32 KiB
AscendSpeed
AscendSpeed provides end-to-end solution for large language models training on Ascend chips, including pretrained models, parallel algorithms, fused kernels, and downstream tasks. The repository is jointly contributed by Ascend Computing Product Unit, Algorithm Unit, Research Unit, and OCK of Huawei Corporation.
Why AscendSpeed?
Pretrained Models
Currently, the pre-training of the following models has been supported:
Baichuan-13B, LLaMA-33B, LLaMA2-13B/70B, Aquila-7B are coming soon ...
Acceleration Features
Currently, the following acceleration features for LLMs have been supported:
- Tensor parallelism
- Pipeline parallelism
- Virtual pipeline parallelism
- Optimized pipeline parallelism
- Fold-3D
- Recomputation
- Selective recomputation
- Sequence parallelism
- ZeRO-1/2/3
- Inverted triangle acceleration
- Numerous fused kernels and optimizers for LLMs
- Merged feed-forward network
- Gradient accumulation
More novel and useful features are developing for LLMs training on Ascend ...
Downstream Tasks
Currently, the following downstream tasks have been supported:
- Inference with sampling and greedy search strategies
- Dataset processing with prompt or instruction
- Efficient-parameter fine-tuning with lora from peft
- Evaluation with numerous popular and academic benchmarks
The plan for more tasks, like RLHF and RM, is under way ...
Quick Start For Pretraining
Model Performance
| Model | Size | Servers | Main Acceleration Features | Mode | Flash Attention | NPU Throughput | Reference Throughput | Training Log | Reference Log | Loss Compare |
|---|---|---|---|---|---|---|---|---|---|---|
| Baichaun | 7B | 313T 1x8 | ZeRO2 + Selective recomputation + Inverted triangle | FP16 | False | -- | -- | -- | -- | -- |
| Bloom | 7B1 | 376T 1x8 | TP8 + SP + Recomputation | FP16 | False | -- | -- | -- | -- | -- |
| 176B | 376T 12x8 | PP12 + TP8 + SP + Recomputation | FP16 | False | -- | -- | -- | -- | -- | |
| BF16 | False | -- | -- | -- | -- | -- | ||||
| InternLM | 7B | 376T 1x8 | ZeRO2 + Recomputation + Inverted triangle | FP16 | False | -- | -- | -- | -- | -- |
| LLaMA | 7B | 376T 1x8 | ZeRO2 + Recomputation | FP16 | False | -- | -- | -- | -- | -- |
| 13B | 376T 1x8 | ZeRO2 + Recomputation | FP16 | False | -- | -- | -- | -- | -- | |
| 65B | 376T 4x8 | PP4 + TP8 + SP + Recomputation | FP16 | False | -- | -- | -- | -- | -- | |
| BF16 | False | 234 tokens/p/s | 260 tokens/p/s | -- | -- | Loss | ||||
| LLaMA2 | 7B | 376T 1x8 | PP4 + TP2 | FP16 | False | -- | -- | -- | -- | -- |
{kind=link}
Model Training
- Clone the repository to your local server:
git clone https://gitee.com/ascend/AscendSpeed.git
cd AscendSpeed
mkdir logs
mkdir ckpt
- Build environment
# python3.7
conda create -n test python=3.7
conda activate test
# install torch and torch_npu
pip install torch==1.11 -i https://pypi.tuna.tsinghua.edu.cn/simple
wget https://gitee.com/ascend/pytorch/releases/download/v5.0.rc2-pytorch1.11.0/torch_npu-1.11.0.post1-cp37-cp37m-linux_aarch64.whl (ARM)
or wget https://gitee.com/ascend/pytorch/releases/download/v5.0.rc2-pytorch1.11.0/torch_npu-1.11.0.post1-cp37-cp37m-linux_x86_64.whl (X86)
pip install torch_npu-1.11.0.post1-cp37-cp37m-linux_XXXXXX.whl
# install deepspeed and deepspeed_npu
pip install deepspeed==0.9.2
git clone https://gitee.com/ascend/DeepSpeed.git -b v0.9.2 deepspeed_npu
