34 KiB
Milvus Developer Guides
by Rentong Guo, Sep 15, 2020
1. System Overview
In this section, we sketch the system design of Milvus , including data model, data organization, architecture, and state synchronization.
1.1 Data Model
Milvus exposes the following set of data features to applications:
-
a data model based on schematized relational tables, in that rows must have primary-keys,
-
a query language specifies data definition, data manipulation, and data query, where data definition includes create, drop, and data manipulation includes insert, upsert, delete, and data query falls into three types, primary key search, approximate nearest neighbor search (ANNS), ANNS with predicates.
The requests' execution order is strictly in accordance with their issue-time order. We take proxy's issue time as a requst's issue time. For a batch request, all its sub-requests share a same issue time. In cases there are multiple proxies, issue time from different proxies are regarded as coming from a central clock.
Transaction is currently not supported by Milvus. Only batch requests such as batch insert/delete/query are supported. A batch insert/delete is guaranteed to become visible atomically.
1.2 Data Organization

In Milvus, 'collection' refers to the concept of table. A collection can be optionally divided into several 'partitions'. Both collection and partition are the basic execution scopes of queries. When use parition, users should clearly know how a collection should be partitioned. In most cases, parition leads to more flexible data management and more efficient quering. For a partitioned collection, queries can be executed both on the collection or a set of specified partitions.
Each collection or parition contains a set of 'segment groups'. Segment group is the basic unit of data-to-node mapping. It's also the basic unit of replica. For instance, if a query node failed, its segment groups will be redistributed accross other nodes. If a query node is overloaded, part of its segment groups will be migrated to underloaded ones. If a hot collection/partition is detected, its segment groups will be replicated to smooth the system load skewness.
'Segment' is the finest unit of data organization. It is where the data and indexes are actually kept. Each segment contains a set of rows. In order to reduce the memory footprint during a query execution and to fully utilize SIMD, the physical data layout within segments is organized in a column-based manner.
1.3 Architecture Overview

The main components, proxy, WAL, query node and write node can scale to multiple instances. These components scale seperately for better tradeoff between availability and cost.
The WAL forms a hash ring. Requests (i.e. inserts and deletes) from clients will be repacked by proxy. Operations shared identical hash value (the hash value of primary key) will be routed to the same hash bucket. In addtion, some preprocessing work will be done by proxy, such as static validity checking, primary key assignment (if not given by user), timestamp assignment.
The query/write nodes are linked to the hash ring, with each node covers some portion of the buckets. Once the hash function and bucket coverage are settled, the chain 'proxy -> WAL -> query/write node' will act as a producer-consumer pipeline. Logs in each bucket is a determined operation stream. Via performing the operation stream in order, the query nodes keep themselves up to date.
The query nodes hold all the indexes in memory. Since building index is time-consuming, the query nodes will dump their index to disk (store engine) for fast failure recovery and cross node index copy.
The write nodes are stateless. They simply transforms the newly arrived WALs to binlog format, then append the binlog to store enginey.
Note that not all the components are necessarily replicated. The system provides failure tolerance by maintaining multiple copies of WAL and binlog. When there is no in-memory index replica and there occurs a query node failure, other query nodes will take over its indexes by loading the dumped index files, or rebuilding them from binlog and WALs. The links from query nodes to the hash ring will also be adjusted such that the failure node's input WAL stream can be properly handled by its neighbors.
1.4 State Synchronization

Data in Milvus have three different forms, namely WAL, binlog, and index. As mentioned in the previous section, WAL can be viewed as a determined operation stream. Other two data forms keep themselves up to date by performing the operation stream in time order.
Each of the WAL is attached with a timestamp, which is the time when the log is sent to the hash bucket. Binlog records, table rows, index cells will also keep that timestamp. In this way, different data forms can offer consistent snapshot for a given time T. For example, requests such as "fetch binlogs before T for point-in-time recovery", "get the row with primary key K at time T", "launch a similarity search at time T for vector V" perform on binlog, index respectively. Though different data forms these three requests are performed, they observe identical snapshot, namely all the state changes before T.
For better throughput, Milvus allows asynchronous state synchronization between WAL and index/binlog/table. Whenever the data is not fresh enough to satisfiy a query, the query will be suspended until the data is up-to-date, or timeout will be returned.
