1 \ --save-dir ./model_from_hf/Qwen1.5-14B # Fill in the original HF model path here, new weights will be saved in ./model_from_hf/Qwen1.5-14B/mg2hg/ -
Pre-training
5.1 prepare dataset
Download the Qwen1.5-14B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/Qwen1.5-14B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-14B \ --output-prefix ./dataset/Qwen1.5-14B/alpaca \ --tokenizer-type PretrainedFromHF \ --seq-length 8192 \ --workers 4 \ --log-interval 10005.2 pre-training
Config Qwen1.5-14B pre-training script: examples/qwen15/pretrain_qwen15_14b_ptd.sh
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/Qwen1.5-14B/" TOKENIZER_PATH="./model_from_hf/Qwen1.5-14B" #tokenizer path DATA_PATH="./dataset/Qwen1.5-14B/alpaca_text_document" #processed dataset CKPT_LOAD_DIR="./model_weights/Qwen1.5-14B-v0.1-tp8-pp1"Multi-machine training requires the addition of parameter
--overlap-grad-reduce.Launch Qwen1.5-14B pre-training script: examples/qwen15/pretrain_qwen15_14b_ptd.sh
bash examples/qwen15/pretrain_qwen15_14b_ptd.sh -
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-14B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/Qwen1.5-14B/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-14B/ \ --output-prefix ./finetune_dataset/Qwen1.5-14B/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning
The configuration script with the fine-tuning parameters is basically the same as the pre-training script.
The difference is the dataset, and add the training parameter
--is-instruction dataset, add the fine-tuning parameter--finetune, add the pre-training weight loading parameter--load, so that the fine-tuning starts from the first step, modify the tokenizer parameter.Modified as follows:
CKPT_LOAD_DIR="./model_weights/Qwen1.5-14B-v0.1-tp8-pp1/" CKPT_SAVE_DIR="./ckpt/Qwen1.5-14B/" DATA_PATH="./finetune_dataset/Qwen1.5-14B/alpaca" TOKENIZER_PATH="./model_from_hf/Qwen1.5-14B/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-type PretrainedFromHF \ --tokenizer-name-or-path ${TOKENIZER_PATH} \ --tokenizer-not-use-fast \
Performance
Machine performance
The performance of Qwen1.5-14B in Ascend NPU and Reference:
| Device | Model | throughput rate (tokens/s/p) |
|---|---|---|
| NPUs | Qwen1.5-14B | 1717.8 |
| Reference | Qwen1.5-14B | 1702.2 |
Inference
Config Qwen1.5-14B inference script: examples/qwen15/generate_qwen15_14b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Qwen1.5-14B-v0.1-tp8-pp1"
TOKENIZER_PATH="./model_from_hf/Qwen1.5-14B"
Launch Qwen1.5-14B inference script: examples/qwen15/generate_qwen15_14b_ptd.sh
bash examples/qwen15/generate_qwen15_14b_ptd.sh
Some inference samples are as follows:

Evaluation
We use the CEval benchmark and MMLU benchmark to evaluate our model.
Config Qwen1.5-14B evaluation script: examples/qwen15/evaluate_qwen15_14b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# Modify the model parameter path and vocabulary path
TOKENIZER_PATH="./model_from_hf/Qwen1.5-14B/" # vocabulary path
CHECKPOINT="./model_weights/Qwen1.5-14B-v0.1-tp8-pp1/" # parameter path
# Configure the task type and dataset path
DATA_PATH="./mmlu/data/test/" # "./ceval/val/" for ceval task
TASK="mmlu" # "ceval" for ceval task
Launch Qwen1.5-14B evaluation
bash examples/qwen15/evaluate_qwen15_14b_ptd.sh
| Task | Subset | Question | OpenSource | NPU |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 67.6 | 67.3 |
Qwen1.5-32B
Training
| Hardware | Seq-length | Value |
|---|---|---|
| NPU | 8k | 32 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install other packages pip install -r requirements.txt # install torch and torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip3 install -e . cd .. -
Prepare pretrained weights and tokenizer
Download the Qwen1.5-32B checkpoint from here
mkdir ./model_from_hf/Qwen1.5-32B/ cd ./model_from_hf/Qwen1.5-32B/ wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00001-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00002-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00003-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00004-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00005-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00006-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00007-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00008-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00009-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00010-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00011-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00012-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00013-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00014-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00015-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00016-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model-00017-of-00017.safetensors wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-32B/blob/main/vocab.json cd ../../ -
weight conversion in ptd mode
4.1 Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # convert to ptd weights python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --target-pipeline-parallel-size 4 \ --num-layers-per-virtual-pipeline-stage 2 \ --params-dtype bf16 \ --load-dir ./model_from_hf/Qwen1.5-32B/ \ --save-dir ./model_weights/Qwen1.5-32B-v0.1-tp8-pp4/ \ --tokenizer-model ./model_from_hf/Qwen1.5-32B/tokenizer.json \ --add-qkv-biasNote: The --num-layers-per-virtual-pipeline-stage parameter only works if --target-pipeline-parallel-size > 2, if target-pipeline-parallel-size does not satisfy the >2 condition, remove it from the script --num-layers-per-virtual-pipeline-stage parameter in the script.