cd deepspeed_npu
pip3 install -e ./
# install other packages
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- Prepare dataset:
# for llama, download alpaca dataset, like
wget http://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
# download tokenizer configs and (selective) weights from
# https://huggingface.co/decapoda-research/llama-7b-hf/tree/main
# revise "LLaMATokenizer" as "LlamaTokenizer" in tokenizer_config.json (This is a bug of huggingface)
mkdir dataset
python tools/preprocess_data.py --input alpaca_data.json \
--output-prefix dataset/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
# for bloom
cd AscendSpeed
wget https://huggingface.co/bigscience/misc-test-data/resolve/main/stas/oscar-1GB.jsonl.xz
xz -d oscar-1GB.jsonl.xz
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-vocab.json
wget https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-merges.txt
python tools/preprocess_data.py --input ./oscar-1GB.jsonl \
--output-prefix my-gpt2 \
--vocab ./gpt2-vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file .//gpt2-merges.txt \
--append-eod \
--workes 9
mkdir -p dataset/oscar_data_1g
mv gpt2-vocab.json gpt2-merges.txt my-gpt2_text_* dataset/oscar_data_1g/
mkdir -p dataset/bloom_vocab/vocab_file
# download data to vocab_file by yourself from
# https://huggingface.co/bigscience-catalogue-data-dev/byte-level-bpe-tokenizer-no-norm-250k-whitespace-and-eos-regex-alpha-v3-dedup-lines-articles/tree/main
- (Selective) Prepare pretrained weights
python tools/ckpt_convert/llama/convert_weights_from_huggingface.py --input-model-dir ../llama-7b-hf \
--output-model-dir ckpt \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
--type 7B
# if you want to change the parallel strategy, the pretrained weights should also be sharded
# please refer to tools/ckpt_convert/examples/llama_convert_weights_when_tp_pp_change.sh
- Start your task
# set your data path / weight path / tokenizer path etc.
sh examples/llama/pretrain_llama_7B_zero_8B.sh
sh examples/bloom/pretrain_bloom_7b1.sh
Introduction For Acceleration Features
Tensor Parallelism
Tensor parallelism (TP) is a kind of model parallelism strategy, which splits execution of a single transformer module over multiple devices. The basic principle of PP is:
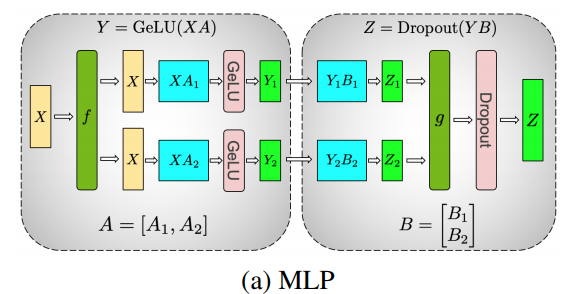
--tensor-model-parallel-size flag to specify the number of GPUs among which to split the model.
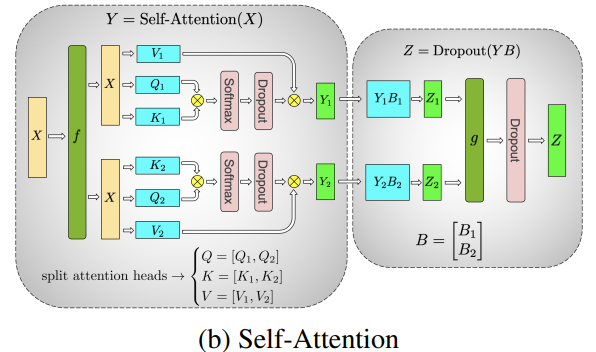
(Virtual & Optimized) Pipeline Parallelism
Pipeline parallelism (PP) is a kind of model parallelism strategy, which shards the transformer modules into stages with an equal number of transformer modules on each stage and then pipelines execution by breaking the batch into smaller microbatches. Virtual pipeline (VP) parallelism optimizes PP by add virtual stages to reduce pipeline bubble time. Optimized Pipline Parallelism (OPP) is an enhanced version of VP, which further reduces the bubble time by reasonably setting the size of each microbatch. The basic principle of PP and VP is:
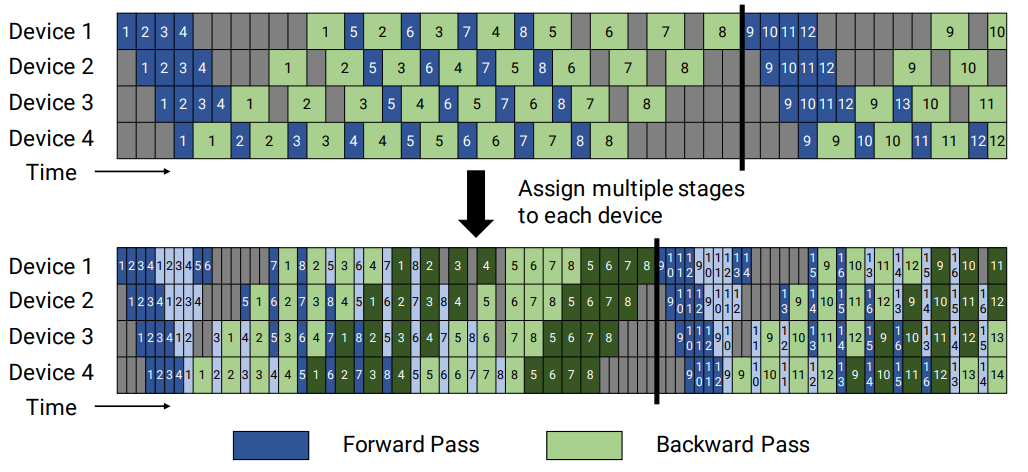
To enable pipeline model parallelism, use the --pipeline-model-parallel-size flag to specify the number of stages to split the model into (e.g., splitting a model with 24 transformer layers across 4 stages would mean each stage gets 6 transformer layers each).