2. Schema
2.1 Collection Schema
type CollectionSchema struct {
Name string
Description string
AutoId bool
Fields []FieldSchema
}
2.2 Field Schema
type FieldSchema struct {
Name string
Description string
DataType DataType
TypeParams map[string]string
IndexParams map[string]string
}
2.2.1 Data Types
2.2.2 Type Params
2.2.3 Index Params
3. Request
In this section, we introduce the RPCs of milvus service. A brief description of the RPCs is listed as follows.
| RPC | description |
|---|---|
| CreateCollection | create a collection base on schema statement |
| DropCollection | drop a collection |
| HasCollection | whether or not a collection exists |
| DescribeCollection | show a collection's schema and its descriptive statistics |
| ShowCollections | list all collections |
| CreatePartition | create a partition |
| DropPartition | drop a partition |
| HasPartition | whether or not a partition exists |
| DescribePartition | show a partition's name and its descriptive statistics |
| ShowPartitions | list a collection's all partitions |
| Insert | insert a batch of rows into a collection or a partition |
| Search | query the columns of a collection or a partition with ANNS statements and boolean expressions |
3.1 Definition Requests
3.2.1 Collection
- CreateCollection
- DropCollection
- HasCollection
- DescribeCollection
- ShowCollections
3.2.2 Partition
- CreatePartition
- DropPartition
- HasPartition
- DescribePartition
- ShowPartitions
3.2 Manipulation Requsts
3.2.1 Insert
- Insert
3.2.2 Delete
- DeleteByID
3.3 Query
4. Time
4.1 Timestamp
Before we discuss timestamp, let's take a brief review of Hybrid Logical Clock (HLC). HLC uses 64bits timestamps which are composed of a 46-bits physical component (thought of as and always close to local wall time) and a 18-bits logical component (used to distinguish between events with the same physical component).

HLC's logical part is advanced on each request. The phsical part can be increased in two cases:
A. when the local wall time is greater than HLC's physical part,
B. or the logical part overflows.
In either cases, the physical part will be updated, and the logical part will be set to 0.
Keep the physical part close to local wall time may face non-monotonic problems such as updates to POSIX time that could turn time backward. HLC avoids such problems, since if 'local wall time < HLC's physical part' holds, only case B is satisfied, thus montonicity is guaranteed.
Milvus does not support transaction, but it should gurantee the deterministic execution of the multi-way WAL. The timestamp attached to each request should
- have its physical part close to wall time (has an acceptable bounded error, a.k.a. uncertainty interval in transaction senarios),
- and be globally unique.
HLC leverages on physical clocks at nodes that are synchronized using the NTP. NTP usually maintain time to within tens of milliseconds over local networks in datacenter. Asymmetric routes and network congestion occasionally cause errors of hundreds of milliseconds. Both the normal time error and the spike are acceptable for Milvus use cases.
The interface of Timestamp is as follows.
type timestamp struct {
physical uint64 // 18-63 bits
logical uint64 // 0-17 bits
}
type Timestamp uint64
4.2 Timestamp Oracle
type timestampOracle struct {
client *etcd.Client // client of a reliable meta service, i.e. etcd client
rootPath string // this timestampOracle's working root path on the reliable kv service
saveInterval uint64
lastSavedTime uint64
tso Timestamp // monotonically increasing timestamp
}
func (tso *timestampOracle) GetTimestamp(count uint32) ([]Timestamp, error)
func (tso *timestampOracle) saveTimestamp() error
func (tso *timestampOracle) loadTimestamp() error
4.2 Timestamp Allocator
type TimestampAllocator struct {}
func (allocator *TimestampAllocator) Start() error
func (allocator *TimestampAllocator) Close() error
func (allocator *TimestampAllocator) Alloc(count uint32) ([]Timestamp, error)
func NewTimestampAllocator() *TimestampAllocator
4.2.1 Batch Allocation of Timestamps
4.2.2 Expiration of Timestamps
4.5 T_safe
5. Basic Components
5.1 Watchdog
type ActiveComponent interface {
Id() string
Status() Status
Clean() Status
Restart() Status
}
type ComponentHeartbeat interface {
Id() string
Status() Status
Serialize() string
}
type Watchdog struct {
targets [] *ActiveComponent
heartbeats ComponentHeartbeat chan
}
// register ActiveComponent
func (dog *Watchdog) Register(target *ActiveComponent)