4.2 Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./model_weights/Qwen1.5-32B-v0.1-tp8-pp4/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --num-layers-per-virtual-pipeline-stage 2 \ --add-qkv-bias \ --save-dir ./model_from_hf/Qwen1.5-32B/ # Fill in the original HF model path here, new weights will be saved in ./model_from_hf/Qwen-7B/mg2hg/Weight conversion is suitable for pre-training, fine-tuning, inference and evaluation. Adjust the parameters
target-tensor-parallel-sizeandtarget-pipeline-parallel-sizeaccording to different tasks. -
pre-training
5.1 Prepare dataset Download the Qwen1.5-32B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/qwen-1.5-32B-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-32B/ \ --output-prefix ./dataset/qwen-1.5-32B-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF5.2 pre-training
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/Qwen1.5-32B/" TOKENIZER_PATH="./model_from_hf/Qwen1.5-32B/" # tokenizer path DATA_PATH="./dataset/Qwen1.5-32B/alpaca_text_document" # processed dataset CKPT_LOAD_DIR="./model_weights/Qwen1.5-32B-v0.1-tp8-pp4-vpp2/"Launch Qwen1.5-32B pre-training script: examples/qwen15/pretrain_qwen15_32b_ptd.sh
bash examples/qwen15/pretrain_qwen15_32b_ptd.shNote:
- If using multi machine training, and no data sharing configuration on the mechines, it's necessary to add the parameter
--no-shared-storage. This parameter will determine whether non master nodes need to load data based on distributed parameters, and check the corresponding cache and generated data. - The --num-layers-per-virtual-pipeline-stage parameter only works if --target-pipeline-parallel-size > 2, if target-pipeline-parallel-size does not satisfy the >2 condition, remove it from the script --num-layers-per-virtual-pipeline-stage parameter in the script.
- If using multi machine training, and no data sharing configuration on the mechines, it's necessary to add the parameter
-
fine-tuning 6.1 Prepare fine-tuning dataset Download the Qwen1.5-32B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/qwen-1.5-32b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/ train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-32B/ \ --output-prefix ./finetune_dataset/qwen-1.5-32b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning The configuration script for full parameters fine-tuning is basically the same as that for pretrain_qwen15_32b_ptd.sh.The difference is that the dataset and the training parameter is-instruction-dataset are added.
Add the fine-tuning parameter
--finetuneand add pretrained-weight load parameter--load, so that fine-tuning starts from the first step.DATA_PATH="./finetune_dataset/qwen-1.5-32b-hf/alpaca" TOKENIZER_PATH="./model_from_hf/Qwen1.5-32B/" CKPT_PATH="./ckpt/Qwen1.5-32B/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-not-use-fast \6.3 Lora Fine-Tuning The Lora fine-tuning script is configured by adding the following lora parameters based on the full-parameter finetune script:
CKPT_SAVE_DIR="./ckpt/Qwen1.5-32B-lora-tp8-pp1/" --lora-target-modules query_key_value dense proj dense_4h_to_h \ --lora-r 16 \ --lora-alpha 32 \
Performance
Machine performance
The performance of Qwen1.5-32B in Ascend NPU and Reference:
| Device | Model | throughput rate (tokens/s/p)(8k) |
|---|---|---|
| Reference | Qwen1.5-32B | 748.1 |
| Reference | Qwen1.5-32B | 708.3 |
Inference
Config qwen1.5-32b inference script:examples/qwen15/generate_qwen15_32b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Qwen1.5-32B-v0.1-tp8-pp1/"
TOKENIZER_PATH="/model_from_hf/Qwen1.5-32B/"
Launch qwen1.5-32b inference script: examples/qwen15/generate_qwen15_32b_ptd.sh
bash examples/qwen15/generate_qwen15_32b_ptd.sh
Some inference samples of Qwen1.5-32B are as follows:
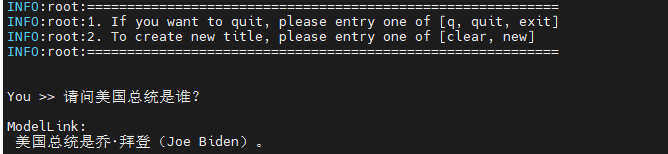
Config Qwen1.5-72B lora script: examples/qwen15/generate_qwen15_32b_lora_ptd.sh
# modify lora model directory path
CHECKPOINT_LORA="./ckpt/Qwen1.5-32B-lora-tp8-pp1/"
Launch Qwen1.5-32B inference
bash ./examples/qwen15/generate_qwen15_32b_lora_chat_ptd.sh
Some inference samples of Qwen1.5-32B after lora are as follows:

Evaluation
We use the MMLU benchmark to evaluate our model.