To enable virtual pipeline parallelism, additionally use --num-layers-per-virtual-pipeline-stage flag to decide number of layers per virtual stage.
To enable optimized pipeline parallelism, additionally use --optimized-pipeline and --manual-mbs example-config-1 flag based on PP. Note that both VP and OPP reduce bubble time, but increase communication time.
Fold3D
Fold3D hides the commutation time of data parallelism in VP. The basic principle of Fold3D is:
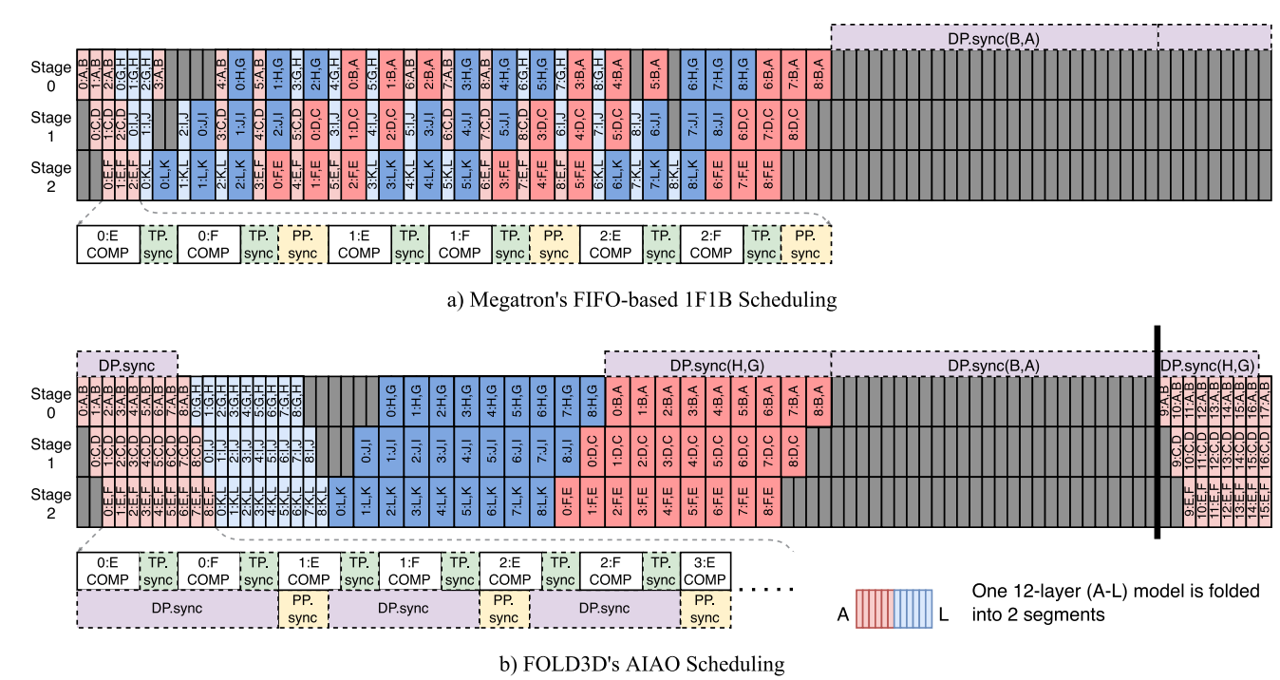
--fold-mode "aiao" flag to choose strategy.