// called by ActiveComponents
func (dog *Watchdog) PutHeartbeat(heartbeat *ComponentHeartbeat)
// dump heatbeats as log stream
func (dog *Watchdog) dumpHeartbeat(heartbeat *ComponentHeartbeat)
5.2 Global Parameter Table
type GlobalParamsTable struct {
params memoryKV
}
func (gparams *GlobalParamsTable) Save(key, value string) error
func (gparams *GlobalParamsTable) Load(key string) (string, error)
func (gparams *GlobalParamsTable) LoadRange(key, endKey string, limit int) ([]string, []string, error)
func (gparams *GlobalParamsTable) Remove(key string) error
func (gparams *GlobalParamsTable) LoadYaml(filePath string) error
- LoadYaml(filePath string) turns a YAML file into multiple key-value pairs. For example, given the following YAML
etcd:
address: localhost
port: 12379
rootpath: milvus/etcd
GlobalParamsTable.LoadYaml will insert three key-value pairs into params
"etcd.address" -> "localhost"
"etcd.port" -> "12379"
"etcd.rootpath" -> "milvus/etcd"
5.3 Message Stream
type MsgType uint32
const {
kInsert MsgType = 400
kDelete MsgType = 401
kSearch MsgType = 500
KSearchResult MsgType = 1000
kSegStatistics MsgType = 1100
kTimeTick MsgType = 1200
kTimeSync MsgType = 1201
}
type TsMsg interface {
SetTs(ts Timestamp)
BeginTs() Timestamp
EndTs() Timestamp
Type() MsgType
}
type MsgPack struct {
BeginTs Timestamp
EndTs Timestamp
Msgs []*TsMsg
}
type TsMsgMarshaler interface {
Marshal(input *TsMsg) ([]byte, error)
Unmarshal(input []byte) (*TsMsg, error)
}
type MsgStream interface {
SetMsgMarshaler(marshal *TsMsgMarshaler, unmarshal *TsMsgMarshaler)
Produce(*MsgPack) error
Broadcast(*MsgPack) error
Consume() *MsgPack // message can be consumed exactly once
}
type RepackFunc(msgs []* TsMsg, hashKeys [][]int32) map[int32] *MsgPack
type PulsarMsgStream struct {
client *pulsar.Client
repackFunc RepackFunc
inputs []*pulsar.Producer
msgUnmarshaler []*TsMsgMarshaler
outputs []*pulsar.Consumer
msgMarshaler []*TsMsgMarshaler
}
func (ms *PulsarMsgStream) AddInputTopics(topics []string, unmarshal *TsMsgMarshaler)
func (ms *PulsarMsgStream) AddOutputTopics(topics []string, marshal *TsMsgMarshaler)
func (ms *PulsarMsgStream) SetRepackFunc(repackFunc RepackFunc)
func (ms *PulsarMsgStream) Produce(msgs *MsgPack) error
func (ms *PulsarMsgStream) Broadcast(msgs *MsgPack) error
func (ms *PulsarMsgStream) Consume() (*MsgPack, error)
type PulsarTtMsgStream struct {
client *pulsar.Client
repackFunc RepackFunc
producers []*pulsar.Producer
consumers []*pulsar.Consumer
msgMarshaler *TsMsgMarshaler
msgUnmarshaler *TsMsgMarshaler
inputBuf []*TsMsg
unsolvedBuf []*TsMsg
msgPacks []*MsgPack
}
func (ms *PulsarTtMsgStream) SetProducers(channels []string)
func (ms *PulsarTtMsgStream) SetConsumers(channels []string)
func (ms *PulsarTtMsgStream) SetMsgMarshaler(marshal *TsMsgMarshaler, unmarshal *TsMsgMarshaler)
func (ms *PulsarTtMsgStream) SetRepackFunc(repackFunc RepackFunc)
func (ms *PulsarTtMsgStream) Produce(msgs *MsgPack) error
func (ms *PulsarTtMsgStream) Broadcast(msgs *MsgPack) error
func (ms *PulsarTtMsgStream) Consume() *MsgPack //return messages in one time tick
5.4 Time Ticked Flow Graph
5.4.1 Flow Graph States
type flowGraphStates struct {
startTick Timestamp
numActiveTasks map[string]int32
numCompletedTasks map[string]int64
}
5.4.2 Message
type Msg interface {
TimeTick() Timestamp
SkipThisTick() bool
DownStreamNodeIdx() int32
}
type SkipTickMsg struct {}
func (msg *SkipTickMsg) SkipThisTick() bool // always return true
5.4.3 Node
type Node interface {
Name() string
MaxQueueLength() int32
MaxParallelism() int32
SetPipelineStates(states *flowGraphStates)
Operate([]*Msg) []*Msg
}
type baseNode struct {
Name string
maxQueueLength int32
maxParallelism int32
graphStates *flowGraphStates
}
func (node *baseNode) MaxQueueLength() int32
func (node *baseNode) MaxParallelism() int32
func (node *baseNode) SetMaxQueueLength(n int32)
func (node *baseNode) SetMaxParallelism(n int32)
func (node *baseNode) SetPipelineStates(states *flowGraphStates)
5.4.4 Flow Graph
type nodeCtx struct {
node *Node
inputChans [](*chan *Msg)
outputChans [](*chan *Msg)
inputMsgs [](*Msg List)
downstreams []*nodeCtx
skippedTick Timestamp
}
func (nodeCtx *nodeCtx) Start(ctx context.Context) error
Start() will enter a loop. In each iteration, it tries to collect input messges from inputChan, then prepare node's input. When input is ready, it will trigger node.Operate. When node.Operate returns, it sends the returned Msg to outputChans, which connects to the downstreams' inputChans.
