| .workflow | ||
| config | ||
| contrib | ||
| doc | ||
| hbr | ||
| hbr-raw | ||
| initdata | ||
| licenses | ||
| src | ||
| aclocal.m4 | ||
| configure | ||
| configure.ac | ||
| COPYRIGHT | ||
| GNUmakefile.in | ||
| HISTORY | ||
| INSTALL | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
He3DB是什么?
He3DB是移动云开源的云原生数据库产品。
He3DB受Aurora论文启发,基于开源数据库PostgreSQL 改造的云原生数据库产品。架构上实现计算存储分离,主备节点共享一份数据(容量上限100T ),支持一主15备,RTO 绝对时间<30秒,我们打造的核心理念:高性能,低成本。
为什么叫He3DB?
He3 是氦元素同位素,是一种核聚变燃料,具有清洁、安全、高效等特点。和我们He3DB 追求的目标不谋而合。
产品定位:
云上一般小型业务比较看重低成本,更偏向于使用RDS数据库服务。而中大型业务对性能或者可用性要求更高,而不得不选择云原生数据库。当前各大云厂商的云原生数据库从产品力的角度看已经大幅领先RDS,但是市场占有率RDS依然占据大头,最重要的原因就是RDS成本优势。我们团队认为RDS成本和云原生数据库产品力之间存在一个权衡,而正是这种权衡,让我们决定研发He3DB,我们对He3DB的定位既能向下占据部分RDS市场,又能向上承接部分云原生数据库业务。
He3DB不会一味的追求更大,更快,更强,而是会设置一个产品力上限,而这个上限能够满足移动云绝大多数用户使用场景,在这个前提下,我们会把降低成本作为He3DB持续追求的目标。
架构:
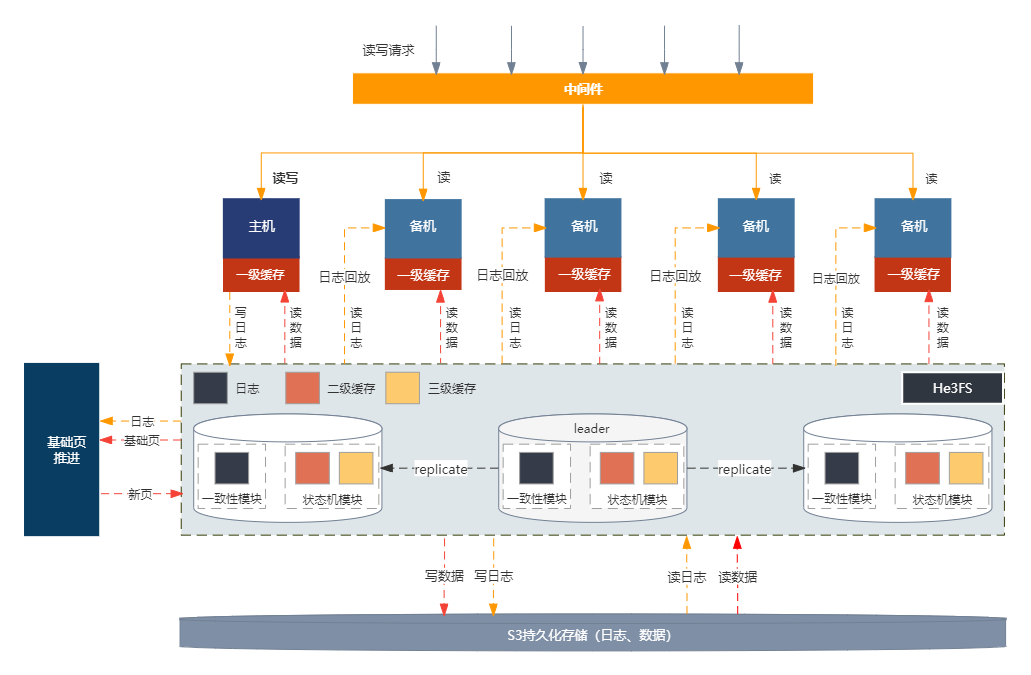
He3DB架构分4层: 代理层, 计算层, 高性能存储层, 低性能持久层
中间件:用户通过中间件请求数据库服务,中间件支持PG协议,100%兼容PG SQL。中间最核心的能力就是选择合适的备机节点,保证读写数据的一致性以及备节点负载均衡,未来中间件能够自动感知业务负载,动态扩缩容备节点,保证服务的持续稳定。
计算引擎 :基于Postgresql 源码改造,架构上实现了计算存储分离,主备共享数据。部分模块也做了相关优化:实现Aurora论文中提到的log is database,以及为了RTO时间绝对可控,实现wal 日志的delay replay
存储引擎:实现冷热分层:高性能存储层,以及冷数据持久层。
He3DB 目标实现思路:
高性能
目标:读QPS >100W 写TPS >10W
关健技术:
- 降低计算层往存储层写的数据量,从而提升写TPS性能。主要删除计算层往数据层写数据页(只写wal日志)以及关闭wal日志为了解决部分写而要写整个数据页的机制. 初步评估,相比PG 本身,写数据量能下降2/3左右