Config qwen1.5-32b evaluation script: examples/qwen15/evaluate_qwen15_32b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# Modify the model parameter path and vocabulary path
TOKENIZER_PATH="./model_from_hf/Qwen1.5-32B/" # vocabulary path
CHECKPOINT="./model_weights/Qwen1.5-32B-v0.1-tp8-pp1/" # parameter path
# Configure the task type and dataset path
DATA_PATH="./mmlu/data/test/" # "./ceval/val/" for ceval task
TASK="mmlu" # "ceval" for ceval task
Launch qwen1.5-32b evaluation
bash examples/qwen15/evaluate_qwen15_32b_ptd.sh
| Task | subset | Question | OpenSource | NPU |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 73.4 | 72.6 |
Qwen1.5-72B
Training-72b
| Hardware | Seq-length | Value |
|---|---|---|
| NPU | 8k | 64 x Ascend NPUs |
Script
-
Clone the repository to your local server:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt -
Build environment
# python3.8 conda create -n test python=3.8 conda activate test # install other packages pip install -r requirements.txt # install torch and torch_npu pip install torch-2.2.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.2.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl # modify ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # install MindSpeed git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip3 install -e . cd .. -
Prepare pretrained weights and tokenizer
Download the Qwen1.5-72B checkpoint from here
mkdir ./model_from_hf/Qwen1.5-72B/ cd ./model_from_hf/Qwen1.5-72B/ wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/config.json wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/generation_config.json wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/merges.txt wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model-00001-of-00038.safetensors wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model-00002-of-00038.safetensors wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model-00003-of-00038.safetensors wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model-00004-of-00038.safetensors wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model-00005-of-00038.safetensors ... wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/tokenizer.json wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/tokenizer_config.json wget https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/vocab.json cd ../../ -
weight conversion in ptd mode
4.1 Convert weights from huggingface format to megatron format (This scenario is generally used to train open-source HuggingFace models on Megatron)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # convert to ptd weights python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader llama2_hf \ --saver megatron \ --target-tensor-parallel-size 8 \ --target-pipeline-parallel-size 8 \ --num-layers-per-virtual-pipeline-stage 2 \ --params-dtype bf16 \ --load-dir ./model_from_hf/Qwen1.5-72B/ \ --save-dir ./model_weights/Qwen1.5-72B-v0.1-tp8-pp8-vpp2/ \ --tokenizer-model ./model_from_hf/Qwen1.5-72B/tokenizer.json \ --add-qkv-biasNote: The --num-layers-per-virtual-pipeline-stage parameter only works if --target-pipeline-parallel-size > 2, if target-pipeline-parallel-size does not satisfy the >2 condition, remove it from the script --num-layers-per-virtual-pipeline-stage parameter in the script.
4.2 Any Megatron weights with parallel slicing strategy --> Any Megatron weights with parallel slicing strategy (This scenario is generally used to convert the trained megatron model back to the HuggingFace format)
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh python tools/checkpoint/convert_ckpt.py \ --model-type GPT \ --loader megatron \ --saver megatron \ --save-model-type save_huggingface_llama \ --load-dir ./model_weights/Qwen1.5-72B-v0.1-tp8-pp8-vpp2/ \ --target-tensor-parallel-size 1 \ --target-pipeline-parallel-size 1 \ --num-layers-per-virtual-pipeline-stage 2 \ --add-qkv-bias \ --save-dir ./model_from_hf/Qwen1.5-72B/ # Fill in the original HF model path here, new weights will be saved in ./model_from_hf/Qwen-7B/mg2hg/Weight conversion is suitable for pre-training, fine-tuning, inference and evaluation. Adjust the parameters
target-tensor-parallel-sizeandtarget-pipeline-parallel-sizeaccording to different tasks. -
pre-training
5.1 Prepare dataset Download the Qwen1.5-72B datasets from here
# download datasets cd ./dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./dataset/Qwen-1.5-72B-hf/ python ./tools/preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-72B/ \ --output-prefix ./dataset/Qwen-1.5-72B-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF5.2 pre-training
# modify the script according to your own ascend-toolkit path source /usr/local/Ascend/ascend-toolkit/set_env.sh # modify config according to your own actual situation CKPT_SAVE_DIR="./ckpt/Qwen1.5-72B/" TOKENIZER_PATH="./model_from_hf/Qwen1.5-72B/" # tokenizer path DATA_PATH="./dataset/Qwen1.5-72B/alpaca_text_document" # processed dataset CKPT_LOAD_DIR="./model_weights/Qwen1.5-72B-v0.1-tp8-pp8-vpp2/"Launch Qwen1.5-72B pre-training script: examples/qwen15/pretrain_qwen15_72b_ptd.sh
bash examples/qwen15/pretrain_qwen15_72b_ptd.shNote:
- If using multi machine training, and no data sharing configuration on the mechines, it's necessary to add the parameter
--no-shared-storage. This parameter will determine whether non master nodes need to load data based on distributed parameters, and check the corresponding cache and generated data. - The --num-layers-per-virtual-pipeline-stage parameter only works if --target-pipeline-parallel-size > 2, if target-pipeline-parallel-size does not satisfy the >2 condition, remove it from the script --num-layers-per-virtual-pipeline-stage parameter in the script.