type TimeTickedFlowGraph struct {
states *flowGraphStates
nodeCtx map[string]*nodeCtx
}
func (*pipeline TimeTickedFlowGraph) AddNode(node *Node)
func (*pipeline TimeTickedFlowGraph) SetEdges(nodeName string, in []string, out []string)
func (*pipeline TimeTickedFlowGraph) Start() error
func (*pipeline TimeTickedFlowGraph) Close() error
func NewTimeTickedFlowGraph(ctx context.Context) *TimeTickedFlowGraph
5.5 ID Allocator
type IdAllocator struct {
}
func (allocator *IdAllocator) Start() error
func (allocator *IdAllocator) Close() error
func (allocator *IdAllocator) Alloc(count uint32) ([]int64, error)
func NewIdAllocator(ctx context.Context) *IdAllocator
5.6 KV
5.6.1 KV Base
type KVBase interface {
Load(key string) (string, error)
MultiLoad(keys []string) ([]string, error)
Save(key, value string) error
MultiSave(kvs map[string]string) error
Remove(key string) error
MultiRemove(keys []string) error
MultiSaveAndRemove(saves map[string]string, removals []string) error
Watch(key string) clientv3.WatchChan
WatchWithPrefix(key string) clientv3.WatchChan
LoadWithPrefix(key string) ( []string, []string, error)
}
- MultiLoad(keys []string) Load multiple kv pairs. Loads are done transactional.
- MultiSave(kvs map[string]string) Save multiple kv pairs. Saves are done transactional.
- MultiRemove(keys []string) Remove multiple kv pairs. Removals are done transactional.
5.6.2 Etcd KV
type EtcdKV struct {
client *clientv3.Client
rootPath string
}
func NewEtcdKV(etcdAddr string, rootPath string) *EtcdKV
EtcdKV implements all KVBase interfaces.
6. Proxy
6.1 Proxy Instance
type Proxy struct {
servicepb.UnimplementedMilvusServiceServer
masterClient mpb.MasterClient
timeTick *timeTick
ttStream *MessageStream
scheduler *taskScheduler
tsAllocator *TimestampAllocator
ReqIdAllocator *IdAllocator
RowIdAllocator *IdAllocator
SegIdAssigner *segIdAssigner
}
func (proxy *Proxy) Start() error
func NewProxy(ctx context.Context) *Proxy
Global Parameter Table
type GlobalParamsTable struct {
}
func (*paramTable GlobalParamsTable) ProxyId() int64
func (*paramTable GlobalParamsTable) ProxyAddress() string
func (*paramTable GlobalParamsTable) MasterAddress() string
func (*paramTable GlobalParamsTable) PulsarAddress() string
func (*paramTable GlobalParamsTable) TimeTickTopic() string
func (*paramTable GlobalParamsTable) InsertTopics() []string
func (*paramTable GlobalParamsTable) QueryTopic() string
func (*paramTable GlobalParamsTable) QueryResultTopics() []string
func (*paramTable GlobalParamsTable) Init() error
var ProxyParamTable GlobalParamsTable
6.2 Task
type task interface {
Id() int64 // return ReqId
PreExecute() error
Execute() error
PostExecute() error
WaitToFinish() error
Notify() error
}
- Base Task
type baseTask struct {
Type ReqType
ReqId int64
Ts Timestamp
ProxyId int64
}
func (task *baseTask) PreExecute() error
func (task *baseTask) Execute() error
func (task *baseTask) PostExecute() error
func (task *baseTask) WaitToFinish() error
func (task *baseTask) Notify() error
-
Insert Task
Take insertTask as an example:
type insertTask struct {
baseTask
SegIdAssigner *segIdAssigner
RowIdAllocator *IdAllocator
rowBatch *RowBatch
}
func (task *InsertTask) Execute() error
func (task *InsertTask) WaitToFinish() error
func (task *InsertTask) Notify() error
6.2 Task Scheduler
- Base Task Queue
type baseTaskQueue struct {
unissuedTasks *List
activeTasks map[int64]*task
utLock sync.Mutex // lock for UnissuedTasks
atLock sync.Mutex // lock for ActiveTasks
}
func (queue *baseTaskQueue) AddUnissuedTask(task *task)
func (queue *baseTaskQueue) FrontUnissuedTask() *task
func (queue *baseTaskQueue) PopUnissuedTask(id int64) *task
func (queue *baseTaskQueue) AddActiveTask(task *task)
func (queue *baseTaskQueue) PopActiveTask(id int64) *task
func (queue *baseTaskQueue) TaskDoneTest(ts Timestamp) bool
AddUnissuedTask(task *task) will put a new task into unissuedTasks, while maintaining the list by timestamp order.