- 缩短RTO时间。 通过备机的wal delay replay技术(只回放内存中存在数据页的WAL日志),把回放操作由磁盘IO优化为内存IO.从而最大化的降低RTO时间
- 实现智能化中间件,保证读强一致性(通过记录主备wal replay点实现),最终能够通过增加备机,增加读吞吐能力。
- 数据冷热分层,我们能够定义每个备节点缓存不同的热数据,通过中间件,保证每一个读请求选择最佳缓存备节点,极端情况下,我们能够保证所有的读请求全部内存命中(需要修改buffer缓存算法,由空间考虑优化为缓存热数据)
低成本:
- 计算引擎:提供serverless服务,按需扩缩量,保证计算资源的效能最大化,未来考虑进一步拆分CPU和内存资源,能够更精准管控计算资源
- 存储引擎:业务数据根据使用场景标识温度数,架构上实现冷热数据分层以及支持多种压缩算法。最终目标是保证性能前提下,最大化降低存储成本
高可用,高可靠:
- 实时备份:备份过程对业务零影响(备份进程独立于计算节点直接操作S3对象存储)
- 高性能存储层通过Raft算法保证高可用
- 冷数据持久层基于S3对象存储实现(S3由云服务商保证数据高可用以及高可靠)
扩展性:以下每一层都可以独立基于业务需求完成扩缩容
- 计算引擎可以通过增加备机,线性增加读吞吐能力
- 高性能存储层,可以通过增加follower节点或者learner节点增加读吞吐能力
- s3可以增加节点,增加吞吐以及容量
产品现状:
当前开源版本为0.6版本,还无法用于生产,这个版本主要验证计算存储分离,以及共享架构的正确性,性能不是我们关心的重点。0.6版本重点是计算引擎以及中间件,存储部分使用的开源juicefs作为共享存储层(做了部分模块的改造,后续会有相关源码分享)。下半年重点开发模块就是高性能存储层,也就是性能将作为最重要的目标。
为什么从0.6版本开始开源,而不是等到年底所有模块开发完成,几方面原因:
- He3DB年初立项就非常明确会完全以开源的方式运作,我们希望在项目早期就能够吸引开发者进来参与开发以及功能讨论。之所以等到8月份才开源第一个版本0.6,是因为前期需要做大量的论文研读,多种可行性方案验证以及基础框架的开发。
- 我们希望借助社区的力量,推动整个项目的发展。我们团队也会陆续推进一系列内核分析文章以及视频帮助开发者能够尽快参与到内核开发
- 我们团队希望尽早能够以完全开源的方式推动项目向前发展,包含后续需求的确认,模块管理,问题沟通的方式,项目月报等。我们希望社区能够看到He3DB的快速发展,相信我们团队的能力
部署:
Roadmap
短期
- 研发高性能存储(重点优化性能) 9-10月
- 支持冷热分层以及数据压缩(重点降低成本) 10-11月
- 高可靠,高可用:包含cluster管理,主备切换,网络异常处理等 10-12月
中长期
- 多模支持(gis,时序)
- 去O(主要是SQL兼容性以及生态工具开发)
- HTAP 能力(多主,算子下推,共享内存)
Slack:https://join.slack.com/t/dbspecialzone/shared_invite/zt-1fe4g7uf4-iC_rdhnWpQkP0oQl_GUSKQ