| 类型 | 功能 | 例子 |
| encoder | 将输入编码为具有具有表示能力的向量 | embedding, RNN, CNN, transformer |
| decoder | 将具有某种表示意义的向量解码为需要的输出形式 | MLP, CRF |
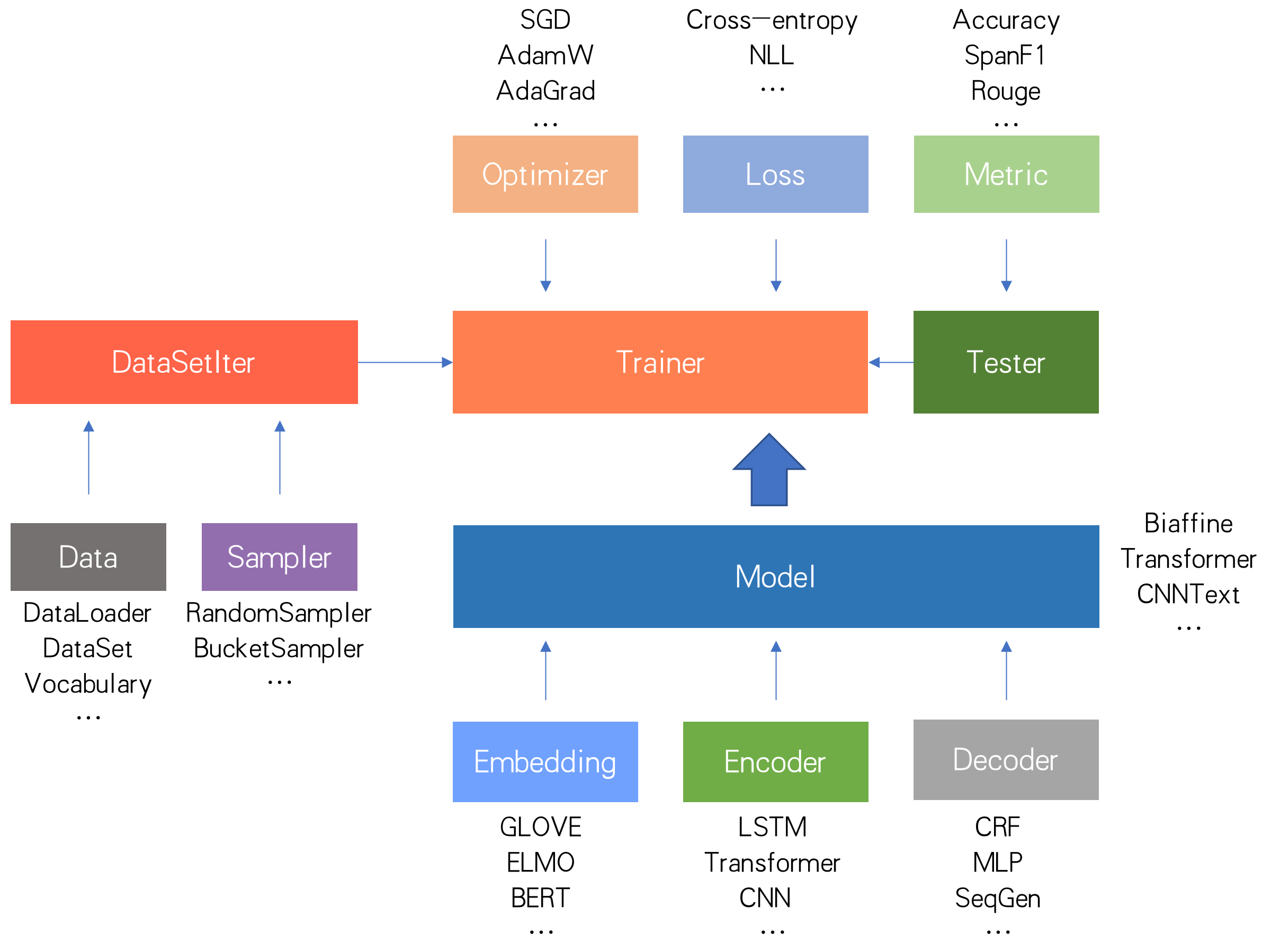 fastNLP的大致工作流程如上图所示,而项目结构如下:
fastNLP的大致工作流程如上图所示,而项目结构如下:
| fastNLP | 开源的自然语言处理库 |
| fastNLP.core | 实现了核心功能,包括数据处理组件、训练器、测试器等 |
| fastNLP.models | 实现了一些完整的神经网络模型 |
| fastNLP.modules | 实现了用于搭建神经网络模型的诸多组件 |
| fastNLP.embeddings | 实现了将序列index转为向量序列的功能,包括读取预训练embedding等 |
| fastNLP.io | 实现了读写功能,包括数据读入与预处理,模型读写,自动下载等 |