TaskDoneTest(ts Timestamp) will check both unissuedTasks and unissuedTasks. If no task found before ts, then the function returns true, indicates that all the tasks before ts are completed.
- Data Definition Task Queue
type ddTaskQueue struct {
baseTaskQueue
lock sync.Mutex
}
func (queue *ddTaskQueue) Enqueue(task *task) error
func newDdTaskQueue() *ddTaskQueue
Data definition tasks (i.e. CreateCollectionTask) will be put into DdTaskQueue. If a task is enqueued, Enqueue(task *task) will set Ts, ReqId, ProxyId, then push it into queue. The timestamps of the enqueued tasks should be strictly monotonically increasing. As Enqueue(task *task) will be called in parallel, setting timestamp and queue insertion need to be done atomically.
- Data Manipulation Task Queue
type dmTaskQueue struct {
baseTaskQueue
}
func (queue *dmTaskQueue) Enqueue(task *task) error
func newDmTaskQueue() *dmTaskQueue
Insert tasks and delete tasks will be put into DmTaskQueue.
If a insertTask is enqueued, Enqueue(task *task) will set Ts, ReqId, ProxyId, SegIdAssigner, RowIdAllocator, then push it into queue. The SegIdAssigner and RowIdAllocator will later be used in the task's execution phase.
- Data Query Task Queue
type dqTaskQueue struct {
baseTaskQueue
}
func (queue *dqTaskQueue) Enqueue(task *task) error
func newDqTaskQueue() *dqTaskQueue
Queries will be put into DqTaskQueue.
- Task Scheduler
type taskScheduler struct {
DdQueue *ddTaskQueue
DmQueue *dmTaskQueue
DqQueue *dqTaskQueue
tsAllocator *TimestampAllocator
ReqIdAllocator *IdAllocator
}
func (sched *taskScheduler) scheduleDdTask() *task
func (sched *taskScheduler) scheduleDmTask() *task
func (sched *taskScheduler) scheduleDqTask() *task
func (sched *taskScheduler) Start() error
func (sched *taskScheduler) TaskDoneTest(ts Timestamp) bool
func newTaskScheduler(ctx context.Context, tsAllocator *TimestampAllocator, ReqIdAllocator *IdAllocator) *taskScheduler
scheduleDdTask() selects tasks in a FIFO manner, thus time order is garanteed.
The policy of scheduleDmTask() should target on throughput, not tasks' time order. Note that the time order of the tasks' execution will later be garanteed by the timestamp & time tick mechanism.
The policy of scheduleDqTask() should target on throughput. It should also take visibility into consideration. For example, if an insert task and a query arrive in a same time tick and the query comes after insert, the query should be scheduled in the next tick thus the query can see the insert.
TaskDoneTest(ts Timestamp) will check all the three task queues. If no task found before ts, then the function returns true, indicates that all the tasks before ts are completed.
- Statistics
// ActiveComponent interfaces
func (sched *taskScheduler) Id() String
func (sched *taskScheduler) Status() Status
func (sched *taskScheduler) Clean() Status
func (sched *taskScheduler) Restart() Status
func (sched *taskScheduler) heartbeat()
// protobuf
message taskSchedulerHeartbeat {
string id
uint64 dd_queue_length
uint64 dm_queue_length
uint64 dq_queue_length
uint64 num_dd_done
uint64 num_dm_done
uint64 num_dq_done
}
6.3 Time Tick
- Time Tick
type timeTick struct {
lastTick Timestamp
currentTick Timestamp
wallTick Timestamp
tickStep Timestamp
syncInterval Timestamp
tsAllocator *TimestampAllocator
scheduler *taskScheduler
ttStream *MessageStream
ctx context.Context
}
func (tt *timeTick) Start() error
func (tt *timeTick) synchronize() error
func newTimeTick(ctx context.Context, tickStep Timestamp, syncInterval Timestamp, tsAllocator *TimestampAllocator, scheduler *taskScheduler, ttStream *MessageStream) *timeTick
Start() will enter a loop. On each tickStep, it tries to send a TIME_TICK typed TsMsg into ttStream. After each syncInterval, it sychronizes its wallTick with tsAllocator by calling synchronize(). When currentTick + tickStep < wallTick holds, it will update currentTick with wallTick on next tick. Otherwise, it will update currentTick with currentTick + tickStep.