(Selective) Recomputation
To reduce NPU memory usage so deploy a large model to a training system, we support activation checkpointing and recomputation.
We support two levels of recompute granularity: full and selective. To enable full recomputation, please use --checkpoint-activations flag, and to enable selective recomputation, please use --checkpoint-policy flag to
decide the strategy of selective recomputation. Note that the selective strategy is customized and optimized for Ascend chips.
Sequence Parallelism
Sequence parallelism (SP) is a kind of model parallelism strategy, which splits the sequence axis in dropout and layernorm layers. SP depends on TP in our implementation. The allreduce operation in TP is split to reduce-scatter and allgather by SP, which reduces the memory occupation in model training. The basic principle of SP is:
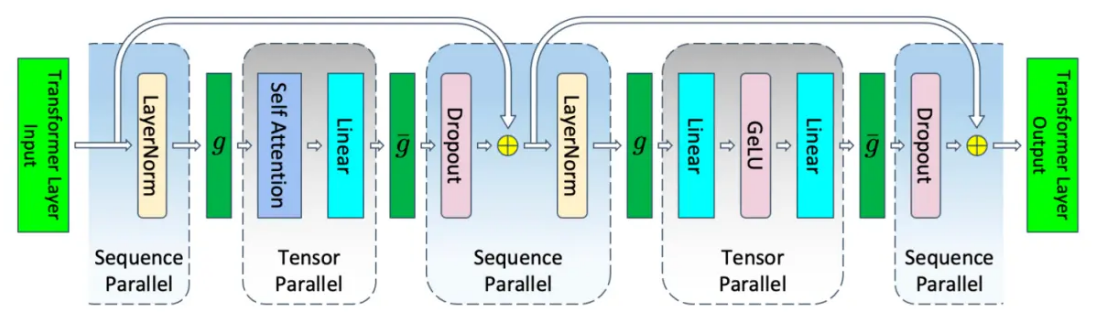
--tensor-model-parallel-size flag should be lager than 1, and set --sequence-parallel flag.
ZeRO-1/2/3
Zero Redundancy Optimizer (ZeRO) is a kind of memory-optimization strategy in data parallelism proposed by MicroSoft. AscendSpeed supports ZeRO-1/2/3 by adding a deepspeed branch. The basic principle of ZeRO is:
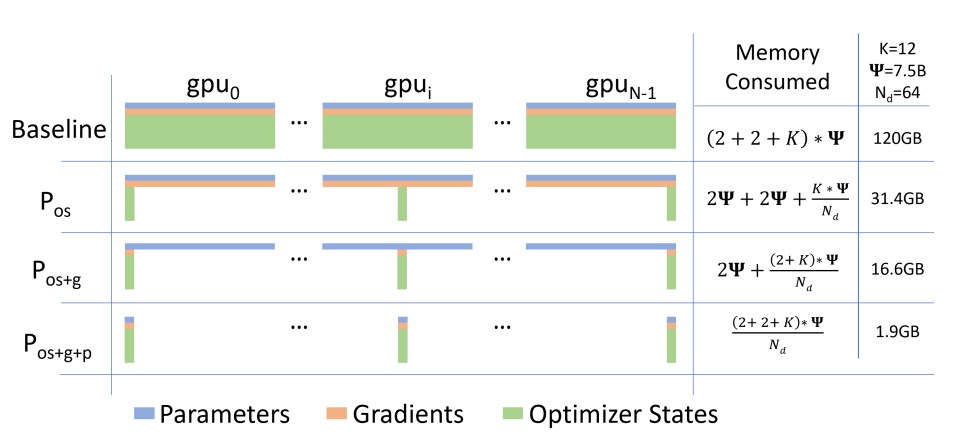
--use-distributed-optimizer flag.