- If using multi machine training, and no data sharing configuration on the mechines, it's necessary to add the parameter
-
fine-tuning
6.1 Prepare fine-tuning dataset Download the Qwen1.5-72B datasets from here
# download datasets mkdir finetune_dataset cd ./finetune_dataset wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet cd .. # process datasets mkdir ./finetune_dataset/qwen-1.5-72b-hf/ python ./tools/preprocess_data.py \ --input ./dataset/ train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Qwen1.5-72B/ \ --output-prefix ./finetune_dataset/qwen-1.5-72b-hf/alpaca \ --workers 4 \ --log-interval 1000 \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralInstructionHandler \ --append-eod6.2 Full Parameters Fine-Tuning The configuration script for full parameters fine-tuning is basically the same as that for pretrain_qwen15_72b_ptd.sh.The difference is that the dataset and the training parameter is-instruction-dataset are added.
Add the fine-tuning parameter
--finetuneand add pretrained-weight load parameter--load, so that fine-tuning starts from the first step.DATA_PATH="./finetune_dataset/qwen-1.5-72b-hf/alpaca" TOKENIZER_PATH="./model_from_hf/Qwen1.5-72B/" CKPT_PATH="./ckpt/Qwen1.5-72B/" --load ${CKPT_PATH} \ --finetune \ --is-instruction-dataset \ --tokenizer-not-use-fast \6.3 Lora Fine-Tuning The Lora fine-tuning script is configured by adding the following lora parameters based on the full-parameter finetune script:
CKPT_SAVE_DIR="./ckpt/Qwen1.5-72B-lora-tp8-pp2/" --lora-target-modules query_key_value dense proj dense_4h_to_h \ --lora-r 16 \ --lora-alpha 32 \
Performance
Machine performance
The performance of Qwen1.5-72B in Ascend NPU and Reference:
| Device | Model | throughput rate (tokens/s/p)(8k) |
|---|---|---|
| Reference | Qwen1.5-72B | 301.4 |
| Reference | Qwen1.5-72B | 317.3 |
Inference
Config qwen1.5-72b inference script:examples/qwen15/generate_qwen15_72b_chat_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# modify script model path and tokenizer path
CHECKPOINT="./model_weights/Qwen1.5-72B-v0.1-tp8-pp1/"
TOKENIZER_PATH="/model_from_hf/Qwen1.5-72B/"
Launch qwen1.5-72b inference script: examples/qwen15/generate_qwen15_72b_ptd.sh
bash examples/qwen15/generate_qwen15_72b_ptd.sh
Some inference samples of Qwen1.5-72B are as follows:
Config Qwen1.5-72B lora script: examples/qwen15/generate_qwen15_72b_lora_ptd.sh
# modify lora model directory path
CHECKPOINT_LORA="./ckpt/Qwen1.5-72B-lora-tp8-pp2/"
Launch Qwen1.5-72B inference
bash ./examples/qwen15/generate_qwen15_72b_lora_chat_ptd.sh
Some inference samples of Qwen1.5-72B after lora are as follows:

Evaluation
We use the MMLU benchmark to evaluate our model.
Config qwen1.5-72b evaluation script: examples/qwen15/evaluate_qwen15_72b_ptd.sh
# ascend-toolkit path
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# Modify the model parameter path and vocabulary path
TOKENIZER_PATH="./model_from_hf/Qwen1.5-72B/" # vocabulary path
CHECKPOINT="./model_weights/Qwen1.5-72B-v0.1-tp8-pp1/" # parameter path
# Configure the task type and dataset path
DATA_PATH="./mmlu/data/test/" # "./ceval/val/" for ceval task
TASK="mmlu" # "ceval" for ceval task
Launch qwen1.5-72b evaluation
bash examples/qwen15/evaluate_qwen15_72b_ptd.sh
| Task | subset | Question | OpenSource | NPU |
|---|---|---|---|---|
| MMLU | 57 | 14042 | 77.5 | 77.5 |