- Statistics
// ActiveComponent interfaces
func (tt *timeTick) ID() String
func (tt *timeTick) Status() Status
func (tt *timeTick) Clean() Status
func (tt *timeTick) Restart() Status
func (tt *timeTick) heartbeat()
// protobuf
message TimeTickHeartbeat {
string id
uint64 last_tick
}
8. Query Node
8.1 Collection and Segment Meta
8.1.1 Collection
type Collection struct {
Name string
Id uint64
Fields map[string]FieldMeta
SegmentsId []uint64
cCollectionSchema C.CCollectionSchema
}
8.1.2 Field Meta
type FieldMeta struct {
Name string
Id uint64
IsPrimaryKey bool
TypeParams map[string]string
IndexParams map[string]string
}
8.1.3 Segment
type Segment struct {
Id uint64
ParitionName string
CollectionId uint64
OpenTime Timestamp
CloseTime Timestamp
NumRows uint64
cSegment C.CSegmentBase
}
8.2 Message Streams
type ManipulationReqUnmarshaler struct {}
// implementations of MsgUnmarshaler interfaces
func (unmarshaler *InsertMsgUnmarshaler) Unmarshal(input *pulsar.Message) (*TsMsg, error)
type QueryReqUnmarshaler struct {}
// implementations of MsgUnmarshaler interfaces
func (unmarshaler *QueryReqUnmarshaler) Unmarshal(input *pulsar.Message) (*TsMsg, error)
8.3 Query Node
4. Storage Engine
4.X Interfaces
10. Master
10.1 Interfaces (RPC)
| RPC | description |
|---|---|
| CreateCollection | create a collection base on schema statement |
| DropCollection | drop a collection |
| HasCollection | whether or not a collection exists |
| DescribeCollection | show a collection's schema and its descriptive statistics |
| ShowCollections | list all collections |
| CreatePartition | create a partition |
| DropPartition | drop a partition |
| HasPartition | whether or not a partition exists |
| DescribePartition | show a partition's name and its descriptive statistics |
| ShowPartitions | list a collection's all partitions |
| AllocTimestamp | allocate a batch of consecutive timestamps |
| AllocId | allocate a batch of consecutive IDs |
| AssignSegmentId | assign segment id to insert rows (master determines which segment these rows belong to) |
10.2 Master Instance
type Master interface {
tso timestampOracle // timestamp oracle
ddScheduler ddRequestScheduler // data definition request scheduler
metaTable metaTable // in-memory system meta
collManager collectionManager // collection & partition manager
segManager segmentManager // segment manager
}
- Timestamp allocation
Master serves as a centrol clock of the whole system. Other components (i.e. Proxy) allocates timestamps from master via RPC AllocTimestamp. All the timestamp allocation requests will be handled by the timestampOracle singleton. See section 4.2 for the details about timestampOracle.
-
Request Scheduling
-
System Meta
-
Collection Management
-
Segment Management
10.3 Data definition Request Scheduler
10.2.1 Task
Master receives data definition requests via grpc. Each request (described by a proto) will be wrapped as a task for further scheduling. The task interface is
type task interface {
Type() ReqType
Ts() Timestamp
Execute() error
WaitToFinish() error
Notify() error
}
A task example is as follows. In this example, we wrap a CreateCollectionRequest (a proto) as a createCollectionTask. The wrapper need to contain task interfaces.
type createCollectionTask struct {
req *CreateCollectionRequest
cv int chan
}
// Task interfaces
func (task *createCollectionTask) Type() ReqType
func (task *createCollectionTask) Ts() Timestamp
func (task *createCollectionTask) Execute() error
func (task *createCollectionTask) Notify() error
func (task *createCollectionTask) WaitToFinish() error
10.2.2 Scheduler
type ddRequestScheduler struct {
reqQueue *task chan
}
func (rs *ddRequestScheduler) Enqueue(task *task) error
func (rs *ddRequestScheduler) schedule() *task // implement scheduling policy
10.4 Meta Table
10.4.1 Meta
- Tenant Meta
message TenantMeta {
uint64 id = 1;
uint64 num_query_nodes = 2;
repeated string insert_channel_ids = 3;
string query_channel_id = 4;
}
- Proxy Meta
message ProxyMeta {
uint64 id = 1;
common.Address address = 2;
repeated string result_channel_ids = 3;
}
- Collection Meta
message CollectionMeta {
uint64 id=1;
schema.CollectionSchema schema=2;
uint64 create_time=3;
repeated uint64 segment_ids=4;
repeated string partition_tags=5;
}
- Segment Meta
message SegmentMeta {
uint64 segment_id=1;
uint64 collection_id =2;
string partition_tag=3;
int32 channel_start=4;
int32 channel_end=5;
uint64 open_time=6;
uint64 close_time=7;
int64 num_rows=8;
}
10.4.2 KV pairs in EtcdKV
tenantId string -> tenantMeta string
proxyId string -> proxyMeta string
collectionId string -> collectionMeta string
segmentId string -> segmentMeta string
Note that tenantId, proxyId, collectionId, segmentId are unique strings converted from int64.