Inverted Triangle Acceleration
Inverted triangle acceleration is an acceleration module for attention calculation, which implements flash attention with python. Basically, the calculation of self-attention takes all of the attention mask into consideration. For this scenario, inverted triangle attention acceleration algorithm is used to avoid blocks that do not need to be calculated in the upper triangle position in the attention mask, thereby reducing the amount of calculation. The calculation process is:
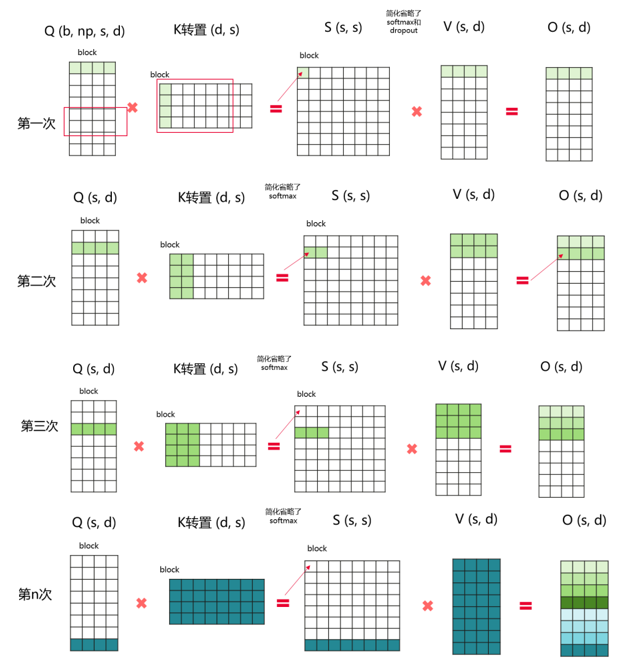
--triangle-attn flag.
Fused Kernels & Optimizer
For LLMs, Ascend chips support various fused kernels, such as scaled_masked_softmax and rotary_pos_emb. The related examples can be found by searching in this project, and more detailed information is coming soon.
For fused optimizer, two kinds of fused adam optimizers are provided by --optimizer. Specifically, the choice --optimizer adam saves more memory, and the choice --optimizer fused_adam trains faster.
Merged Feed-Forward Network & Gradient Accumulation
For llama and other LLMs without bias in FFN, the linear transformation in FFN could be merged to save communication in tensor parallelism. To enable this feature, please set --mlp-layer-fusion flag. Gradient accumulation uses gradient of N rounds to make an optimizer step and update parameters. Here, N = global batchsize / micro batchsize / DP, and DP = device nums / tp / pp.
Downstream Tasks
Inference with Pretrained Weights
This pattern means that we want you to be able to easily load models and talk to the model (Mostly similar to huggingface inference API). All you needed is to enter a piece of text into the model to get the results in text form. In addition, you don't have to worry about models being too big in inference, we support a variety of common parallel strategies. Currently, we support the following three inference modes in different parallel strategies:
- PTD only
- Deepspeed ZeRO only
- Deepspeed ZeRO in Pipe with TP
Usage Guide
Follow these steps to write your own inference code: 1. Initializing the Distributed Environment
initialize_megatron(args_defaults={'no_load_rng': True, 'no_load_optim': True})
2. Initializing model and loading weights
from ascendspeed import get_args
from ascendspeed.model import LlamaModel
from ascendspeed.arguments import core_transformer_config_from_args
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
config = core_transformer_config_from_args(get_args())
init_model = LlamaModel(
config,
parallel_output=False,
add_pooler=False,
pre_process=pre_process,
post_process=post_process
)
return init_model
model = LlamaModel.from_pretrained(
model_provider=model_provider,
pretrained_model_name_or_path="your model weight path"
)
"""
This is an API for initializing model and loading weight.
Parameters:
----------
model_provider(`func`):
Function used to generate model objects which is similar to the training define.
pretrained_model_name_or_path(`str`, *optional*, defaults to None):
File path of Model weight in megatron format (TP, PP may be used).
If it is None, the random initialized weights will be used.
"""
3. Generate text in HuggingFace-like ways
model.generate(
input_ids="hello",
do_sample=True,
top_k=50,
top_p=1.0,
temperature=1.0,
max_length=256,
max_new_tokens=64,
stream=True,
)
Quick start
Here are three example scripts in different mode mentioned above for you to launch directly. Note that if you want to use the weight from huggingface, please run the weight conversion script first. The following uses llama-7b model as an example.
python tools/ckpt_convert/llama/convert_weights_from_huggingface.py --input-model-dir llama-7b-hf \
--output-model-dir llama-7b-tp2-pp2 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
--type 7B
- PTD only In this mode, the model will be split by using pipeline parallel and tensor parallel mode in megatron ways.
sh examples/llama/generate_llama_7B_tp2_pp2.sh
- Deepspeed ZeRO only In this mode, the model will uses DeepSpeed ZeRO 1, 2 or 3 definition with tp=1, pp=1.