tenantMeta, proxyMeta, collectionMeta, segmentMeta are serialized protos.
10.4.3 Meta Table
type metaTable struct {
kv kv.Base // client of a reliable kv service, i.e. etcd client
tenantId2Meta map[UniqueId]TenantMeta // tenant id to tenant meta
proxyId2Meta map[UniqueId]ProxyMeta // proxy id to proxy meta
collId2Meta map[UniqueId]CollectionMeta // collection id to collection meta
collName2Id map[string]UniqueId // collection name to collection id
segId2Meta map[UniqueId]SegmentMeta // segment id to segment meta
tenantLock sync.RWMutex
proxyLock sync.RWMutex
ddLock sync.RWMutex
}
func (meta *metaTable) AddTenant(tenant *TenantMeta) error
func (meta *metaTable) DeleteTenant(tenantId UniqueId) error
func (meta *metaTable) AddProxy(proxy *ProxyMeta) error
func (meta *metaTable) DeleteProxy(proxyId UniqueId) error
func (meta *metaTable) AddCollection(coll *CollectionMeta) error
func (meta *metaTable) DeleteCollection(collId UniqueId) error
func (meta *metaTable) HasCollection(collId UniqueId) bool
func (meta *metaTable) GetCollectionByName(collName string) (*CollectionMeta, error)
func (meta *metaTable) AddPartition(collId UniqueId, tag string) error
func (meta *metaTable) HasPartition(collId UniqueId, tag string) bool
func (meta *metaTable) DeletePartition(collId UniqueId, tag string) error
func (meta *metaTable) AddSegment(seg *SegmentMeta) error
func (meta *metaTable) GetSegmentById(segId UniqueId)(*SegmentMeta, error)
func (meta *metaTable) DeleteSegment(segId UniqueId) error
func (meta *metaTable) CloseSegment(segId UniqueId, closeTs Timestamp, num_rows int64) error
func NewMetaTable(kv kv.Base) (*metaTable,error)
metaTable maintains meta both in memory and etcdKV. It keeps meta's consistency in both sides. All its member functions may be called concurrently.