sh examples/llama/generate_alpaca_13B_deepspeed.sh
- Deepspeed ZeRO in Pipe with TP In this mode, the model will uses pipe model definition in DeepSpeed ZeRO 1, 2 or 3 with tp>1, pp=1.
sh examples/llama/generate_llama_7B_deepspeed_pipeline.sh
- If you want to use lora model, for details, see:
sh examples/llama/generate_alpaca_13B_lora_deepspeed.sh
An example with Chinese-LLaMA-Alpaca weights is as below:
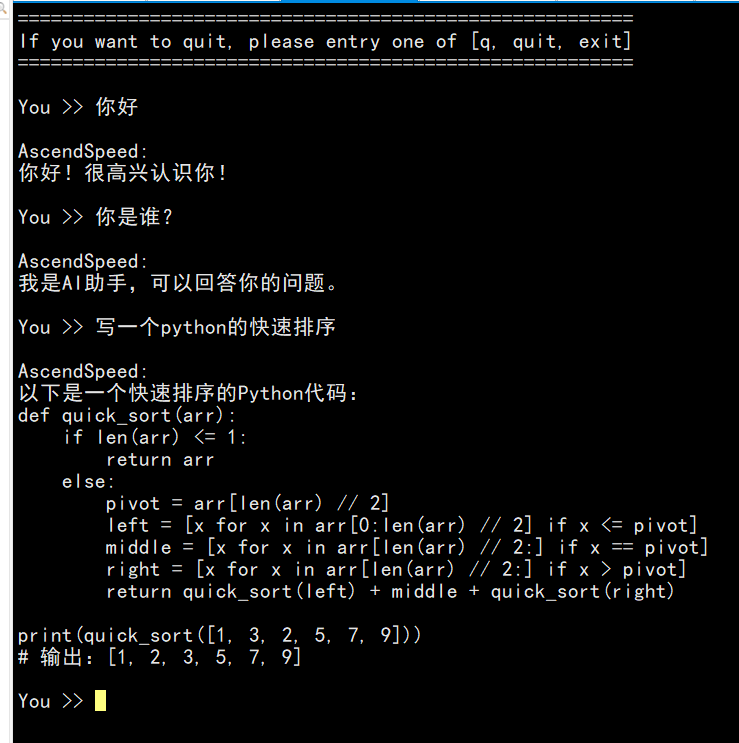
Dataset Processing
Quick Start
# for llama, download alpaca dataset, like
wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# download tokenizer configs and (selective) weights from
# https://huggingface.co/decapoda-research/llama-7b-hf/tree/main
# revise "LLaMATokenizer" as "LlamaTokenizer" in tokenizer_config.json (This is a bug of huggingface)
mkdir dataset
python tools/preprocess_data.py --input train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix dataset/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
Preprocessing pretraining dataset
wikipedia dataset
- download wikipedia data from huggingface to WORKSPACE/wikipedia
- download llama tokenizer model and config from huggingface to WORKSPACE/llama-7b-hf
- use preprocessing script to preprocess wikipedia data
# We assume that data and tokenizer has already been downloaded to WORKSPACE.
cd WORKSPACE
mkdir wikipedia_preprocessed
# specify huggingface load_dataset parameters.(--input param will be ignored)
# these params will just be feed into datasets.load_dataset function
hf_config_json="./hf_config_json.json"
cat <<EOT > $hf_config_json
{
"path": "WORKSPACE/wikipedia",
"name": "20220301.en",
"streaming: True,
"split": "train"
}
EOT
python tools/preprocess_data.py \
--input "WORKSPACE/wikipedia" \
--hf-datasets-params ${hf_config_json} \
--output-prefix WORKSPACE/wikipedia_preprocessed/wikipedia \
--dataset-impl mmap \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--streaming \
--workers 8
After preprocessing, there will be a wikipedia_text_document.bin and a wikipedia_text_document.idx in the WORKSPACE/wikipedia_preprocessed dictionary.
Then, We can train a model with --data-path WORKSPACE/wikipedia_preprocessed/wikipedia_text_document flag.
Note that datasets in huggingface have a format like this.
The name of the text field of the dataset can be changed by using the --json-key flag which default is text.
In wikipedia dataset, it has four columns which are id, url, title and text.
Then we can specify --json-key flag to choose a column used to train.
alpaca for pretraining
Besides, we can also use alpaca dataset to pretrain like below.
Download dataset form alpaca which has a text column.
python tools/preprocess_data.py --input WORKSPACE/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--json-key text
Preprocessing alpaca instruction dataset
# for llama, download alpaca dataset, like
# wget https://huggingface.co/datasets/tatsu-lab/alpaca/resolve/main/data/train-00000-of-00001-a09b74b3ef9c3b56.parquet
# download tokenizer configs and (selective) weights from
# https://huggingface.co/decapoda-research/llama-7b-hf/tree/main
# revise "LLaMATokenizer" as "LlamaTokenizer" in tokenizer_config.json (This is a bug of huggingface)
cd WORKSPACE
mkdir alpaca_preprocessed
python tools/preprocess_data.py --input WORKSPACE/alpaca/train-00000-of-00001-a09b74b3ef9c3b56.parquet \
--output-prefix WORKSPACE/alpaca_preprocessed/alpaca \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path WORKSPACE/llama-7b-hf \
--tokenizer-not-use-fast \
--handler-name GeneralInstructionHandler
After preprocessing, there will be three bin files and three idx files in the WORKSPACE/alpaca_preprocessed dictionary.
Then, We can train a model with --data-path WORKSPACE/alpaca_preprocessed/alpaca and --is-instruction-dataset flags.
Note that instruction dataset has a --handler-name GeneralInstructionHandler flag which will choose GeneralInstructionHandler class to create prompt in ascendspeed/data/data_handler.py.
If you have an alpaca-style dataset which have instruction, input and output columns, just use GeneralInstructionHandler.
In addition, BelleMultiTurnInstructionHandler is used to handle belle dataset,
MOSSInstructionHandler is used to handle MOSS dataset and LeetcodePythonInstructionHandler is used to handle Leetcode dataset.
Finetune with Lora
Lora
Now, we support Lora to fine-tune your models. You just need to add this argument in your script to open Lora:
# Llama example
--lora-target-modules query_key_value dense gate_proj up_proj down_proj \
There are other Lora related arguments here, you can find their definitions in the PEFT library.
# Llama example
--lora-r 64 \
--lora-alpha 128 \
--lora-modules-to-save word_embeddings lm_head.lm_head \
--lora-register-forward-hook word_embeddings input_layernorm \
Among them, the argument --lora-register-forward-hook is used to repair the gradient chain break caused by PP. It only needs to be set to the input layer of each PP stage, and the repair will not increase the trainable parameters.
Finally, only Lora's parameters are saved after turning on Lora. Similarly, when loading a model, you need to specify the original model weight path and the Lora weight path. Parameters such as the optimizer are subject to those in the Lora weight path.
--load ${ORIGIN_CHECKPOINT} \
--lora-load ${LORA_CHECKPOINT} \
There is an example could be referred.
After using Lora to fine-tune the Llama model, the instruction dialogue effect is as follows:
You >> Give three tips for staying healthy.
AscendSpeed:
- Start exercising regularly and eat healthy food.
- Get a good eight hours of sleep each night.
- Take medications regularly.
Evaluation with Benchmarks
Quick Start
# Configure model path and vocab_file path
# Vocab file can be downloaded from https://huggingface.co/decapoda-research/llama-7b-hf
CHECKPOINT=../models/llama-7b-tp2-pp4/
VOCAB_FILE=../models/llama7b-hf/
# configure task and data path
DATA_PATH="dataset/boolq/test"
TASK="boolq"
# configure generation parameters
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT[images](sources%2Fimages)} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
# start evaluation
bash tasks/evaluation/eval.sh
Configuration of models and datasets
We should firstly configure the model path at CHECKPOINT and the vocabulary path at VOCAB_FILE. As the example shown below, we want to use llama7b model for BoolQ dataset evaluation, so the model path and vocab file should correspond to llama7b model.
Model can be segmented with suitable segmentation parameters: the following example set tensor-model-parallel-size(tp) = 2 and pipeline-model-parallel-size(pp) = 4. Segmentation example shows as followed:
python convert_weights_from_huggingface.py \
--input-model-dir /home/w425040/models/llama-7b-hf \
--output-model-dir /home/w425040/models/llama-7b-tp2-pp4 \
--type 7B \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4
Then, configure datasets paths and tasks. Note: since the evaluation parameters of different datasets are not totally same, it is not recommended to evaluate two or more different datasets together. Evaluation parameters such as --seq-length, --max-new-tokens and --max-position-embeddings need to be adjusted according to different datasets. The recommended parameters for each dataset will be given in the following instruction.