- AddSegment(seg *SegmentMeta) first update CollectionMeta by adding the segment id, then it adds a new SegmentMeta to kv. All the modifications are done transactionally.
10.5 System Time Synchronization
10.5.1 Time Tick Barrier
- Soft Time Tick Barrier

type softTimeTickBarrier struct {
peer2LastTt map[UniqueId]Timestamp
minTtInterval Timestamp
lastTt Timestamp
outTt chan Timestamp
ttStream *MsgStream
}
func (ttBarrier *softTimeTickBarrier) GetTimeTick() Timestamp
func (ttBarrier *softTimeTickBarrier) Start() error
func newSoftTimeTickBarrier(ctx context.Context, ttStream *MsgStream, peerIds []UniqueId, minTtInterval Timestamp) *softTimeTickBarrier
- Hard Time Tick Barrier

type hardTimeTickBarrier struct {
peer2Tt map[UniqueId]List
outTt chan Timestamp
ttStream *MsgStream
}
func (ttBarrier *hardTimeTickBarrier) GetTimeTick() Timestamp
func (ttBarrier *hardTimeTickBarrier) Start() error
func newHardTimeTickBarrier(ctx context.Context, ttStream *MsgStream, peerIds []UniqueId) *softTimeTickBarrier
10.5.1 Time Synchornization Message Producer
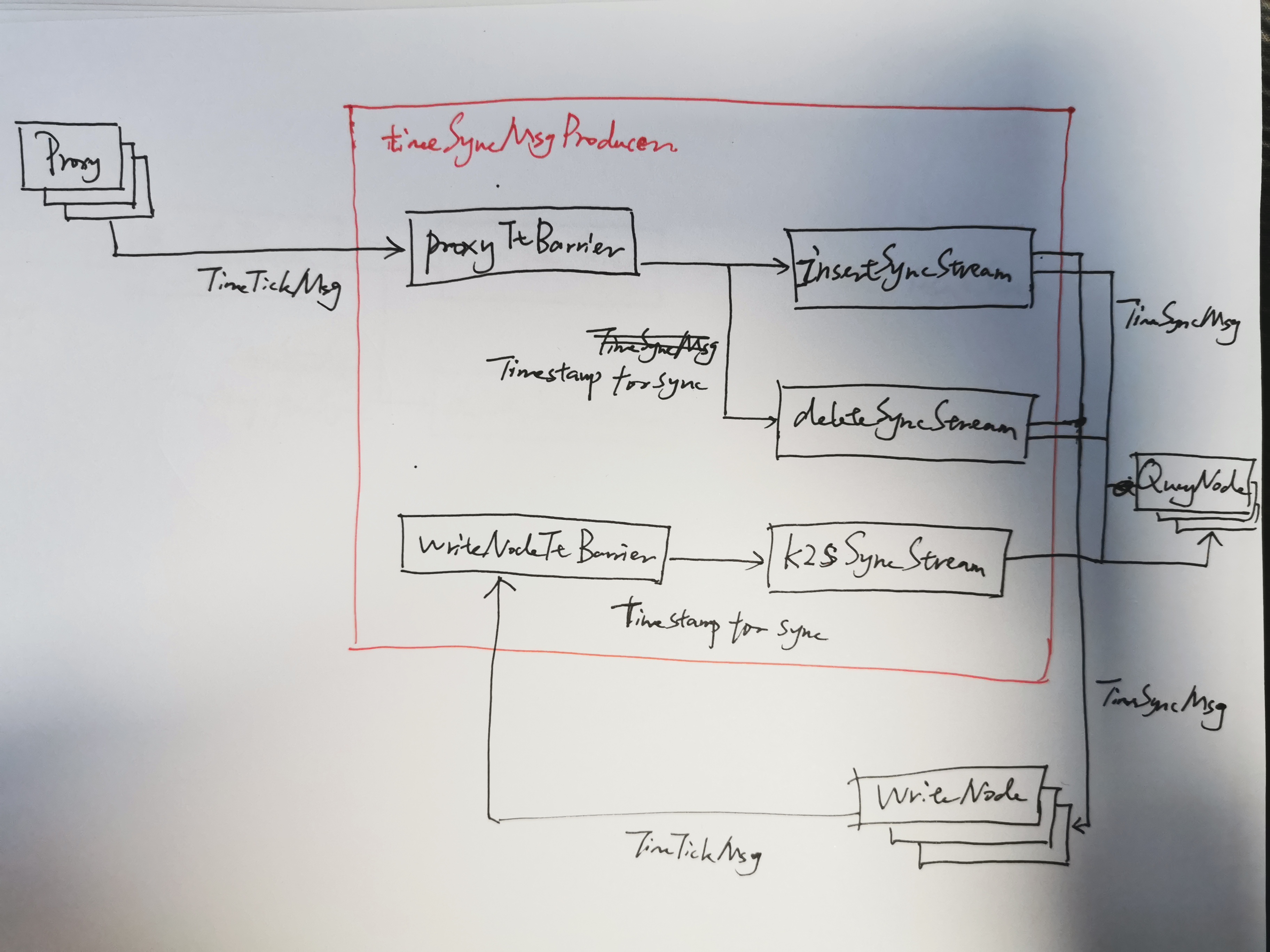
type timeSyncMsgProducer struct {
proxyTtBarrier *softTimeTickBarrier
WriteNodeTtBarrier *hardTimeTickBarrier
insertSyncStream *MsgStream
deleteSyncStream *MsgStream
k2sSyncStream *MsgStream
}
func (syncMsgProducer* timeSyncMsgProducer) SetProxyTtStreams(proxyTt *MsgStream, proxyIds []UniqueId)
func (syncMsgProducer* timeSyncMsgProducer) SetWriteNodeTtStreams(WriteNodeTt *MsgStream, writeNodeIds []UniqueId)
func (syncMsgProducer* timeSyncMsgProducer) SetInsertSyncStream(insertSync *MsgStream)
func (syncMsgProducer* timeSyncMsgProducer) SetDeleteSyncStream(deleteSync *MsgStream)
func (syncMsgProducer* timeSyncMsgProducer) SetK2sSyncStream(k2sSync *MsgStream)
func (syncMsgProducer* timeSyncMsgProducer) Start(ctx context.Context) error
func (syncMsgProducer* timeSyncMsgProducer) Close() error