# configure model path and vocab_file path
CHECKPOINT=../models/llama-7b-tp2-pp4/
VOCAB_FILE=../models/llama7b-hf/
# configure task and data path
DATA_PATH="dataset/boolq/test"
TASK="boolq"
# configure generation parameters
Configuration of evaluation parameters for different datasets
The most important evaluation parameters must be --max-new-tokens, which means the output length of model generation. For example, multiple-choice
questions' output length is obviously shorter than coding tasks. Besides, this parameter largely influences the speed of model generation.
python -m torch.distributed.launch $DISTRIBUTED_ARGS evaluation.py \
--task-data-path $DATA_PATH \
--task $TASK\
--seq-length 512 \
--max-new-tokens 1 \
--max-position-embeddings 512 \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 32 \
--hidden-size 4096 \
--ffn-hidden-size 11008 \
--load ${CHECKPOINT} \
--num-attention-heads 32 \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path $VOCAB_FILE \
--tokenizer-not-use-fast \
--fp16 \
--micro-batch-size 1 \
--seed 42 | tee logs/train.log
Evaluation results and parameter configuration of BoolQ
The evaluation of the BoolQ data set is relatively simple, just configure TASK="boolq", --seq-length=512, --max-position-embeddings=512, --max-new-token=2.
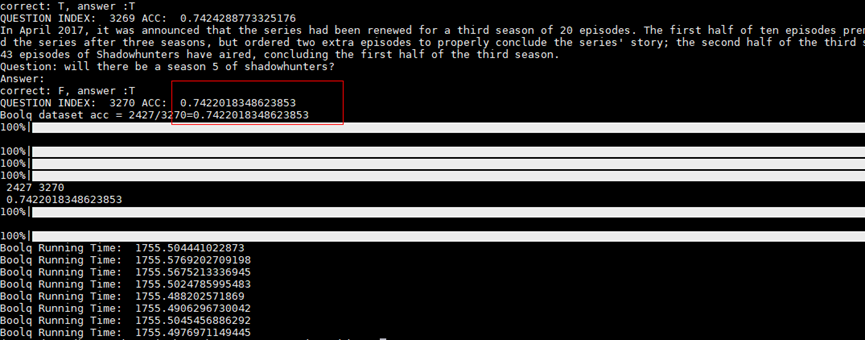
For LLama7B, the evaluation result of AscendSpeed on NPU environment is 0.742. For comparison, the score in the paper LLaMA: Open and Efficient Foundation Language Models is 0.765. The zero-shot results usually affected by the given prompt, and a higher score can be obtained by a suitable prompt.
The prompt can be modified in tasks/evaluation/evaluation.py
# Update new prompt by changing the template
template = {instruction}
Evaluation results and parameter configuration of MMLU
Since MMLU is a multidisciplinary task and 5 shots are performed, the length of each subject question varies greatly. If you want to run 57 subjects at the same time, you need to set TASK="mmlu", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=2. (--max-new-tokens can be set to between 2-4).
On many websites, the accuracy of the MMLU is evaluated according to disciplines. The 57 categories of single subjects belong to four main categories. Therefore, the statistics should be summarized according to the major categories of the subjects. The following website gives the major categories of subjects for 57 categories of subjects.
(https://github.com/hendrycks/test/blob/master/categories.py)
Compared to the benchmark accuracy 35.1 from the paper LLaMA: Open and Efficient Foundation Language Models shows above, the evaluation result of AscendSpeed on NPU environment is 0.332. As a result, the total accuracy difference is less than 0.02, so do the four main subjects.
| MMLU Result 5 shots | STEM | Social Science | Other | Humanities | Total | Total of paper |
|---|---|---|---|---|---|---|
| AscendSpeed + NPU | 29.8 | 33.0 | 32.5 | 37.7 | 33.3 | 35.1 |
Evaluation results and parameter configuration of GSM8K
GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers. The answer of each question is a specific number. Since few shots are performed, the question length is relatively long in GSM8K, and the output answer contains a chain of thoughts, it is necessary to configure TASK="gsm8k", --seq-length=2048, --max-position-embeddings=2048, --max-new-token=128. (--max-new-tokens can be set between 256-512).
As the benchmark shows on OpenCompass, LLama7B model's evaluation gets only 10 points with pass@k(Generate k
times and choose the best answer). The results of AscendSpeed on NPU environment varies between 8 and 10 points according to the number of shots we use.